Download as PDF, PPTX






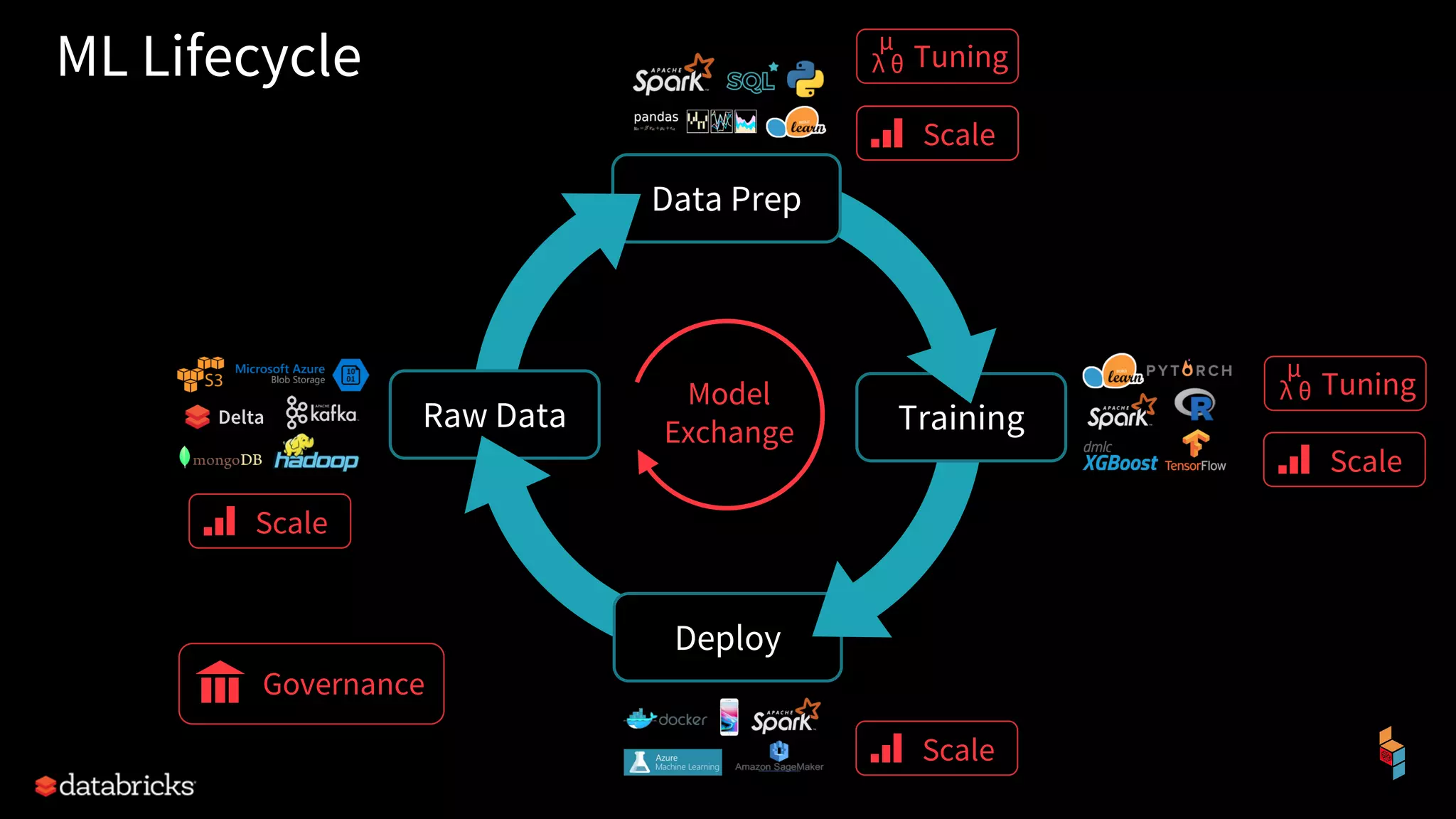



