Download to read offline



![Versioning Infrastructure
4
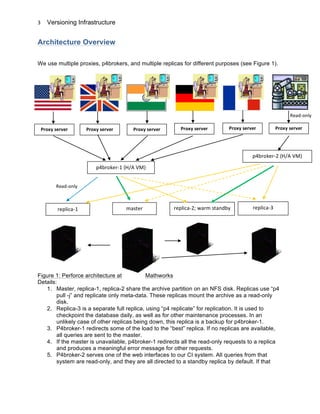
replica is unavailable, another one is used. The master is used only if no replicas are
available.
How We Describe Our Infrastructure
Our infrastructure is described by an xml configuration file, where every server has certain
characteristics. In addition, we describe all “services” that must be started during the boot
process. For example, we may have this description in the file:
<variables>
<set>brokerhost=p4brokertest</set>
</variables>
<server>
<type>Primary</type>
<hostname>$brokerhost</hostname>
<port>1666</port>
<top>/local</top>
<start>
[/local/perforce/bin/p4broker -d -c
/local/perforce/config/broker.testconf]
</start>
<init_script>
/etc/init.d/p4broker.test -> /local/perforce/scripts/p4d.test
</init_script>
</server>
We have two files describing the infrastructure: one for the production stack and the other for
the test stack.
Both files are handled by a special and separate server. These files are the only files on that
server, so we don’t need a license for it.
The server has one trigger installed: change-commit. Every time one of those two files gets
updated, the trigger “pushes” the new file to all essential hosts of the infrastructure. (We will say
more about how we push files to different hosts later.)
Examples of How We Use Configuration Files Describing
Infrastructure
Example 1: Boot scripts and controlled failover.
We keep in /etc/init.d links to actual scripts. For example:
/etc/init.d/p4broker.prod -> /local/perforce/scripts/p4broker.prod*](https://image.slidesharecdn.com/versioning-infrastructure-mathworks-paper-130523183417-phpapp01/85/MathWorks-Versioning-Infrastructure-4-320.jpg)
![Versioning Infrastructure
5
Actual scripts read the configuration file, determine what they need to start on the current host,
and proceed accordingly.
Every Perforce host has a single boot script, and there are very few different scripts, which we
use as boot scripts (code used on p4d servers is slightly different from the code on p4p or
p4broker servers).
Say we are performing a controlled failover: the server that was a master will become a standby
and vice versa.
The old configuration may say:
<variables>
<set>master=p4test-00</set>
<set>standby=p4test-01</set>
</variables>
<server>
<type>Primary</type>
<hostname>$master</hostname>
<port>1666</port>
<top>/export</top>
<start>
[$bin/p4d -d -p 1666 -In MasterTest -r $dbroot/1666 -L
$logroot/1666/p4d.log –J $jnlroot/1666/journal]
</start>
<init_script>
/etc/init.d/p4d.current -> $dbroot/scripts/p4d.test
</init_script>
</server>
<server>
<type>Secondary</type>
<hostname>$standby</hostname>
<port>1666</port>
<top>/export</top>
<start>
[$bin/p4d -d -p 1666 -In StandbyTest -r $dbroot/1666 -L
$logroot/1666/p4d.log -J $jnlroot/1666/journal]
[$bin/p4 -p $production:1666 replicate -s $jnlroot/1666/replica.state
-J $jnlroot/1666/journal $dbroot/1666/scripts/p4admin_replicate -v -
port 1666 -srchost $production -srctop /export/data/perforce/1666]
</start>
<init_script>
/etc/init.d/p4d.current -> $dbroot/scripts/p4d.test
</init_script>
</server>](https://image.slidesharecdn.com/versioning-infrastructure-mathworks-paper-130523183417-phpapp01/85/MathWorks-Versioning-Infrastructure-5-320.jpg)


