Downloaded 144 times
















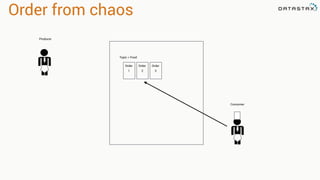





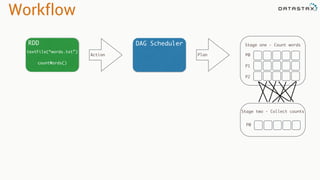
![RDD
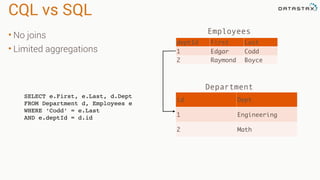
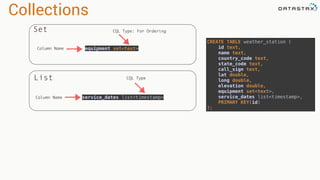
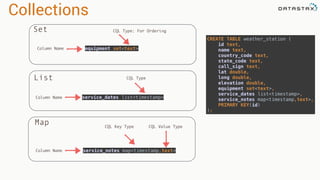
Tranformations
•Produces new RDD
•Calls: filter, flatmap, map,
distinct, groupBy, union, zip,
reduceByKey, subtract
Are
•Immutable
•Partitioned
•Reusable
Actions
•Start cluster computing operations
•Calls: collect: Array[T], count,
fold, reduce..
and Have](https://image.slidesharecdn.com/stratalondon2016tutorial-160525233611/85/An-Introduction-to-time-series-with-Team-Apache-49-320.jpg)









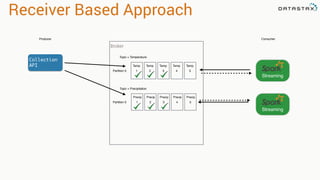
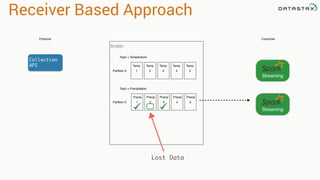
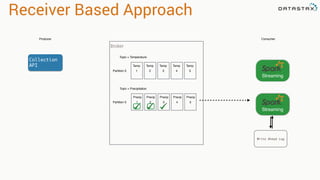
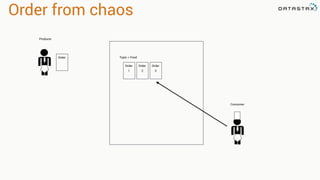
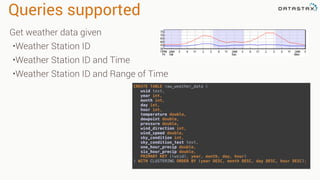
![val kafkaStream = KafkaUtils.createStream(streamingContext,
[ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])
Zookeeper
Server IP
Consumer
Group Created
In Kafka
List of Kafka topics
and number of threads per topic
Receiver Based Approach](https://image.slidesharecdn.com/stratalondon2016tutorial-160525233611/85/An-Introduction-to-time-series-with-Team-Apache-73-320.jpg)
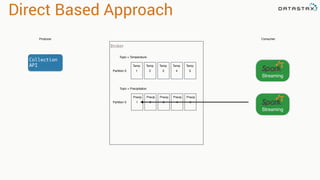
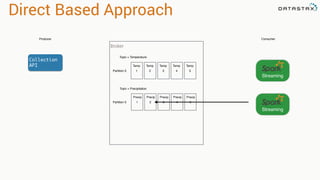
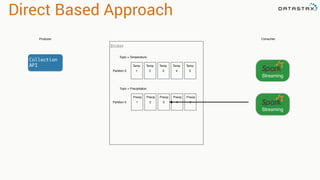
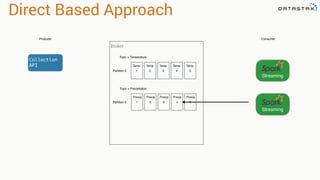
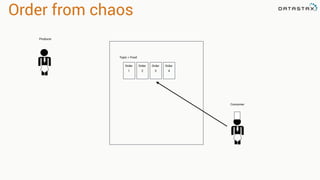
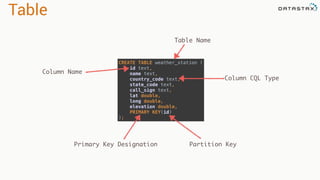
![Direct Based Approach
val directKafkaStream = KafkaUtils.createDirectStream[
[key class], [value class], [key decoder class], [value decoder class] ](
streamingContext, [map of Kafka parameters], [set of topics to consume])
List of Kafka brokers
(and any other params)
Kafka topics](https://image.slidesharecdn.com/stratalondon2016tutorial-160525233611/85/An-Introduction-to-time-series-with-Team-Apache-78-320.jpg)