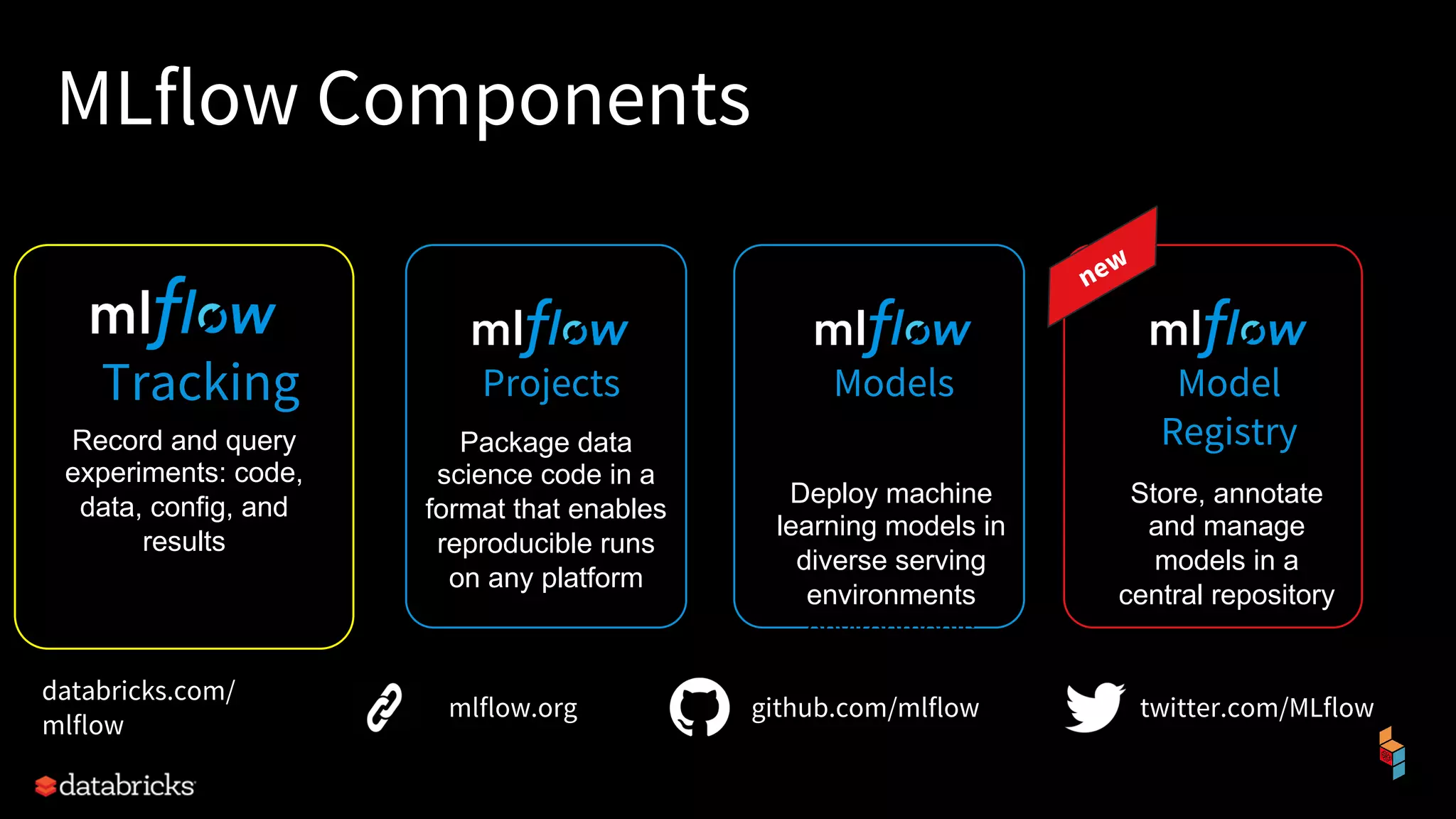



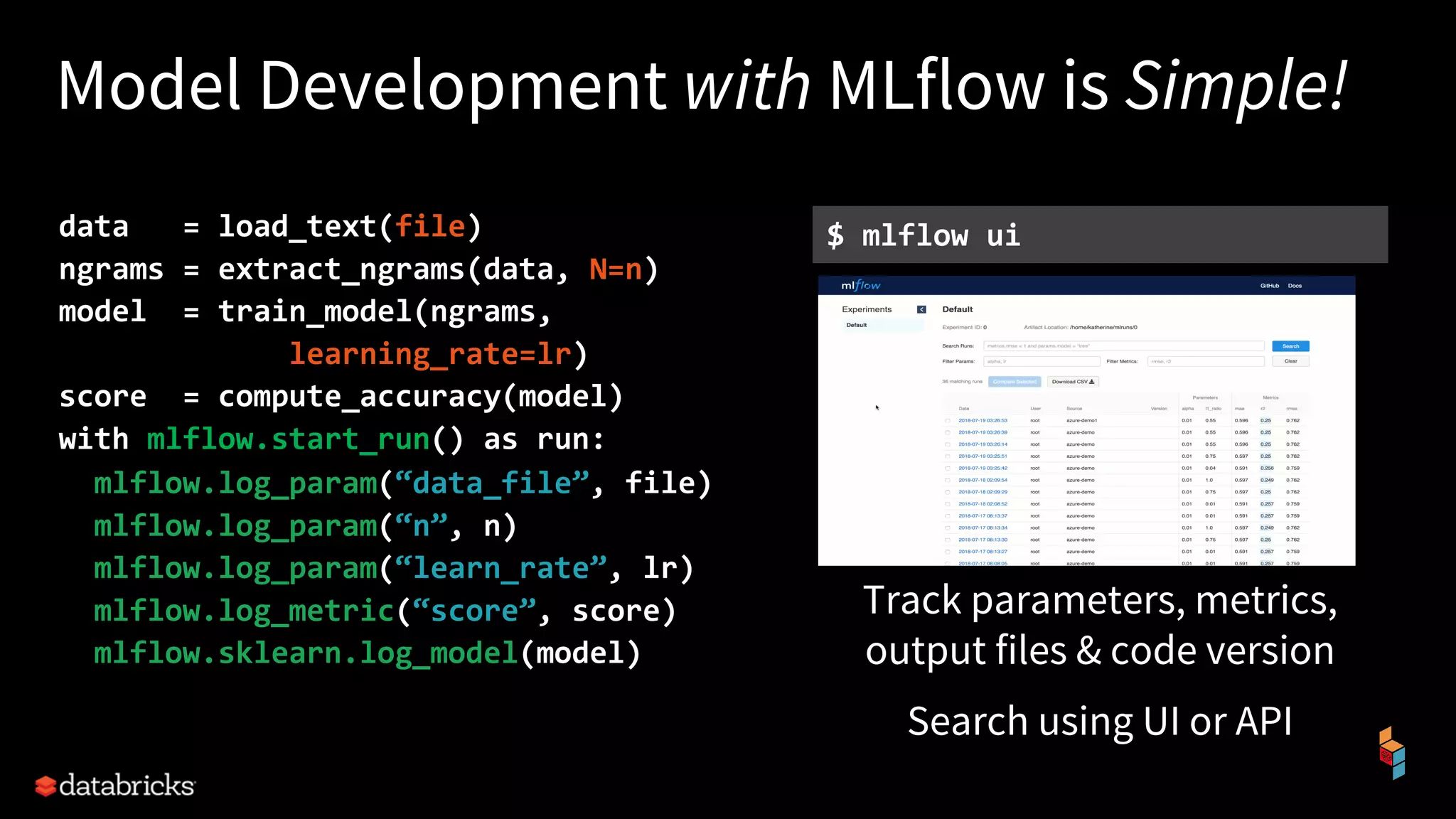