![Versioning Infrastructure
8
counters with time stamps as the value makes monitoring (and alerting administrators) a trivial
task.
This implementation has been working very well with many different workspaces.
Interestingly enough, the need to maintain many crontabs was also a task worth mentioning.
Maintenance of Crontabs
Before receiving a request to update workspaces around the world, our Perforce infrastructure
contained about 20 hosts. Almost all of them had some cron jobs running regularly by the
special “service” user.
When we had to change a crontab, we would do what any UNIX administrator would do: rsh or
ssh as the service user to the machine, run “crontab –e”, and modify the crontab. A number of
people could log in as that service user, and we had no history of who modified the crontab,
when, and why. All we could do was to save daily the version we had. The result was
something like this:
00 05 * * * cd somedir; crontab -l > `hostname`; ci -l `hostname` >
/dev/null 2>&1
Now we had to approximately double the number of the Perforce hosts by adding new hosts
around the world. The thought that we would sometimes have to ssh to 40+ machines to modify
crontabs was not appealing.
Our Solution: Put Crontabs Under Perforce Control and Set a Change-
commit Trigger to Update the Crontab
Here is an example of a trigger line:
cron change-commit //depot/crontabs/... "triggers/install.crontab -p
%serverport% -c %changelist%"
The essence of the trigger is to run
p4 print -q //depot/crontabs/somefile | ssh host crontab -
We currently use the “push” method to install crontabs on our Perforce infrastructure hosts. If it
becomes too slow, we’ll switch to the “pull” method described earlier.
For a push method, a single network glitch may prevent us from updating the crontab. We
wanted to ensure that we eventually get the right one. So we have one cron job on each of
those hosts that runs once a day and updates the crontab this way:
01 00 * * * export HOST=`hostname`; /local/perforce/bin/p4 -p perforce:1666 print -q
//depot/crontabs/batscm/$HOST > /tmp/crontab.$$; [ -s /tmp/crontab.$$ ] && crontab
/tmp/crontab.$$; rm /tmp/crontab.$$](https://image.slidesharecdn.com/versioning-infrastructure-mathworks-paper-130523183417-phpapp01/85/MathWorks-Versioning-Infrastructure-8-320.jpg)


This document describes the Perforce configuration management system used at MathWorks. It discusses MathWorks' Perforce infrastructure which includes a master server, replicas for load balancing and high availability, and proxies. It also describes how configuration files are used to define and manage the infrastructure, including services, failover processes, and cron jobs. Specific examples are provided around automating workspace updates across multiple global locations.



























![[Citrix] Perforce Standardisation at Citrix](https://cdn.slidesharecdn.com/ss_thumbnails/perforce-standardization-citrix-paper-130524110547-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Lucas Films] Using a Perforce Proxy with Alternate Transports](https://cdn.slidesharecdn.com/ss_thumbnails/perforce-proxy-paper-130524105857-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Mentor Graphics] A Perforce-based Automatic Document Generation System](https://cdn.slidesharecdn.com/ss_thumbnails/perforce-based-automatic-documentation-generation-paper-130523183020-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


![[NetApp] Simplified HA:DR Using Storage Solutions](https://cdn.slidesharecdn.com/ss_thumbnails/simplified-ha-dr-netapp-perforce-paper-130523181353-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Nvidia] Extracting Depot Paths Into New Instances of Their Own](https://cdn.slidesharecdn.com/ss_thumbnails/dividing-depots-paper-130523180705-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[IC Manage] Workspace Acceleration & Network Storage Reduction](https://cdn.slidesharecdn.com/ss_thumbnails/workspace-acceleration-ic-manage-paper-130524110237-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





![[AMD] Novel Use of Perforce for Software Auto-updates and File Transfer](https://cdn.slidesharecdn.com/ss_thumbnails/novel-use-software-auto-updates-paper-130524110904-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NetherRealm Studios] Game Studio Perforce Architecture](https://cdn.slidesharecdn.com/ss_thumbnails/game-studio-perforce-architecture-paper-130523181105-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[SAP] Perforce Administrative Self Services at SAP](https://cdn.slidesharecdn.com/ss_thumbnails/admin-self-services-sap-paper-130523171359-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Webinar] The Changing Role of Release Engineering in a DevOps World with J. ...](https://cdn.slidesharecdn.com/ss_thumbnails/webinar-jpaulreed-may2016v6-160606182901-thumbnail.jpg?width=640&height=640&fit=bounds)


![[MathWorks] Versioning Infrastructure](https://cdn.slidesharecdn.com/ss_thumbnails/mathworks-michaelmirmanpv4-130523185914-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Paris merge world tour] Perforce Server Update](https://cdn.slidesharecdn.com/ss_thumbnails/paris-mergeworldtourperforceserverupdate-130718052353-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Tel aviv merge world tour] Perforce Server Update](https://cdn.slidesharecdn.com/ss_thumbnails/telavivmergeworldtourperforceserverupdate-130718081007-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






![[India Merge World Tour] Meru Networks](https://cdn.slidesharecdn.com/ss_thumbnails/india-mergeworldtourmerunetworks-130819055003-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Perforce] Perforce the Plentiful Platform](https://cdn.slidesharecdn.com/ss_thumbnails/perforce-plentiful-platform-slides-130523175403-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Perforce] Replication - Read Only Installs to Fully Filtered Forwarding](https://cdn.slidesharecdn.com/ss_thumbnails/perforce-replication-slides-130523174850-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











































