Download as PDF, PPTX



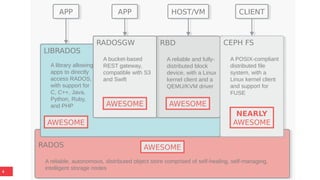





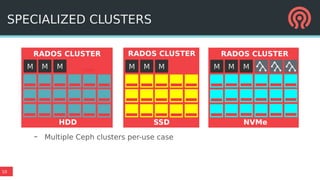
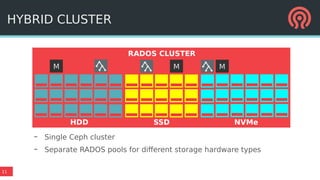






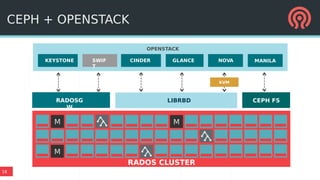
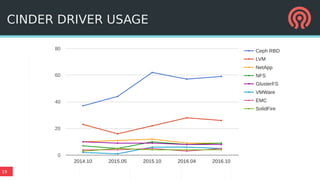


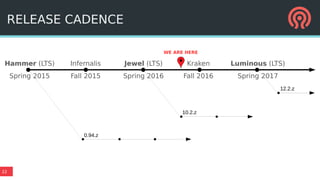

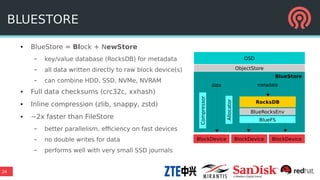


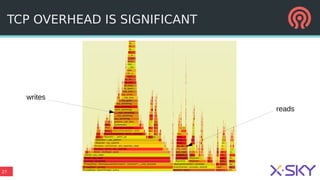
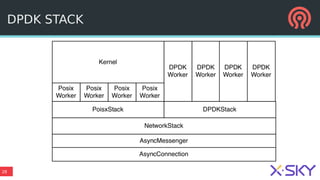
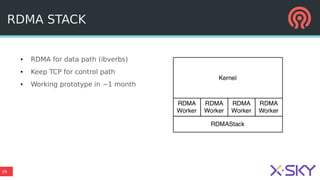

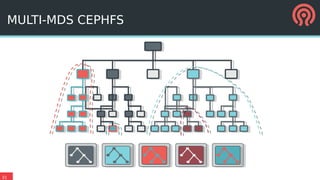


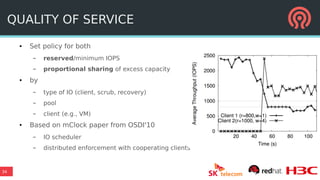
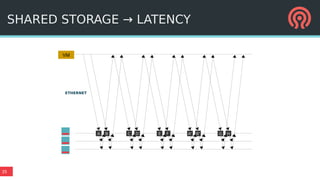
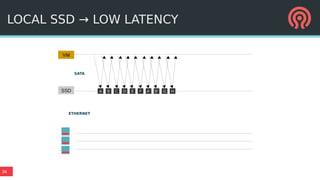

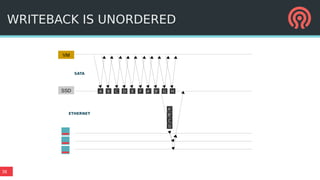
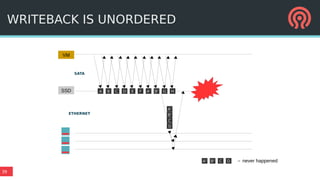
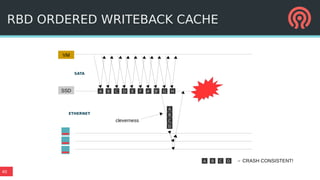
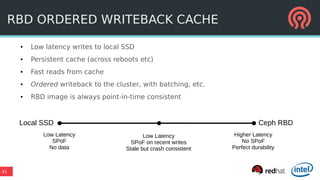

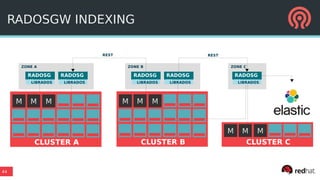
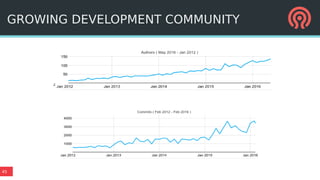










The document outlines Ceph's vision for open unified cloud storage, emphasizing its distributed storage capabilities, self-management features, and application compatibility. It discusses the benefits of open-source software, including avoiding vendor lock-in and lowering ownership costs, while highlighting Ceph's evolutionary roadmap and future improvements. The presentation also notes the collaborative efforts driving Ceph's development within the community and the importance of performance, scalability, and user experience enhancements.




















































