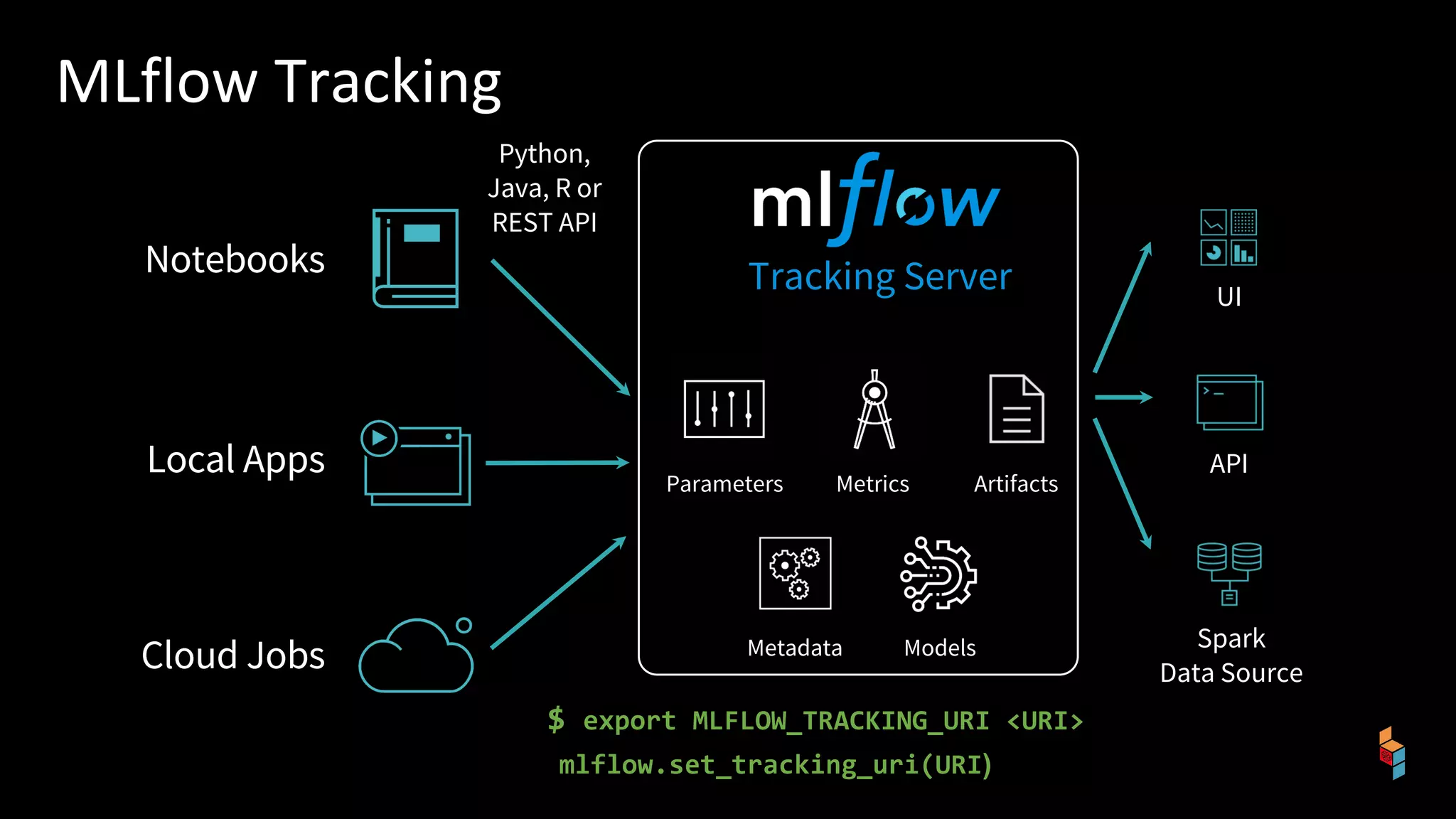

