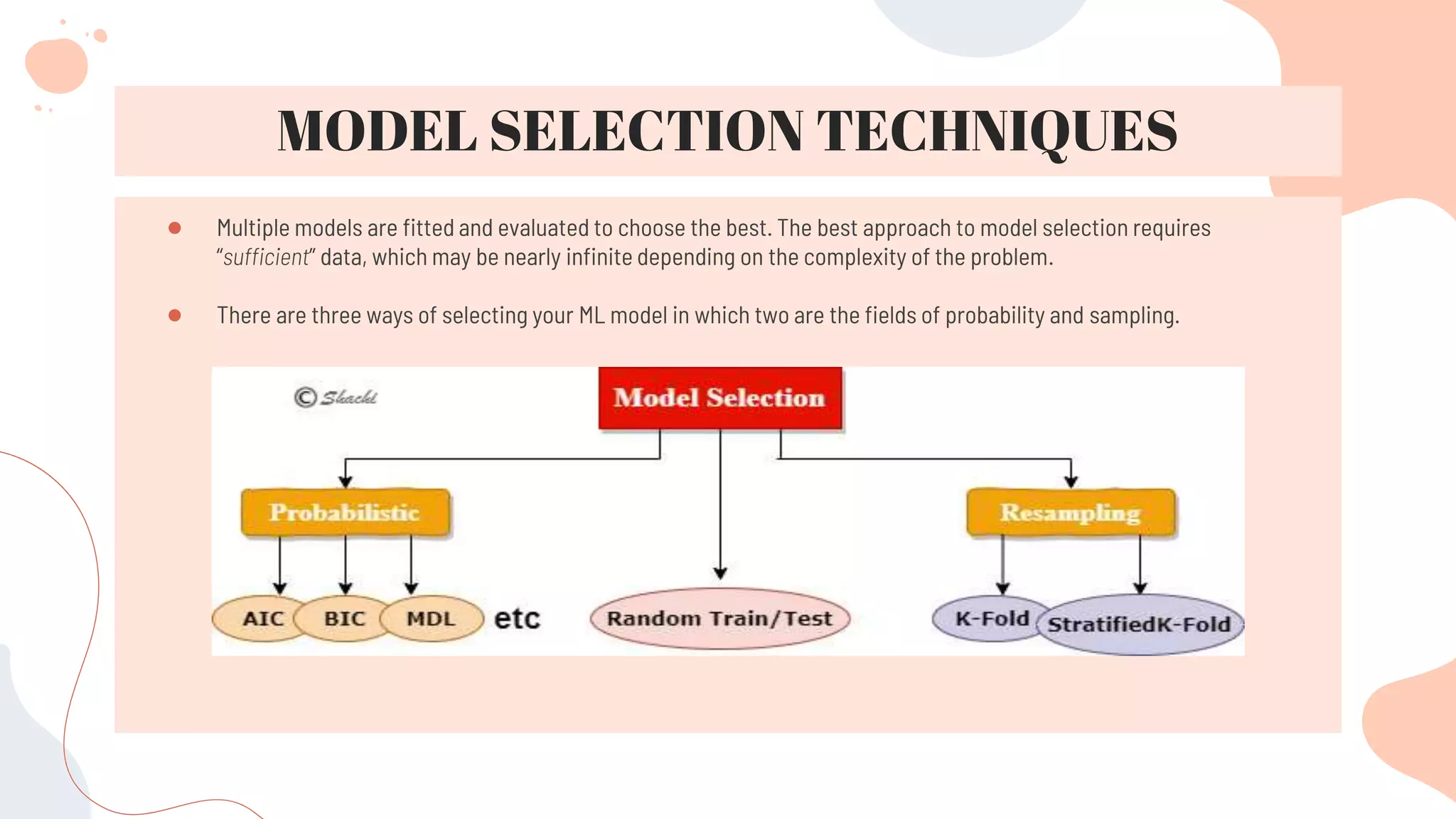
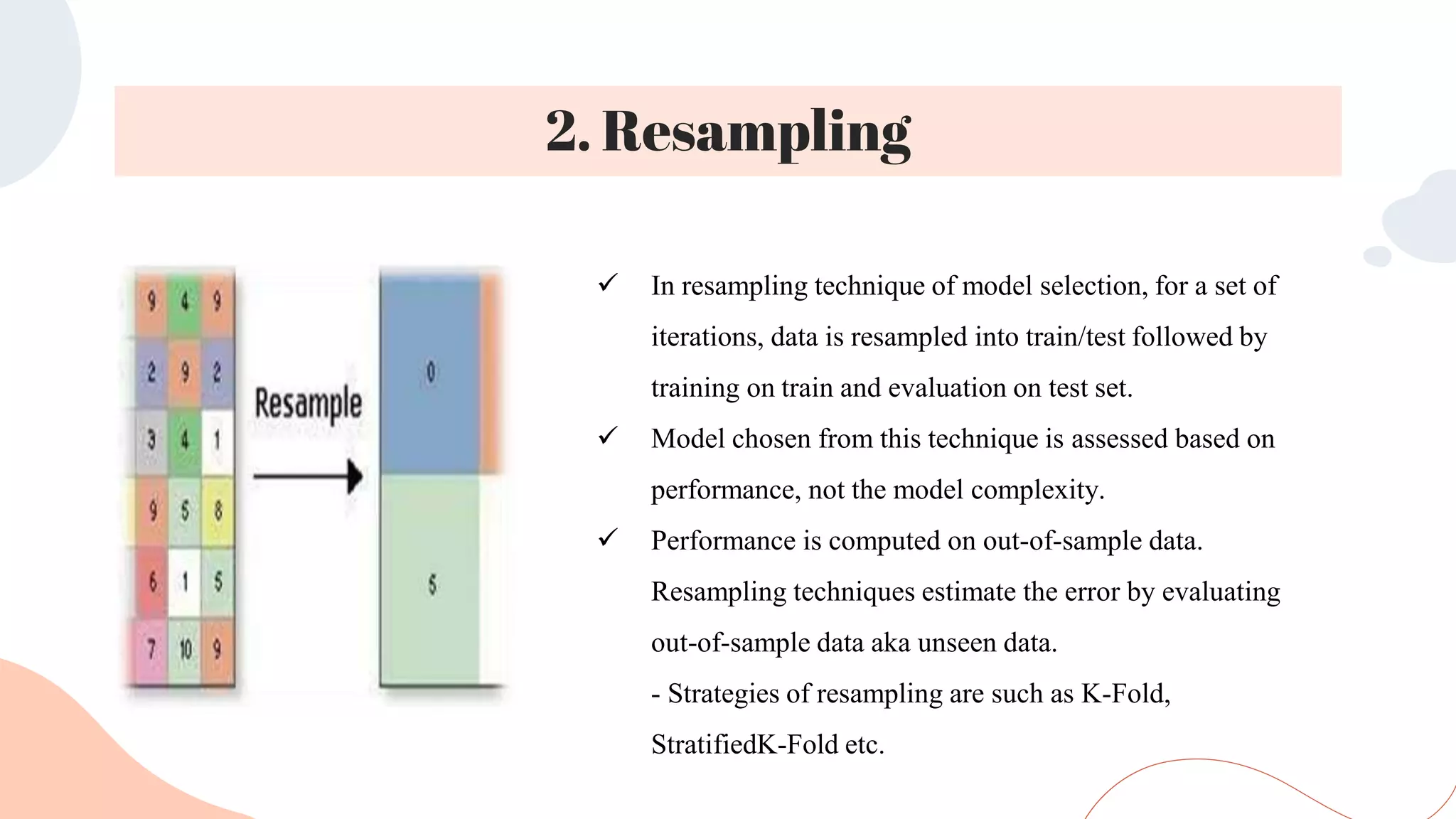
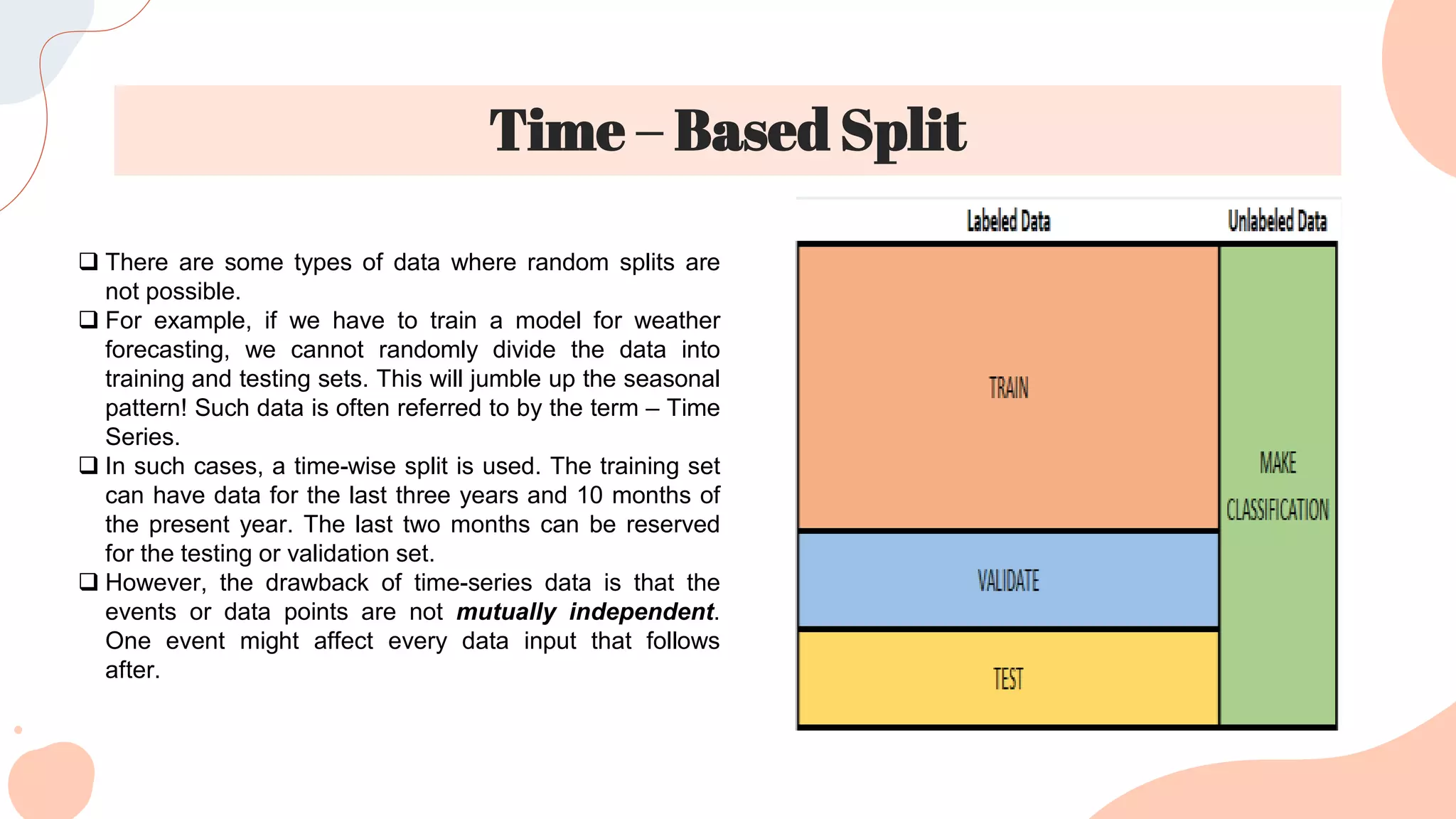
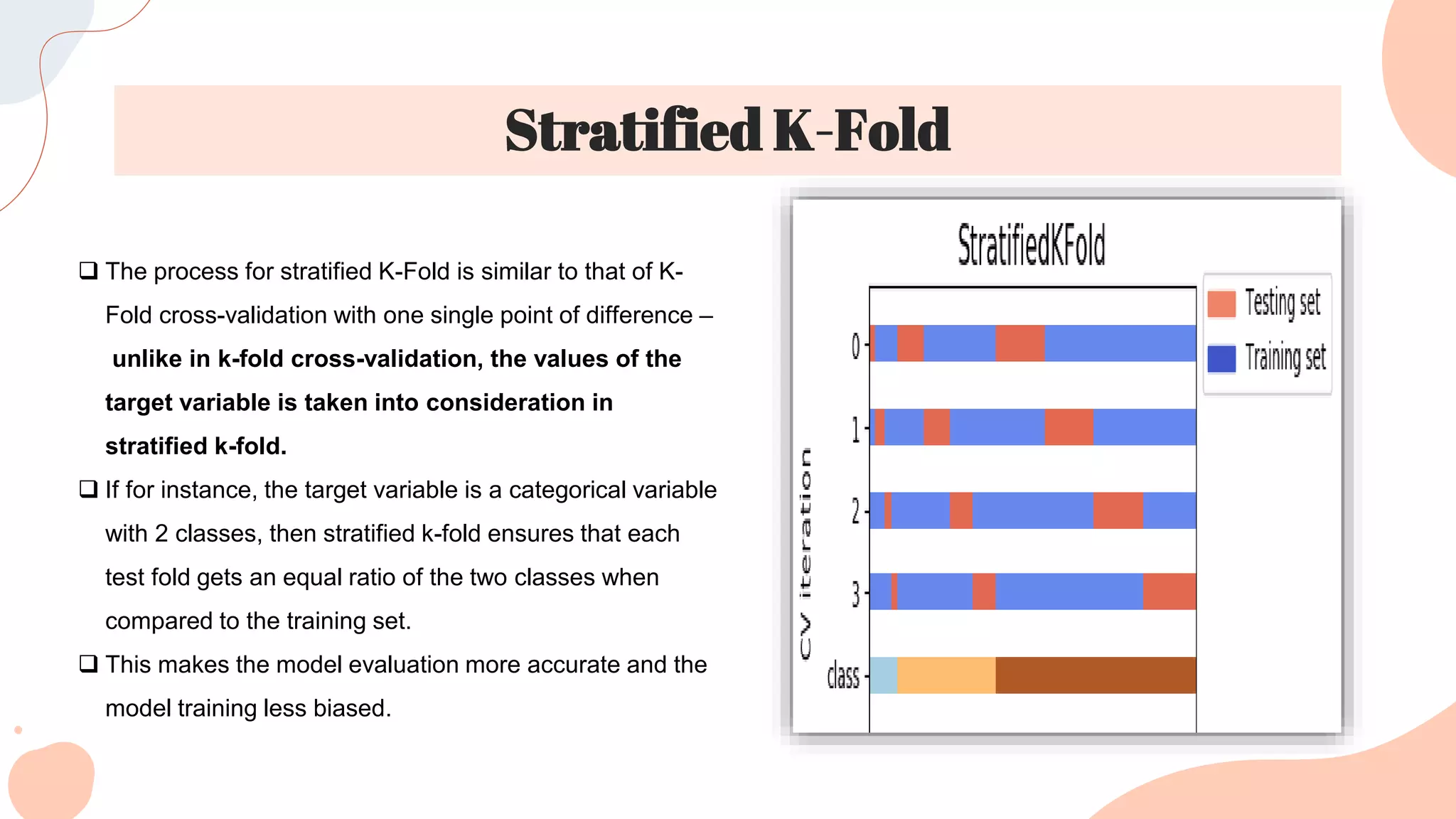
