Downloaded 44 times





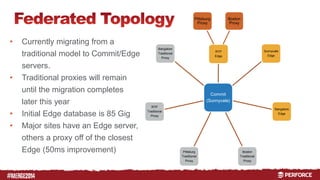

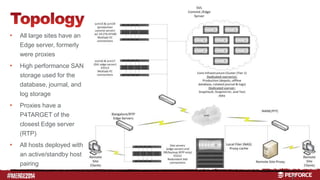
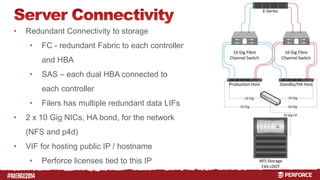











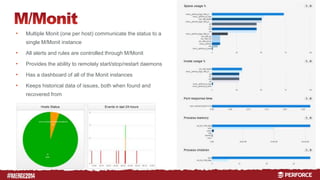
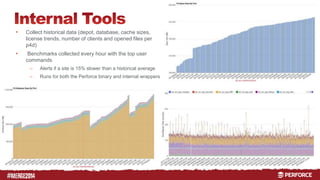







The document outlines the infrastructure and backup strategies for a global Perforce environment with over 4 million daily commands and 3722 users. It details the migration to commit/edge server architecture, high-performance storage solutions, and redundant systems for ensuring uptime and disaster recovery. Additionally, it describes monitoring tools and processes for maintaining optimal performance and data integrity across the system.
















































![[Tel aviv merge world tour] Perforce Server Update](https://cdn.slidesharecdn.com/ss_thumbnails/telavivmergeworldtourperforceserverupdate-130718081007-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paris merge world tour] Perforce Server Update](https://cdn.slidesharecdn.com/ss_thumbnails/paris-mergeworldtourperforceserverupdate-130718052353-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[MathWorks] Versioning Infrastructure](https://cdn.slidesharecdn.com/ss_thumbnails/versioning-infrastructure-mathworks-paper-130523183417-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[MathWorks] Versioning Infrastructure](https://cdn.slidesharecdn.com/ss_thumbnails/mathworks-michaelmirmanpv4-130523185914-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Europe merge world tour] Perforce Server Update](https://cdn.slidesharecdn.com/ss_thumbnails/europe-mergeworldtourperforceserverupdate-130718035120-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[India Merge World Tour] Meru Networks](https://cdn.slidesharecdn.com/ss_thumbnails/india-mergeworldtourmerunetworks-130819055003-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Perforce] Admin Workshop](https://cdn.slidesharecdn.com/ss_thumbnails/admin-workshop-slides-130523174141-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Perforce] Replication - Read Only Installs to Fully Filtered Forwarding](https://cdn.slidesharecdn.com/ss_thumbnails/perforce-replication-slides-130523174850-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











