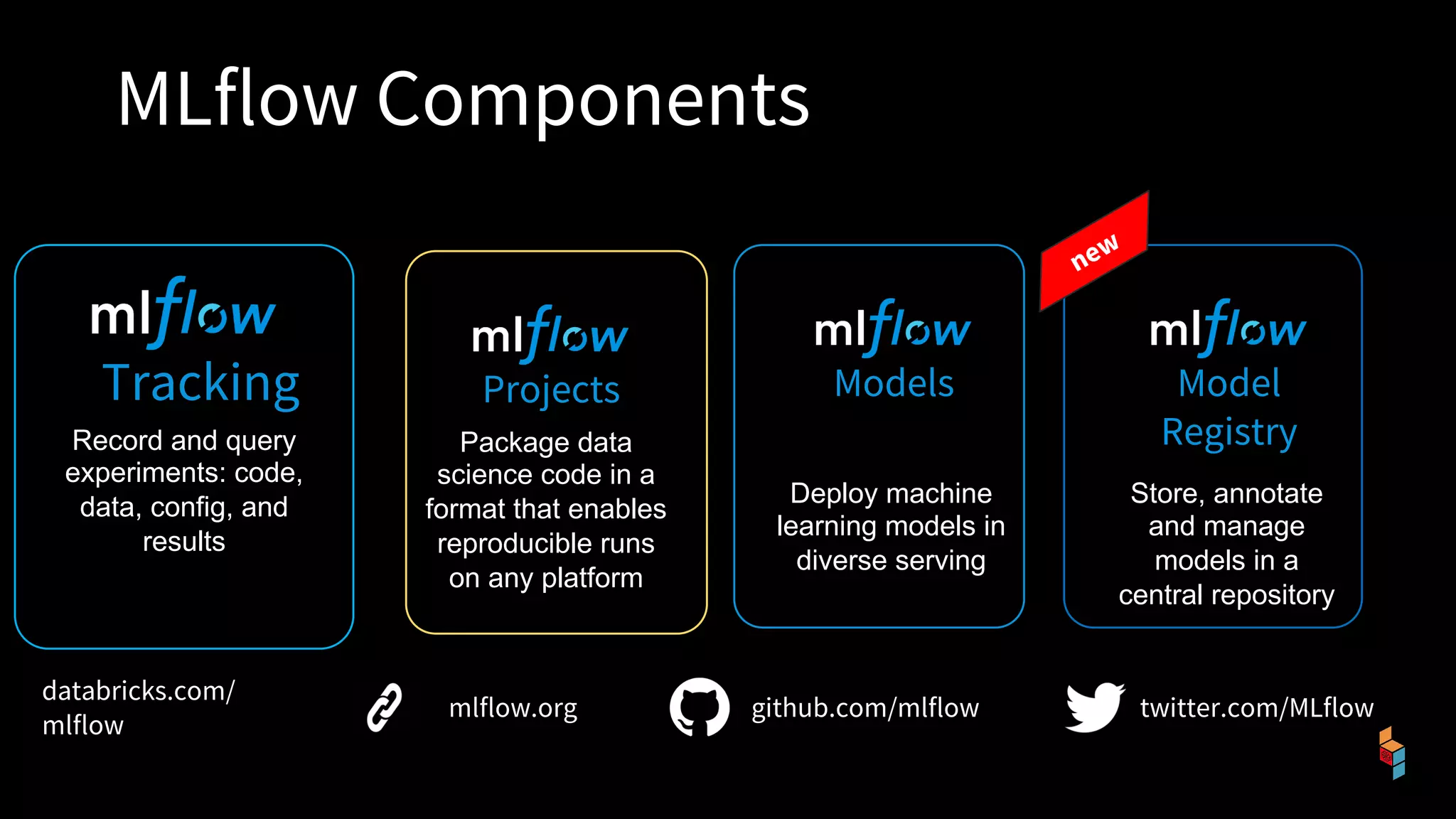

