Downloaded 78 times






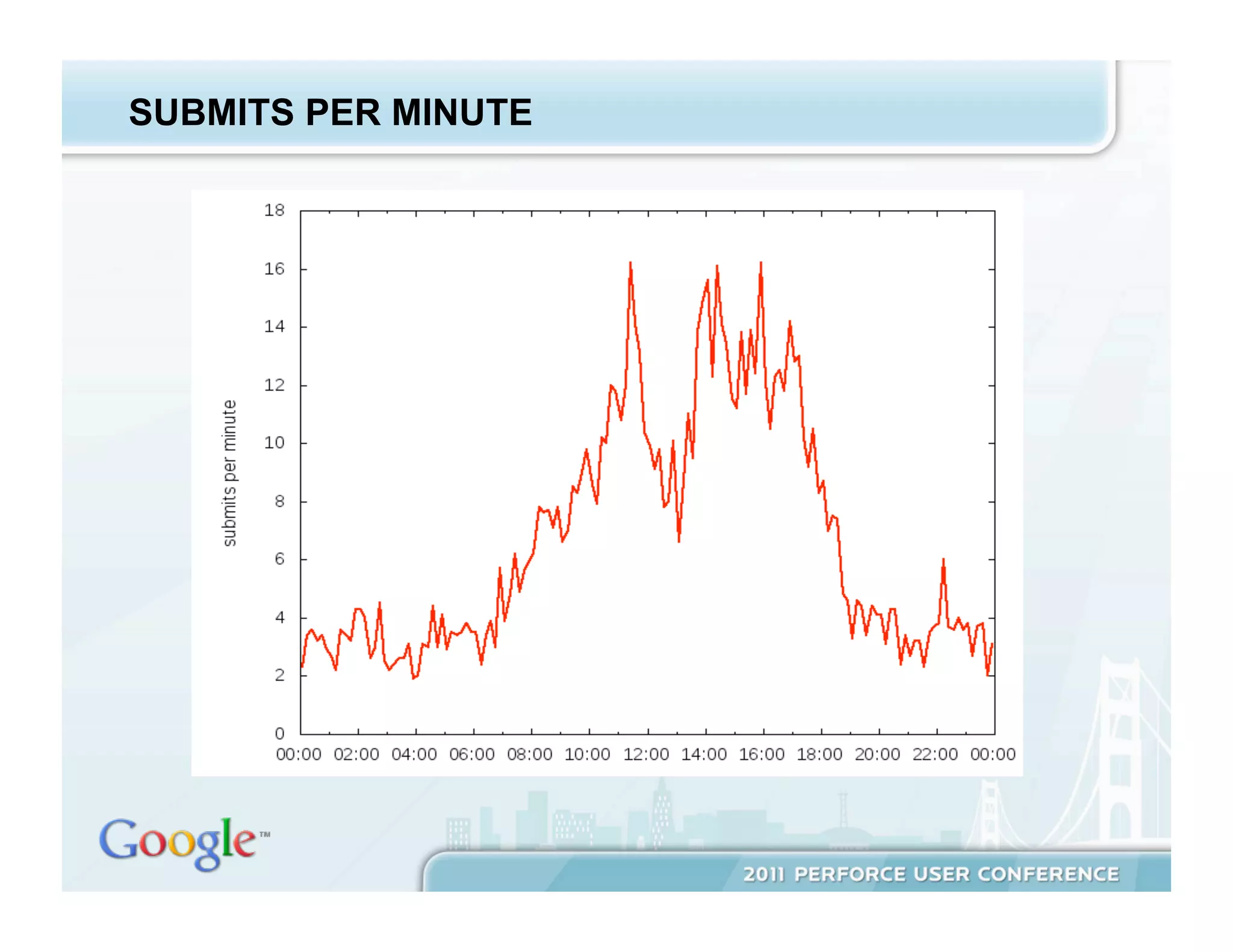




























The document discusses Google's extensive use of Perforce for version control, outlining server architecture, performance management, and maintenance practices utilized over 11 years of operation. It covers the server's configuration, performance improvement strategies, and administrative efficiency measures while also emphasizing the importance of monitoring and reducing metadata. Furthermore, it shares insights and lessons learned from managing a large-scale system, highlighting the need for continuous improvement and tailored solutions.




















![[Perforce] Admin Workshop](https://cdn.slidesharecdn.com/ss_thumbnails/admin-workshop-slides-130523174141-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)








![[MathWorks] Versioning Infrastructure](https://cdn.slidesharecdn.com/ss_thumbnails/versioning-infrastructure-mathworks-paper-130523183417-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Tel aviv merge world tour] Qwilt P4 Conference](https://cdn.slidesharecdn.com/ss_thumbnails/telavivmergeworldtourqwiltp4conference-130718081039-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)








![[Citrix] Perforce Standardisation at Citrix](https://cdn.slidesharecdn.com/ss_thumbnails/perforce-standardization-citrix-paper-130524110547-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NetherRealm Studios] Game Studio Perforce Architecture](https://cdn.slidesharecdn.com/ss_thumbnails/game-studio-perforce-architecture-slides-130523181224-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[India Merge World Tour] IC Manage](https://cdn.slidesharecdn.com/ss_thumbnails/india-mergeworldtouricmanage-130819053840-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[IC Manage] Workspace Acceleration & Network Storage Reduction](https://cdn.slidesharecdn.com/ss_thumbnails/workspace-acceleration-ic-manage-slides-130524110321-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


























![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)













