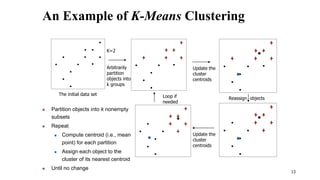
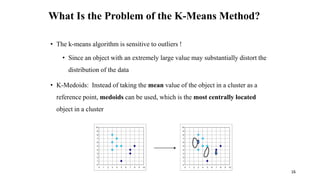
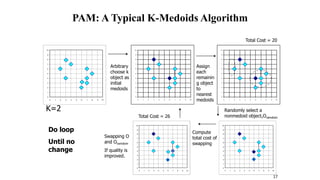
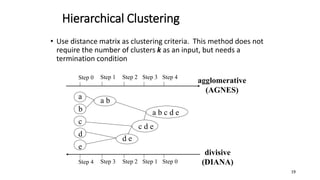
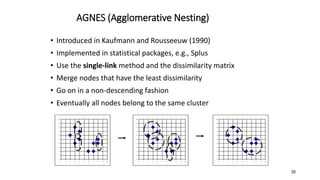
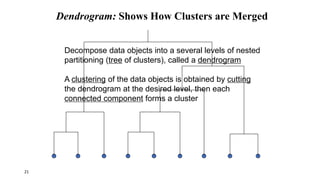
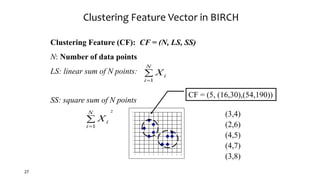
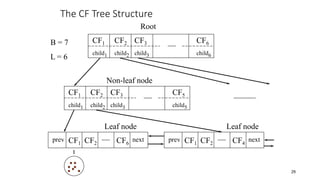
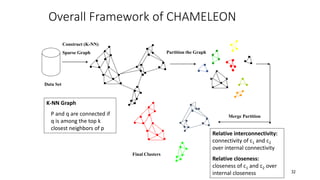
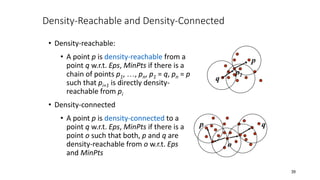
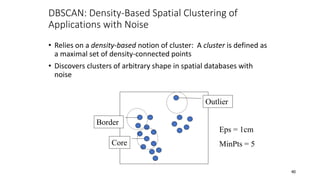
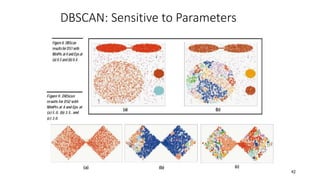
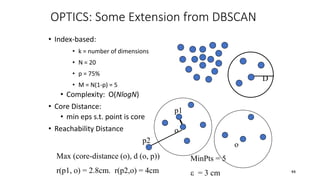
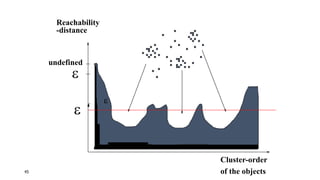
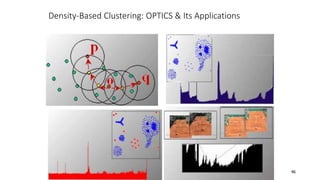
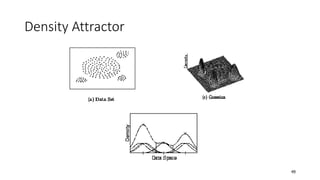
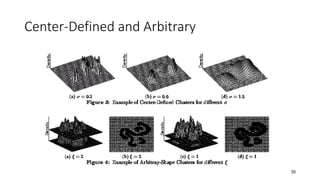
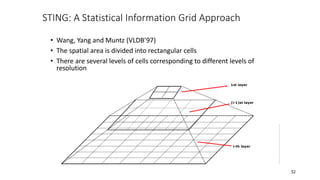
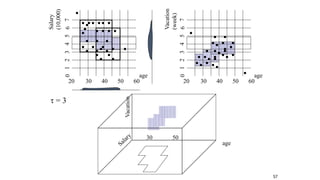
Cluster analysis is an unsupervised learning technique used to group similar objects together. It identifies clusters of objects such that objects within a cluster are more closely related to each other than objects in different clusters. Common applications of cluster analysis include document clustering, market segmentation, and identifying types of customers or animals. Popular clustering algorithms include k-means, k-medoids, hierarchical clustering, density-based clustering, and grid-based clustering.