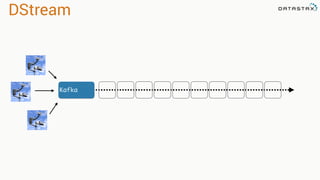
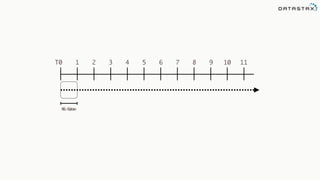
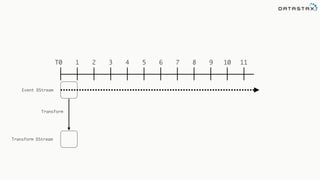
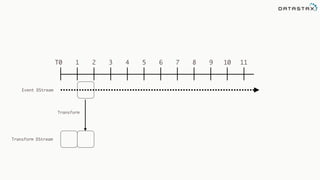
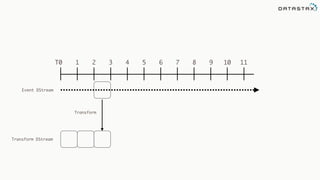
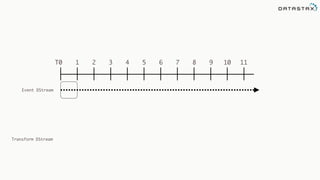
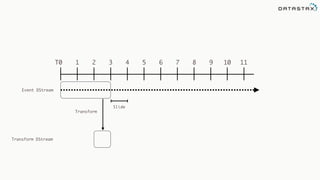
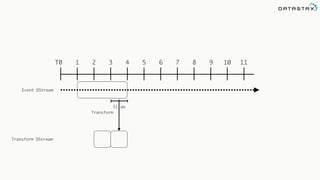
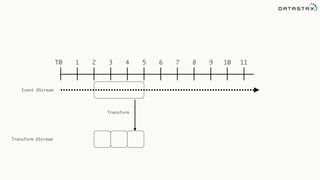































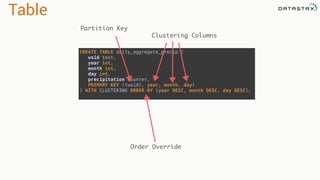
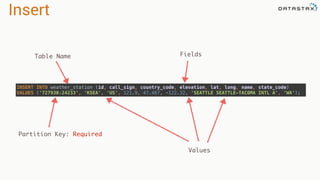


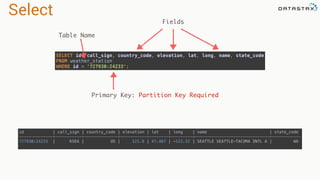
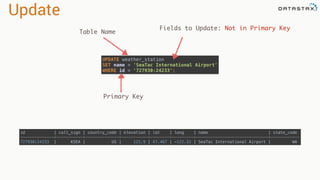

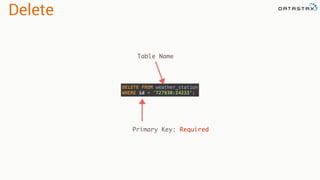






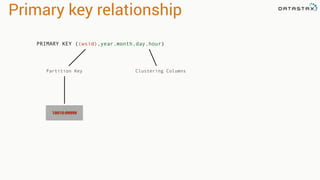
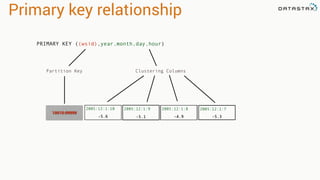

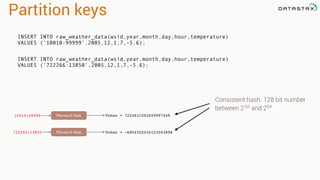
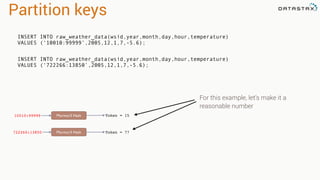

