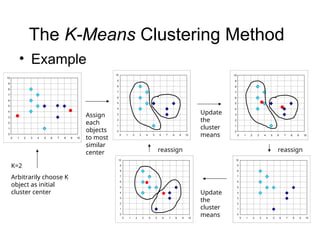
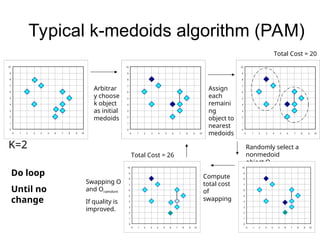
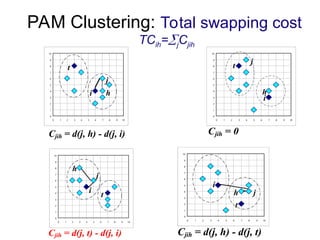
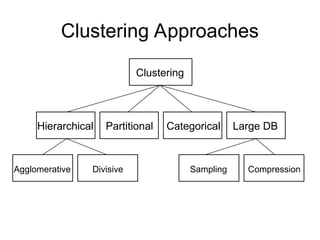
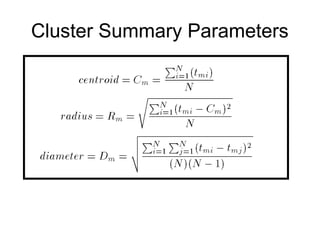
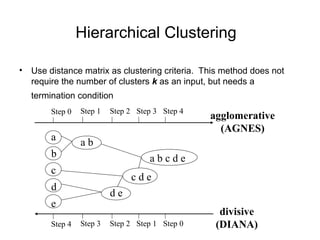
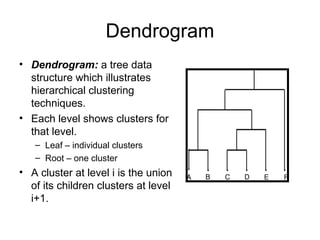
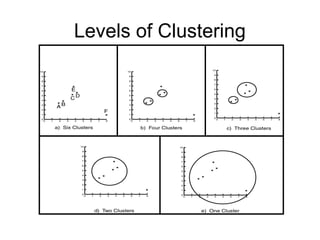
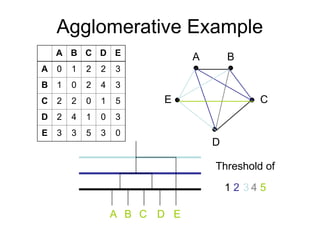
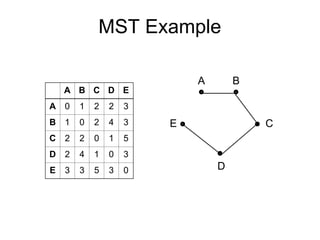
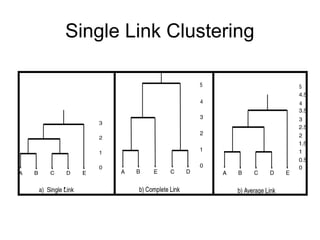
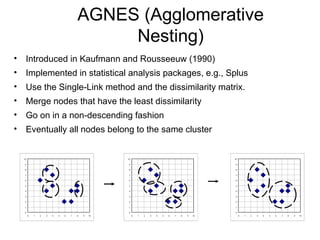
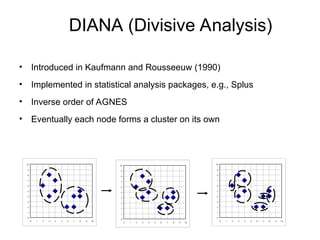
Cluster analysis is the unsupervised classification of data objects into groups (clusters) based on their similarity, with applications in marketing, land use, insurance, and city planning. Key clustering methods include partitioning algorithms like k-means and k-medoids, hierarchical techniques, and density-based approaches, each with its strengths and weaknesses. A successful clustering strategy requires quality measures, flexibility in handling various data attributes, and the ability to deal with noise and outliers.