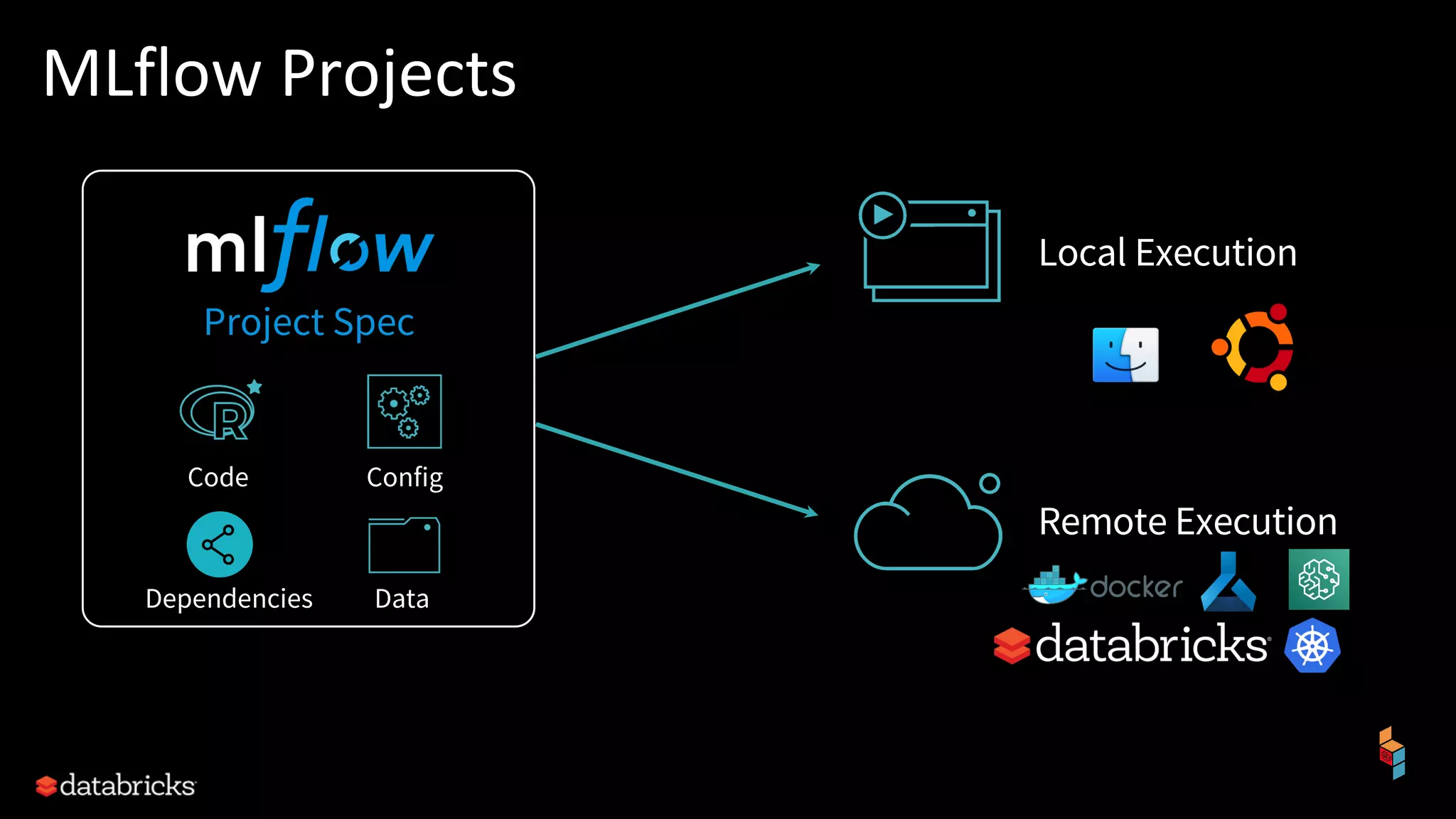