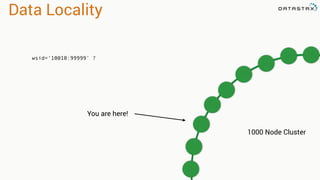

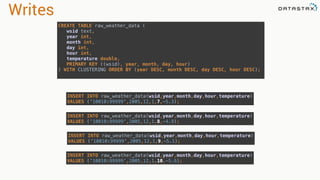
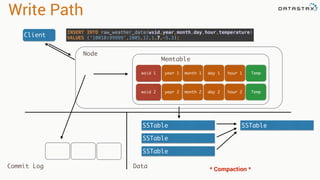






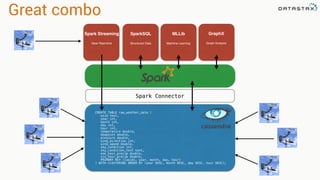
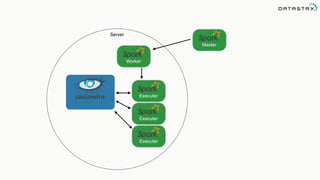
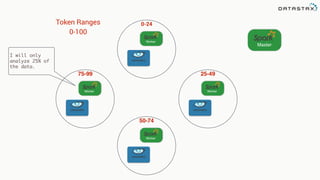
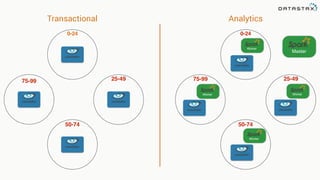
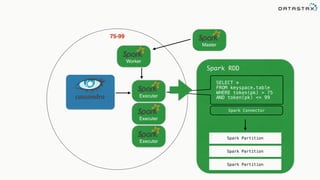
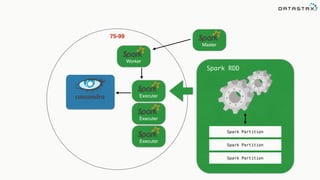




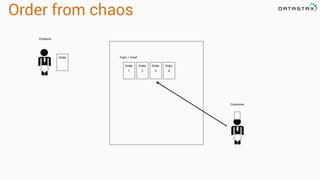
![Attaching to Spark and Cassandra
// Import Cassandra-specific functions on SparkContext and RDD objects
import org.apache.spark.{SparkContext, SparkConf}
import com.datastax.spark.connector._
/** The setMaster("local") lets us run & test the job right in our IDE */
val conf = new SparkConf(true)
.set("spark.cassandra.connection.host", "127.0.0.1")
.setMaster(“local[*]")
.setAppName(getClass.getName)
// Optionally
.set("cassandra.username", "cassandra")
.set("cassandra.password", “cassandra")
val sc = new SparkContext(conf)](https://image.slidesharecdn.com/stratalondon2016tutorial-160525233611/85/An-Introduction-to-time-series-with-Team-Apache-214-320.jpg)

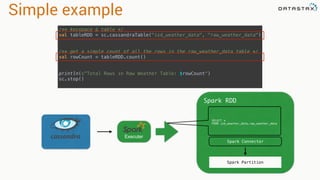
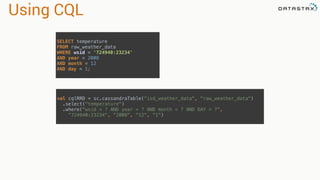

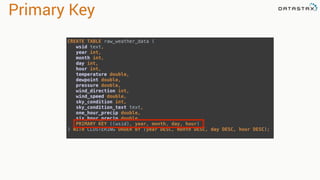
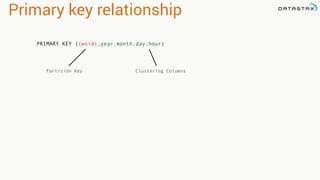
.select("temperature")
.where("wsid = ? AND year = ? AND month = ? AND DAY = ?",
"724940:23234", "2008", "12", "1").spanBy(row => (row.getString("wsid")))
•Specify partition grouping
•Use with large partitions
•Perfect for time series](https://image.slidesharecdn.com/stratalondon2016tutorial-160525233611/85/An-Introduction-to-time-series-with-Team-Apache-221-320.jpg)
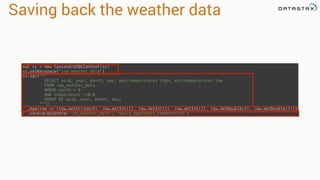

