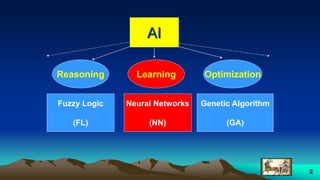
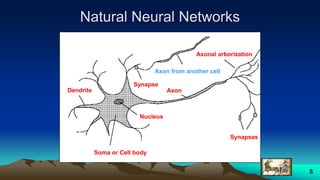
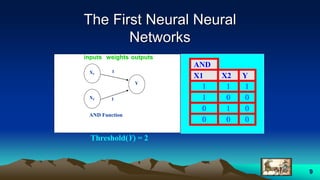
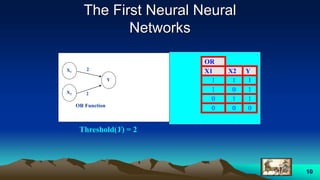
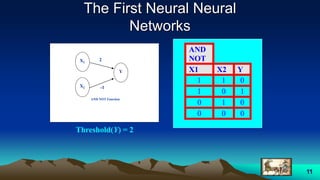
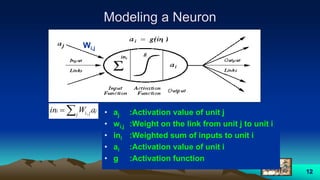
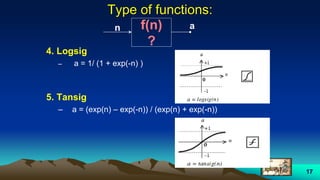
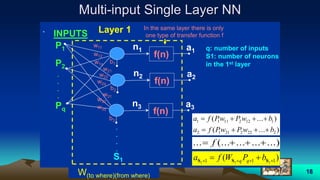
This document provides an overview of neural networks and related topics. It begins with an introduction to neural networks and discusses natural neural networks, early artificial neural networks, modeling neurons, and network design. It then covers multi-layer neural networks, perceptron networks, training, and advantages of neural networks. Additional topics include fuzzy logic, genetic algorithms, clustering, and adaptive neuro-fuzzy inference systems (ANFIS).


















![31
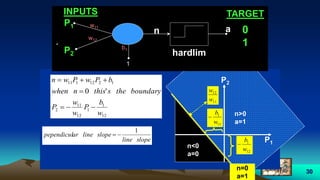
Example 2
• P1 = [2 -2 4 1];
• P2 = [3 -5 6 1];
• Target:
– T= [1 0 1 0];
• We want:
– The Decision line
• Note:
– We must have linearly
separable data
*
*
o
P2
P1
o - 5
- 2 2
3
6
4
*
*o
P2
P1
o
Not linearly
Separable data](https://image.slidesharecdn.com/neuralnetwork-170928130739/85/Neural-network-31-320.jpg)









![41
Example 1
• x = [1 1 2 8 8 9];
• y = [1 2 2 8 9 8];
• axis([0 10 0 10]);
• hold on
• plot (x,y,’ro’);
• data= [x’ y’];
• c= fcm(data,2)%% data , number of groups
• plot (c(:,1), c(:,2), ‘b^’);](https://image.slidesharecdn.com/neuralnetwork-170928130739/85/Neural-network-41-320.jpg)
![42
Example 2
• It is required to make the user to hit points
in x,y plan using ginput
while(1)
[xp,yp]=ginput(1);
• Before that a message box would appear
to ask the user to input how many number
of clustering is required using inputdlg
• Mark the clustering output](https://image.slidesharecdn.com/neuralnetwork-170928130739/85/Neural-network-42-320.jpg)



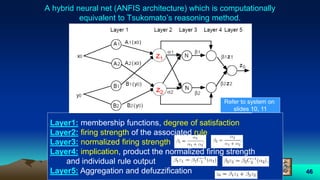







![54
• In anfis we always have single output.
• If we have (MISO) , Example
– Inputs are X, Y which are two vectors 1*n
– Output is Z which is one vector 1*n
The training matrix will be
DataT=[X’ Y’ Z’] which is a matrix n*3](https://image.slidesharecdn.com/neuralnetwork-170928130739/85/Neural-network-54-320.jpg)



![[Capella Day 2019] Model execution and system simulation in Capella](https://cdn.slidesharecdn.com/ss_thumbnails/modelexecutionandsystemsimulationincapellav1-191001130117-thumbnail.jpg?width=640&height=640&fit=bounds)

































































































