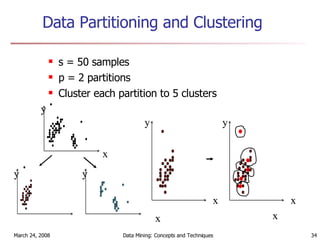
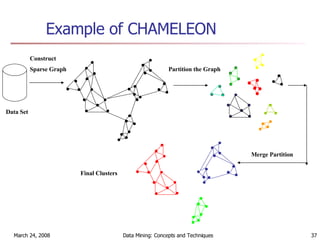
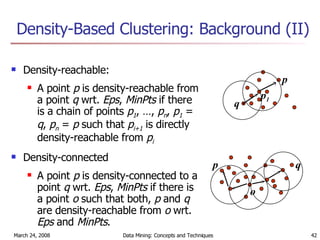
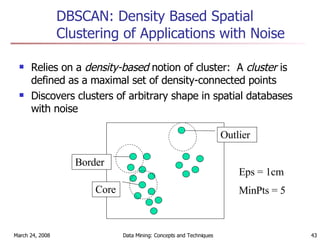
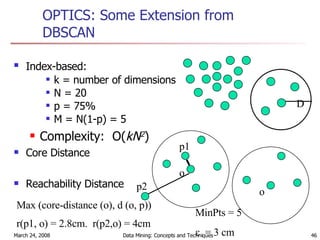
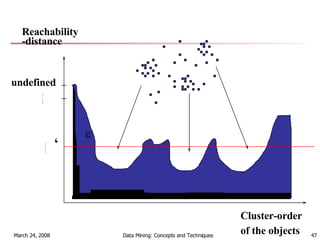
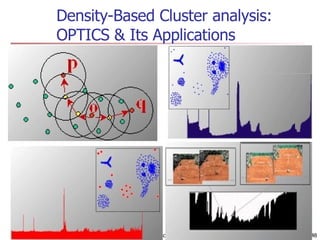
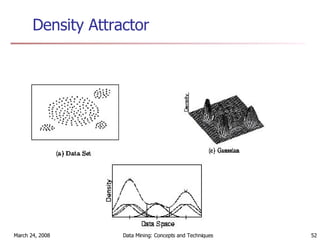
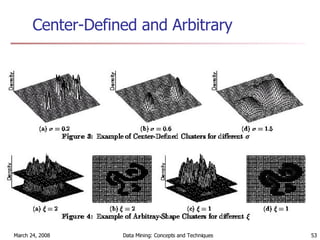
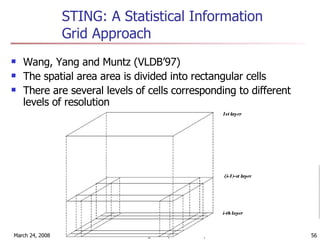
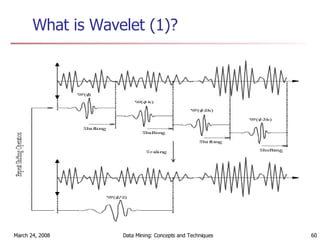
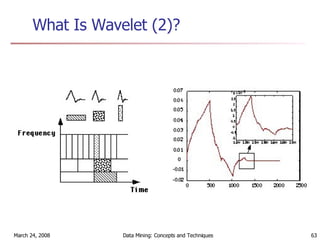
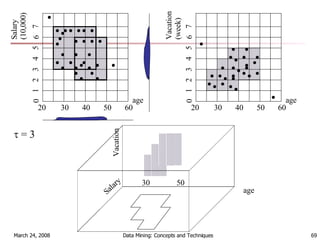
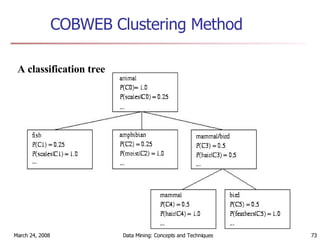
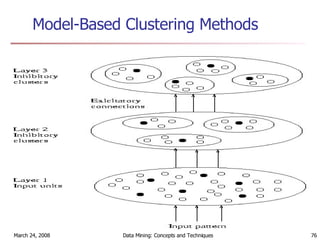
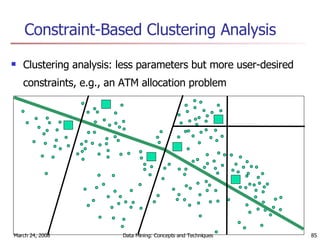
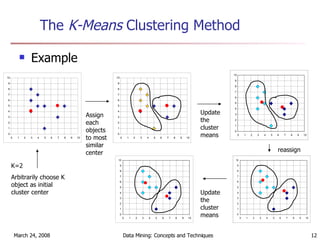
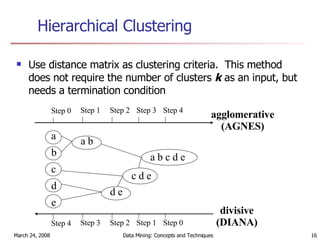
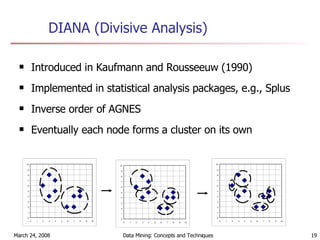
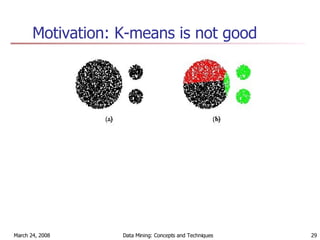
Cluster analysis is an unsupervised learning technique used to group unlabeled data points into meaningful clusters. There are several approaches to cluster analysis including partitioning methods like k-means, hierarchical clustering methods like agglomerative nesting (AGNES), and density-based methods like DBSCAN. The quality of clusters is evaluated based on intra-cluster similarity and inter-cluster dissimilarity. Cluster analysis has applications in fields like pattern recognition, image processing, and market segmentation.


























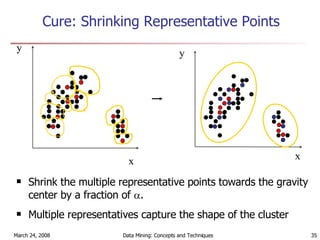
![Representative points Step 1: choose up to C points. If a cluster has no more than C points, all of them. Otherwise, choose the first point as the farthest from the mean. Choose the others as the farthest from the chosen ones. Step 2: shrink each point towards mean: p’ = p + * (mean – p) [0,1]. Larger means shrinking more. Reason for shrink: avoid outlier, as faraway objects are shrunk more.](https://image.slidesharecdn.com/my8clst-1206370412222810-5/85/My8clst-32-320.jpg)