![In the beginning… there was RDD
sc = SparkContext(appName="PythonPi")
partitions = int(sys.argv[1]) if len(sys.argv) > 1 else 2
n = 100000 * partitions
def f(_):
x = random() * 2 - 1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 < 1 else 0
count = sc.parallelize(range(1, n + 1), partitions).
map(f).reduce(add)
print("Pi is roughly %f" % (4.0 * count / n))
sc.stop()](https://image.slidesharecdn.com/stratalondon2016tutorial-160525233611/85/An-Introduction-to-time-series-with-Team-Apache-224-320.jpg)
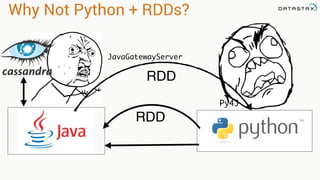
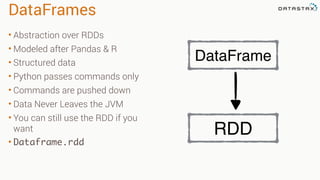



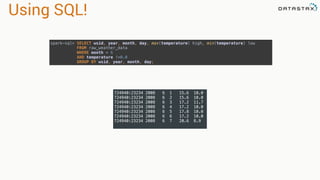
![Filtering
• Select specific rows matching
various patterns
• Fields do not require indexes
• Filtering occurs in memory
• You can use DSE Solr Search
Queries
• Filtering returns a DataFrame
movies.filter(movies.movie_id == 1)
movies[movies.movie_id == 1]
movies.filter("movie_id=1")
movie_id title genres
44 Mortal Kombat (1995)
['Action',
'Adventure',
'Fantasy']
movies.filter("title like '%Kombat%'")](https://image.slidesharecdn.com/stratalondon2016tutorial-160525233611/85/An-Introduction-to-time-series-with-Team-Apache-230-320.jpg)


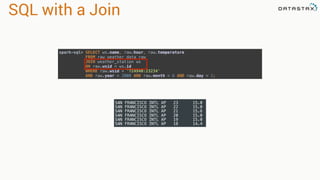
![Joins
• Inner join by default
• Can do various outer joins
as well
• Returns a new DF with all
the columns
ratings.join(movies, "movie_id")
DataFrame[movie_id: int,
user_id: int,
rating: decimal(10,0),
ts: int,
genres: array<string>,
title: string]](https://image.slidesharecdn.com/stratalondon2016tutorial-160525233611/85/An-Introduction-to-time-series-with-Team-Apache-233-320.jpg)




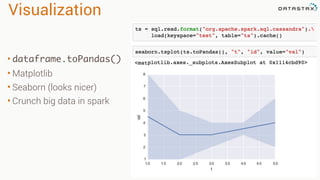
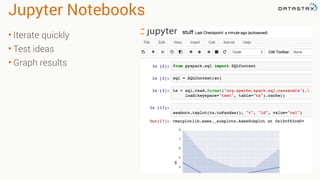