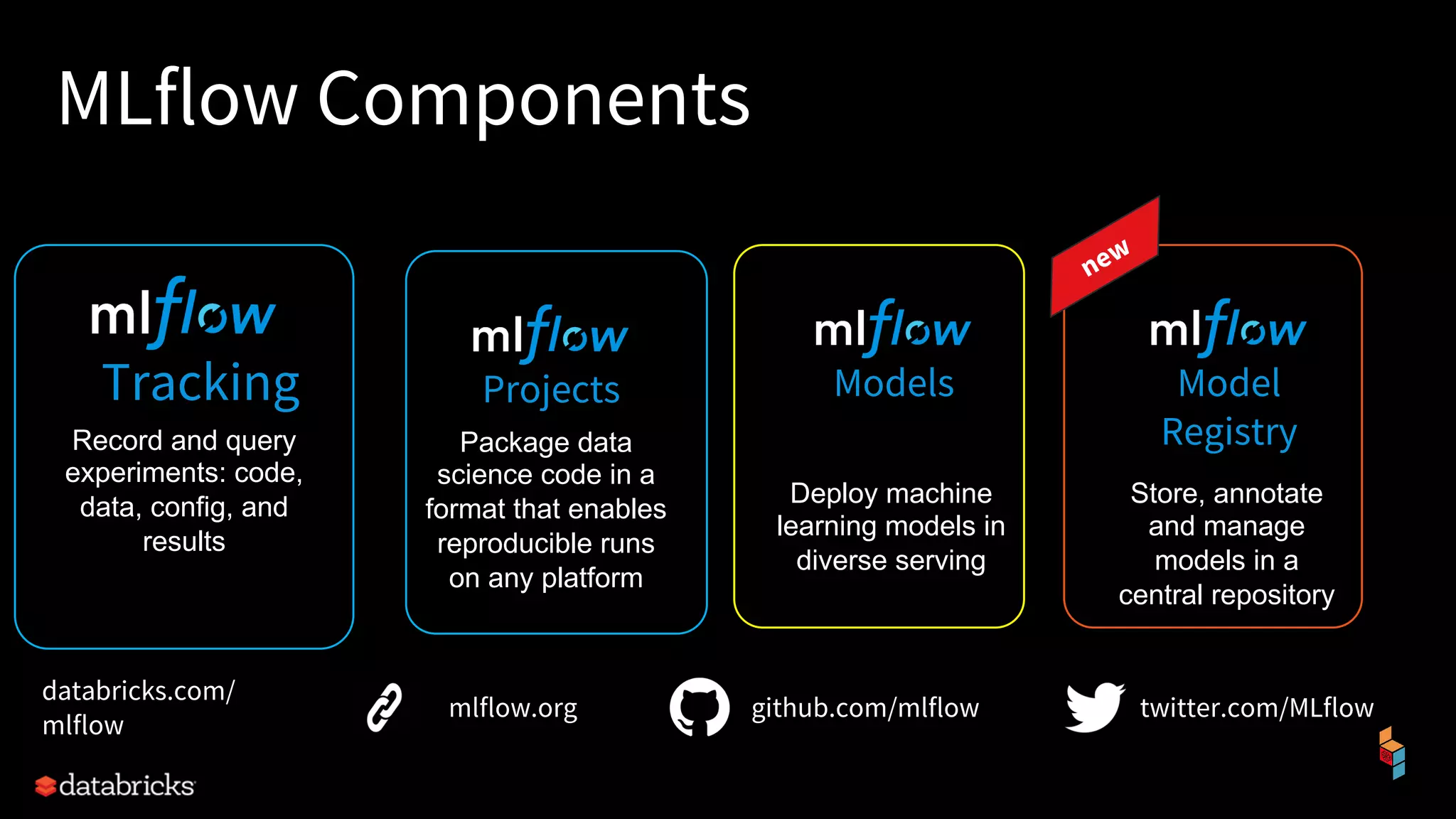
