Download as PDF, PPTX






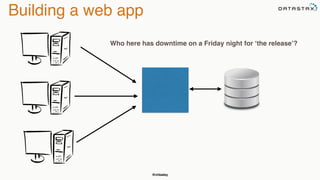
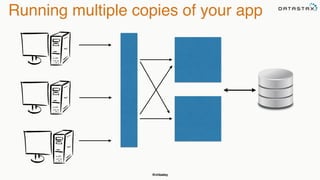
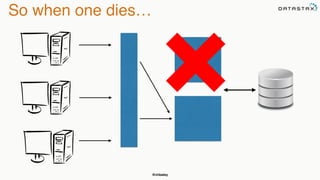

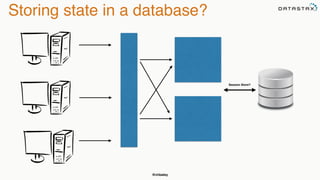

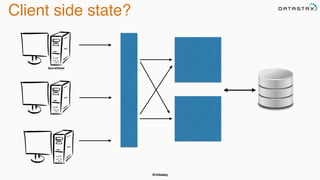

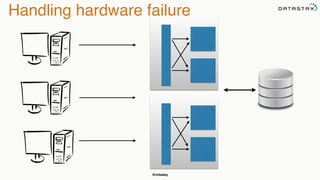
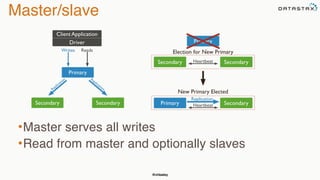
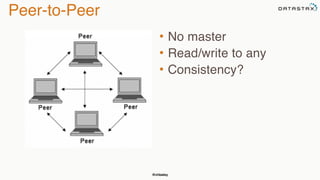
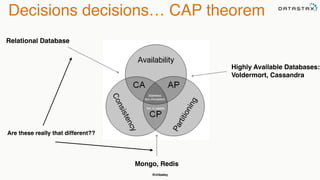


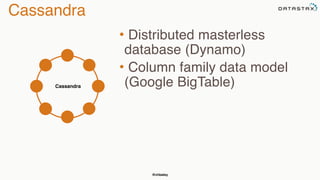
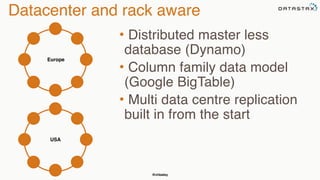
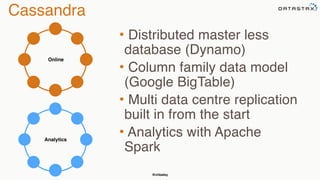





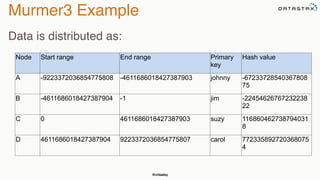

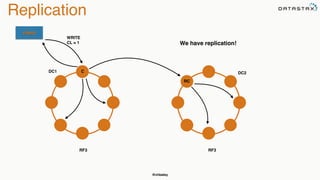


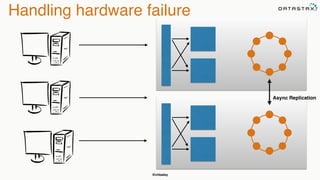
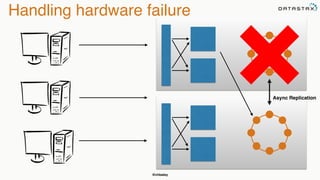
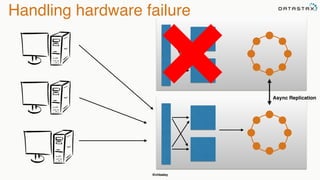
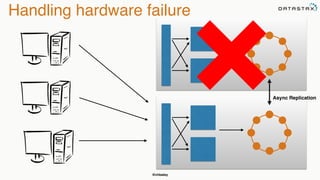
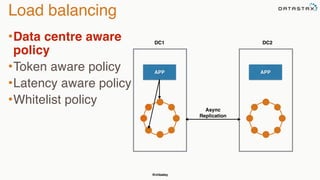

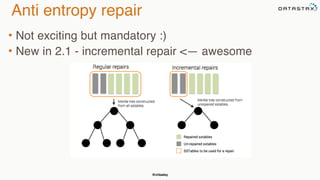




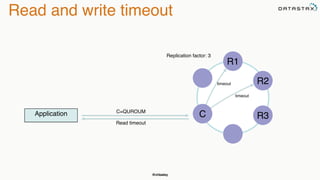
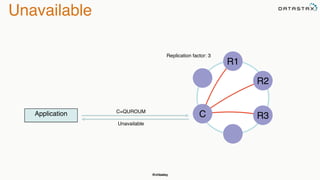
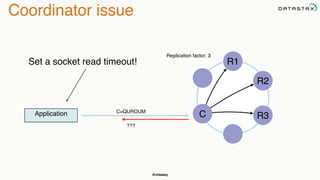

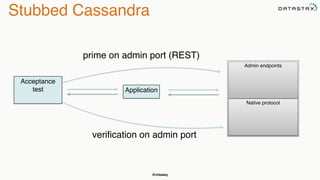




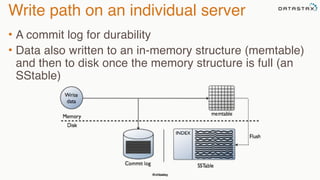


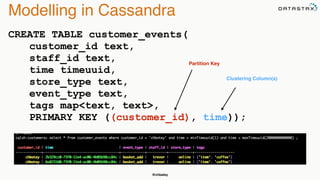













The document discusses building fault tolerant Java applications using Apache Cassandra. It provides an overview of fault tolerance, Cassandra's architecture, failure scenarios, and using the Cassandra Java driver. Examples are given of modeling data in Cassandra and performing common operations like getting all events for a customer or events within a time slice.




















































































