Downloaded 14 times








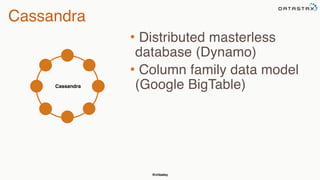
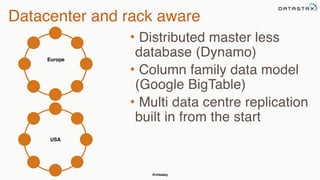
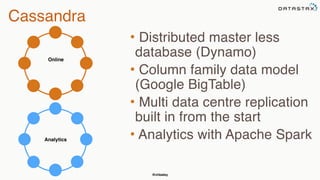



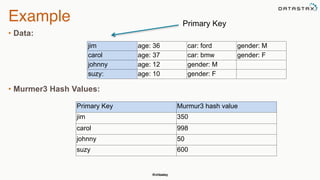
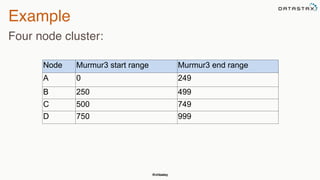
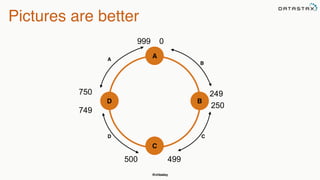
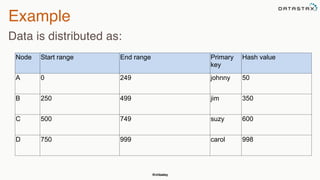


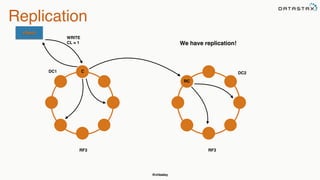


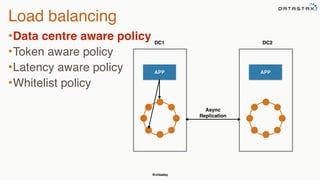

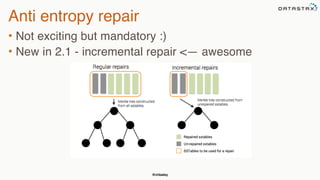



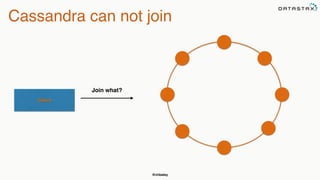

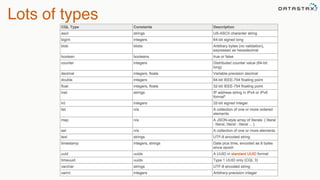








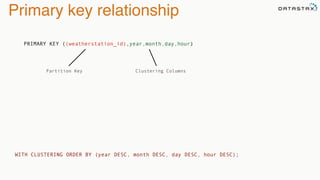
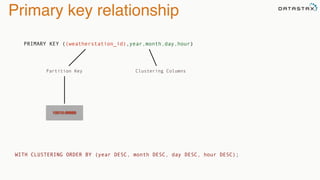
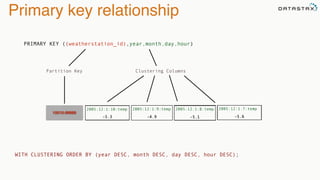
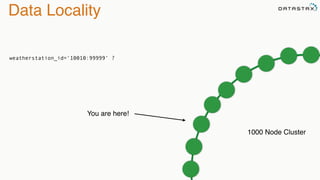
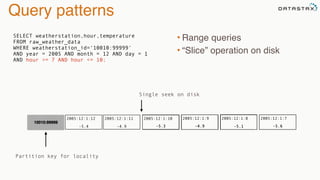
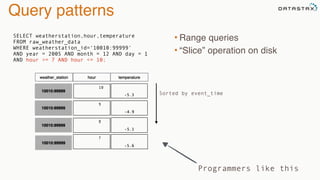

















The document provides an overview of a presentation on Apache Cassandra and Spark. It introduces the speaker and their background with Cassandra. The presentation will cover a recap of Cassandra, replication, fault tolerance, data modeling, and Spark integration. It will also look at a potential use case with KillrWeather. Common Cassandra use cases include ordered data like time series for events, financial transactions, and sensor data.





























































































