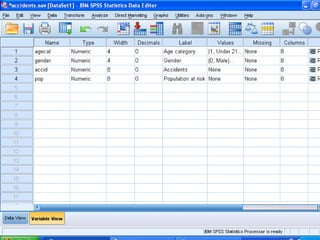
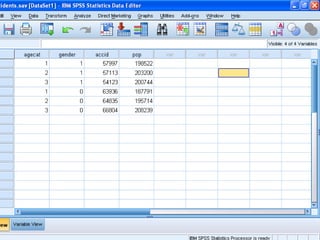
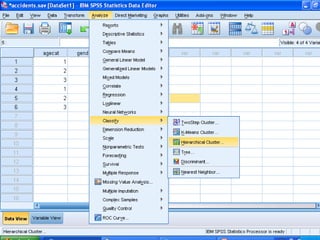
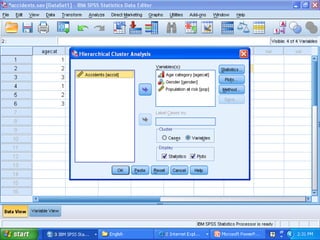
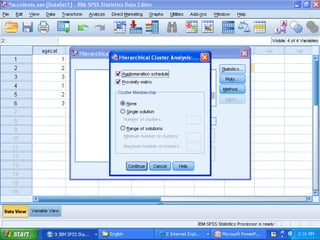
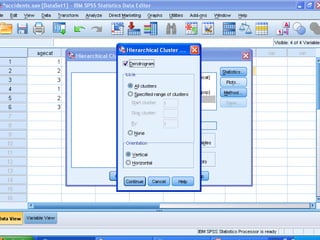
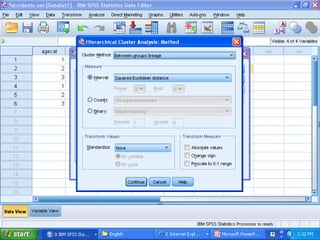
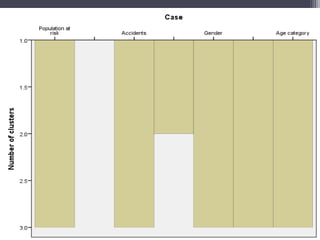
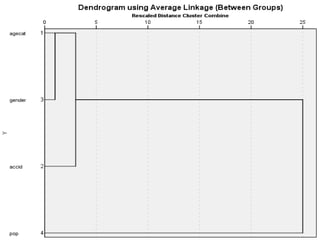
Cluster analysis is an unsupervised learning technique that groups similar data objects into clusters. It finds internal structures within unlabeled data by grouping objects based on their characteristics. Clustering is used to gain insight into data distribution and as a preprocessing step for other algorithms. Some applications of clustering include marketing, land use analysis, insurance risk assessment, and city planning. The quality of clustering depends on how well it separates objects within a cluster from objects in other clusters. Hierarchical clustering creates clusters by iteratively merging or splitting groups of objects based on their distances in a dendrogram.