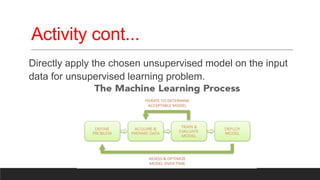
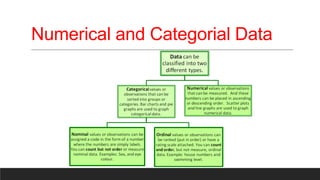
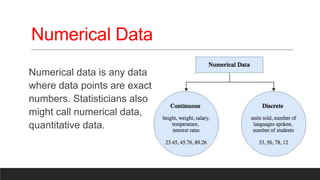
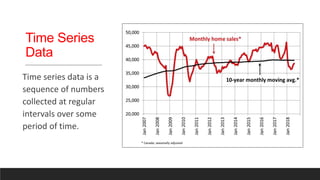
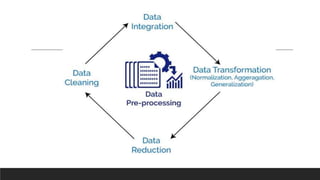
The document provides an overview of machine learning activities including data exploration, preprocessing, model selection, training and evaluation. It discusses exploring different data types like numerical, categorical, time series and text data. It also covers identifying and addressing data issues, feature engineering, selecting appropriate models for supervised and unsupervised problems, training models using methods like holdout and cross-validation, and evaluating model performance using metrics like accuracy, confusion matrix, F-measure etc. The goal is to understand the data and apply necessary steps to build and evaluate effective machine learning models.







































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

















