Download as PDF, PPTX





















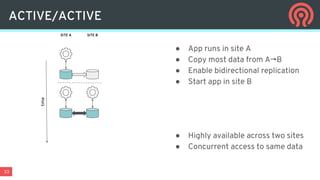




![38
RGW FEDERATION MODEL
● Zone
○ Collection RADOS pools storing data
○ Set of RGW daemons serving that content
● ZoneGroup
○ Collection of Zones with a replication relationship
○ Active/Passive[/…] or Active/Active
● Namespace
○ Independent naming for users and buckets
○ All ZoneGroups and Zones replicate user and
bucket index pool
○ One Zone serves as the leader to handle User and
Bucket creations/deletions
● Failover is driven externally
○ Human (?) operators decide when to write off a
master, resynchronize
Namespace
ZoneGroup
Zone](https://image.slidesharecdn.com/2018-181115132952/85/Ceph-data-services-in-a-multi-and-hybrid-cloud-world-38-320.jpg)
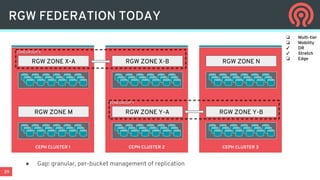
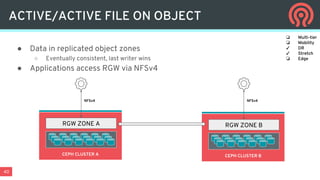

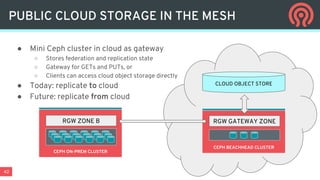










The document discusses the evolution and capabilities of Ceph data services in multi- and hybrid cloud environments, emphasizing unified storage solutions including block, file, and object storage. It highlights the challenges of data placement, mobility, and policy management in cloud-native applications, advocating for an automated and orchestration-focused approach to data management. Key features and priorities of Ceph are detailed, including its release schedule, data services, and the integration of Kubernetes for enhanced application orchestration.



![[OpenStack Days Korea 2016] Track1 - All flash CEPH 구성 및 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/12skt-160226171513-thumbnail.jpg?width=640&height=640&fit=bounds)









































































