Download as PDF, PPTX




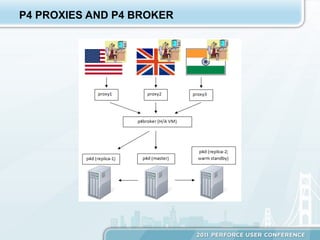























The document discusses the optimization and administration of a Perforce repository, highlighting strategies for scalability, availability, and reliability. Key elements include the implementation of proxies using anycast technology for user redirection, the use of p4 replicate and p4 pull commands for data replication, and a disaster recovery plan that involves immediate backup of checkpoints and journals. The author shares their experiences in improving load balancing and ensuring high availability through automated processes and system configurations.









![[NYC Meetup] Docker at Nuxeo](https://cdn.slidesharecdn.com/ss_thumbnails/dockermeetupnyc-140605110024-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)












![[2018.10.19] Andrew Kong - Tunnel without tunnel (Seminar at OpenStack Korea ...](https://cdn.slidesharecdn.com/ss_thumbnails/tunnelwithouttunnel-181022130534-thumbnail.jpg?width=640&height=640&fit=bounds)





![[MathWorks] Versioning Infrastructure](https://cdn.slidesharecdn.com/ss_thumbnails/versioning-infrastructure-mathworks-paper-130523183417-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[India Merge World Tour] Meru Networks](https://cdn.slidesharecdn.com/ss_thumbnails/india-mergeworldtourmerunetworks-130819055003-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Perforce] Replication - Read Only Installs to Fully Filtered Forwarding](https://cdn.slidesharecdn.com/ss_thumbnails/perforce-replication-slides-130523174850-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Tel aviv merge world tour] Perforce Server Update](https://cdn.slidesharecdn.com/ss_thumbnails/telavivmergeworldtourperforceserverupdate-130718081007-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Paris merge world tour] Perforce Server Update](https://cdn.slidesharecdn.com/ss_thumbnails/paris-mergeworldtourperforceserverupdate-130718052353-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Europe merge world tour] Perforce Server Update](https://cdn.slidesharecdn.com/ss_thumbnails/europe-mergeworldtourperforceserverupdate-130718035120-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[MathWorks] Versioning Infrastructure](https://cdn.slidesharecdn.com/ss_thumbnails/mathworks-michaelmirmanpv4-130523185914-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Perforce] Admin Workshop](https://cdn.slidesharecdn.com/ss_thumbnails/admin-workshop-slides-130523174141-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



![[NetApp] Simplified HA:DR Using Storage Solutions](https://cdn.slidesharecdn.com/ss_thumbnails/simplified-ha-dr-netapp-perforce-paper-130523181353-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











































