Download as PDF, PPTX
![Dr. Jim Dowling
CEO / Co-Founder
Logical Clocks
Managed Feature Store
for ML Webinar
[ Presenter ]](https://image.slidesharecdn.com/managedfeaturestorewebinarhopsworks-200528103033/85/Managed-Feature-Store-for-Machine-Learning-1-320.jpg)
![Dr. Jim Dowling
CEO / Co-Founder
Logical Clocks
Managed Feature Store
for ML Webinar
[ Presenter ]](https://image.slidesharecdn.com/managedfeaturestorewebinarhopsworks-200528103033/75/Managed-Feature-Store-for-Machine-Learning-1-2048.jpg)






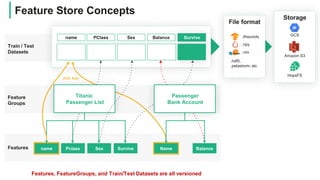

![Create Training Datasets using the Feature Store
from hops import featurestore as fs
sample_data = fs.get_features([“name”, “Pclass”, “Sex”, “Balance”, “Survived”])
fs.create_training_dataset(sample_data, “titanic_training_dataset",
data_format="tfrecords“, training_dataset_version=1)](https://image.slidesharecdn.com/managedfeaturestorewebinarhopsworks-200528103033/85/Managed-Feature-Store-for-Machine-Learning-18-320.jpg)
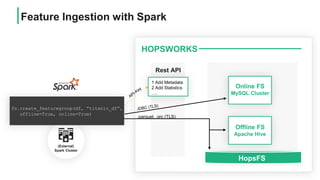
![HOPSWORKS
Offline FS
Apache Hive
HopsFS
Join Features <<TLS>>
Online FS
MySQL Cluster
(External)
Spark Cluster
sample_data = fs.get_features([“name”,
“Pclass”, “Sex”, “Balance”, “Survived”])
Create Training Datasets with (External) Spark
Storage
GCS Amazon S3 HopsFS
.npy, .tfrecords, .csv](https://image.slidesharecdn.com/managedfeaturestorewebinarhopsworks-200528103033/85/Managed-Feature-Store-for-Machine-Learning-19-320.jpg)
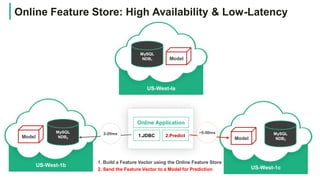
![HOPSWORKS
Rest API
Return JDBC Query
….
Offline FS
Apache Hive
HopsFS
Online FS
MySQL Cluster SELECT .. FROM WHERE … in [keys]
<<TLS>>
getQuery(“model”)
<<API-Key>> Online
Application
Online Feature Store: JDBC API
[keys]
user_id,
session_id,
timestamp, etc
Model
Prediction](https://image.slidesharecdn.com/managedfeaturestorewebinarhopsworks-200528103033/85/Managed-Feature-Store-for-Machine-Learning-22-320.jpg)

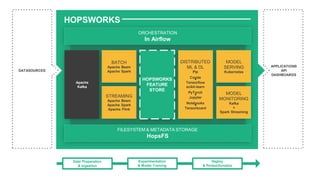
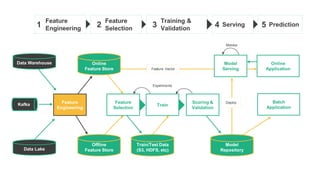
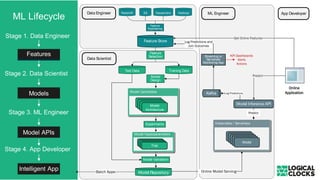
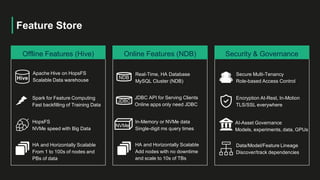


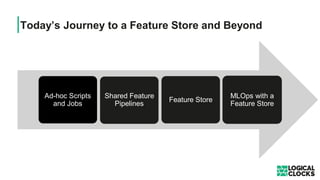
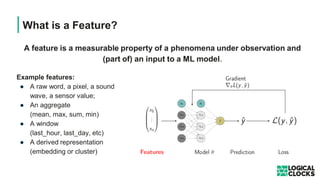
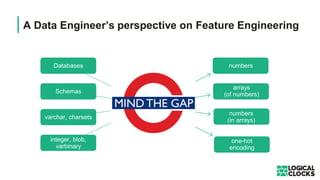
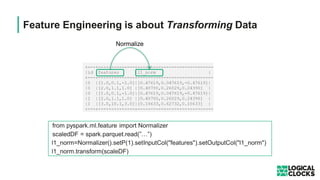
The document outlines a webinar presented by Dr. Jim Dowling and team, detailing the functionalities and applications of Logical Clocks' Hopsworks feature store for machine learning. It explains key concepts of feature engineering, the importance of managing features in both online and offline stores, and provides technical insights into real-time and batch data processing. The platform supports various data formats and integration for streamlined ML workflows and model serving, emphasizing governance, scalability, and accessibility.



































