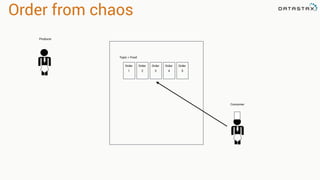
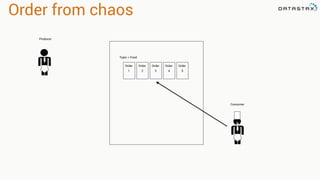
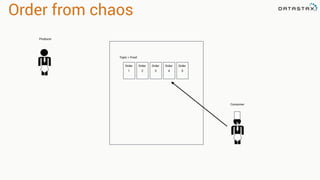
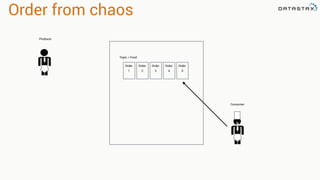
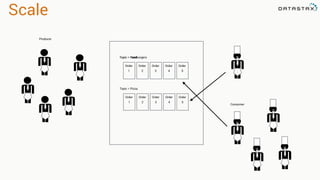
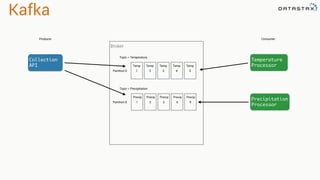
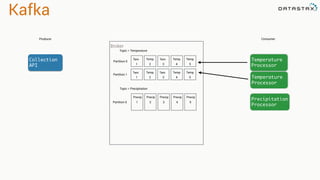
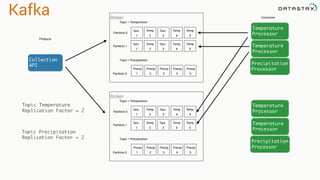
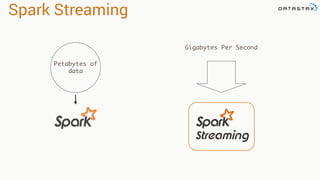
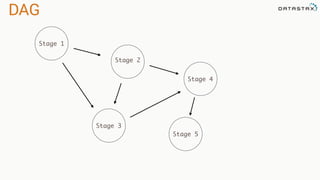
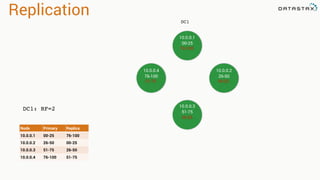
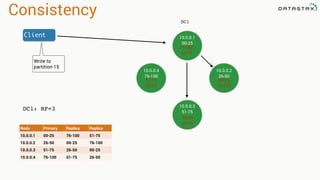
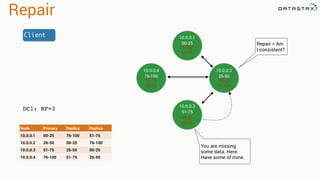
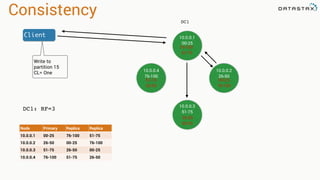
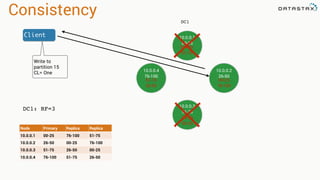
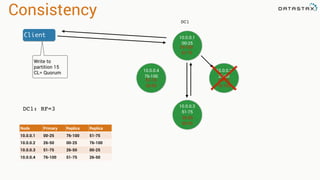
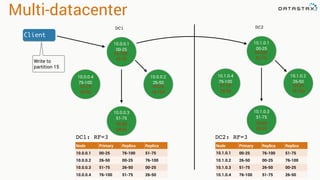
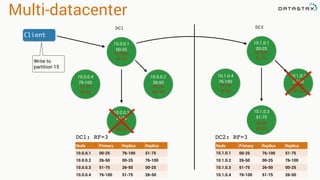
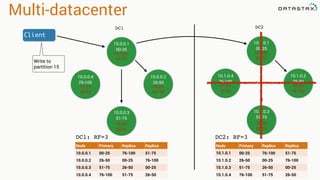
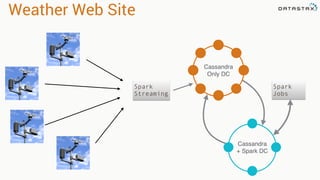
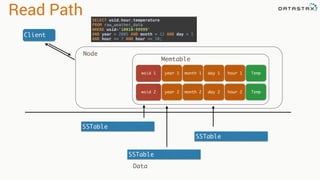
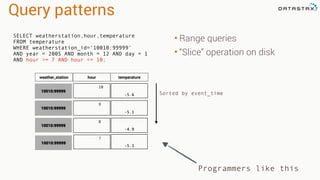
The document presents an agenda, focusing on Apache Kafka, Apache Spark, and Apache Cassandra, highlighting hands-on activities and theoretical concepts relevant to data processing. It discusses time series data and analysis, architectures, and deployment including Kafka's message ordering and durability features. Additionally, it introduces Spark's resilient distributed datasets and its streaming capabilities, alongside Cassandra's basic architecture, data replication, and high availability.






























































