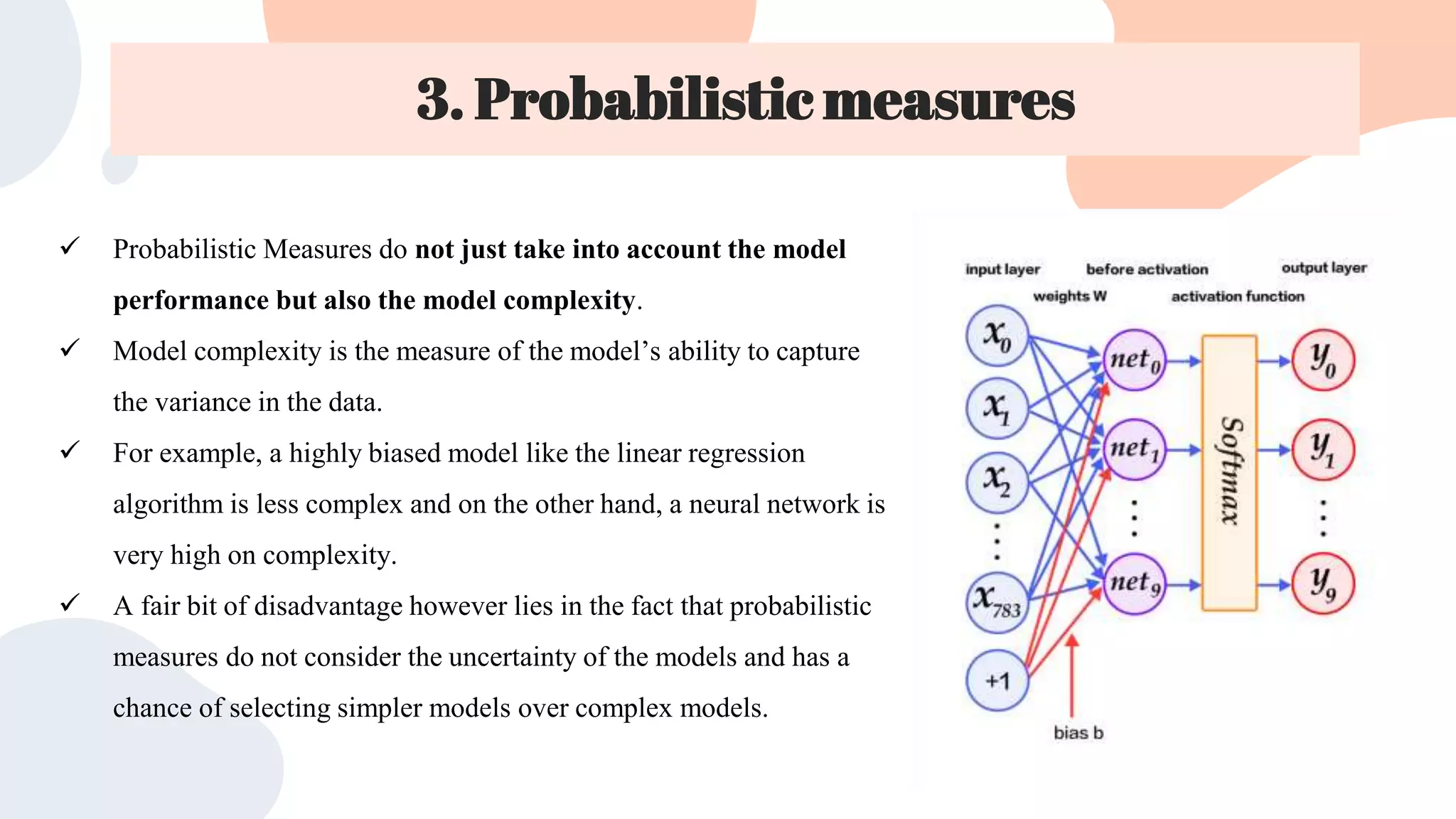
This document discusses different techniques for selecting machine learning models, including random train/test splitting, resampling methods like k-fold cross-validation and bootstrap, and probabilistic measures. Resampling techniques like k-fold cross-validation estimate error by evaluating models on out-of-sample data. Probabilistic measures consider both a model's performance and complexity, seeking to balance fit and simplicity. Common probabilistic measures mentioned are the Akaike Information Criterion, Bayesian Information Criterion, Minimum Description Length, and Structural Risk Minimization.