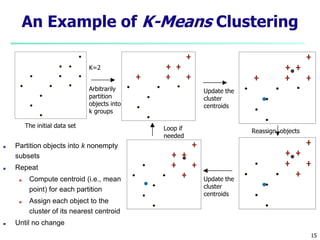
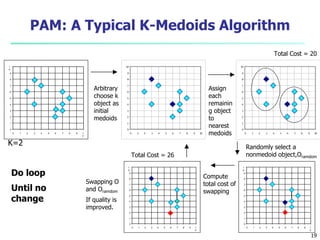
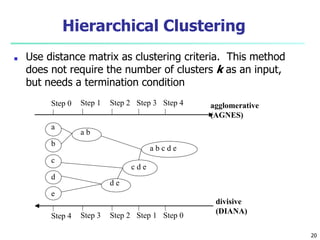
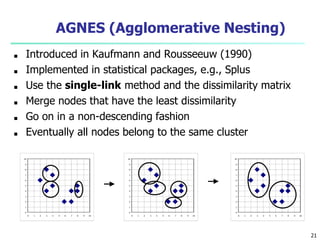
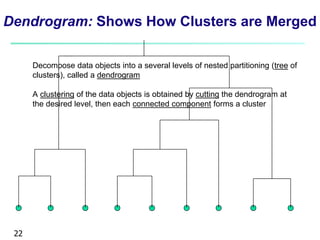
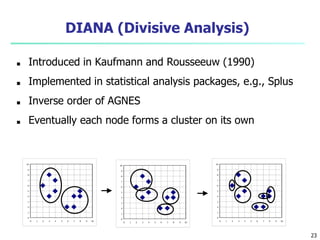
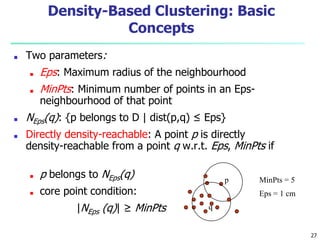
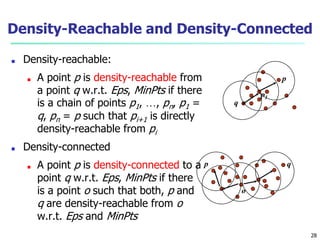
This document provides an overview of cluster analysis, including definitions of key concepts, common applications, and descriptions of various clustering methods. It defines cluster analysis as the task of grouping similar data objects into clusters, with the goal of high intra-cluster similarity and low inter-cluster similarity. Several clustering algorithms are summarized, including partitioning methods like k-means and k-medoids, hierarchical agglomerative methods like AGNES, and density-based methods. Evaluation of clustering quality and considerations for applying cluster analysis are also discussed.





































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)








![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)