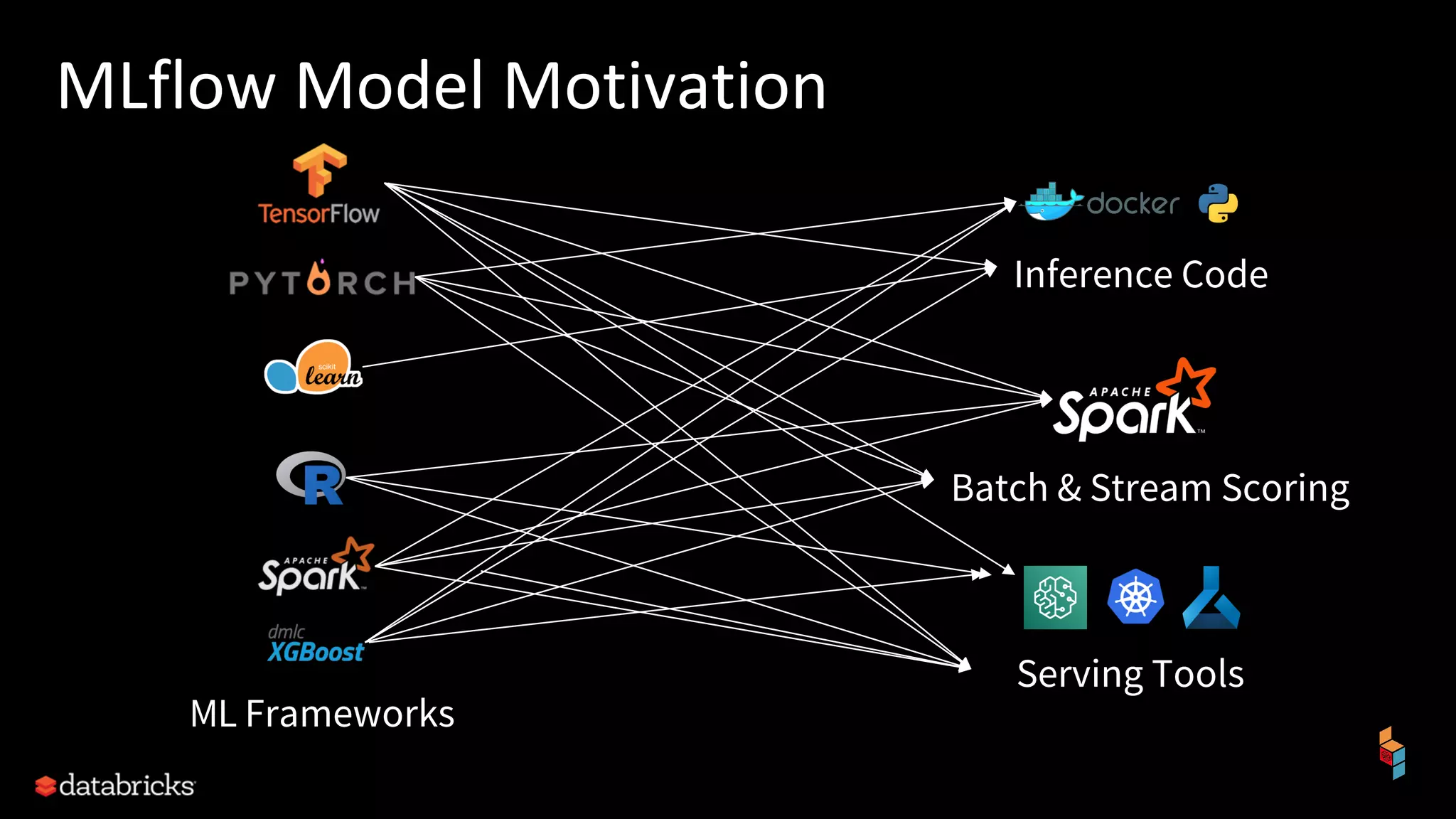
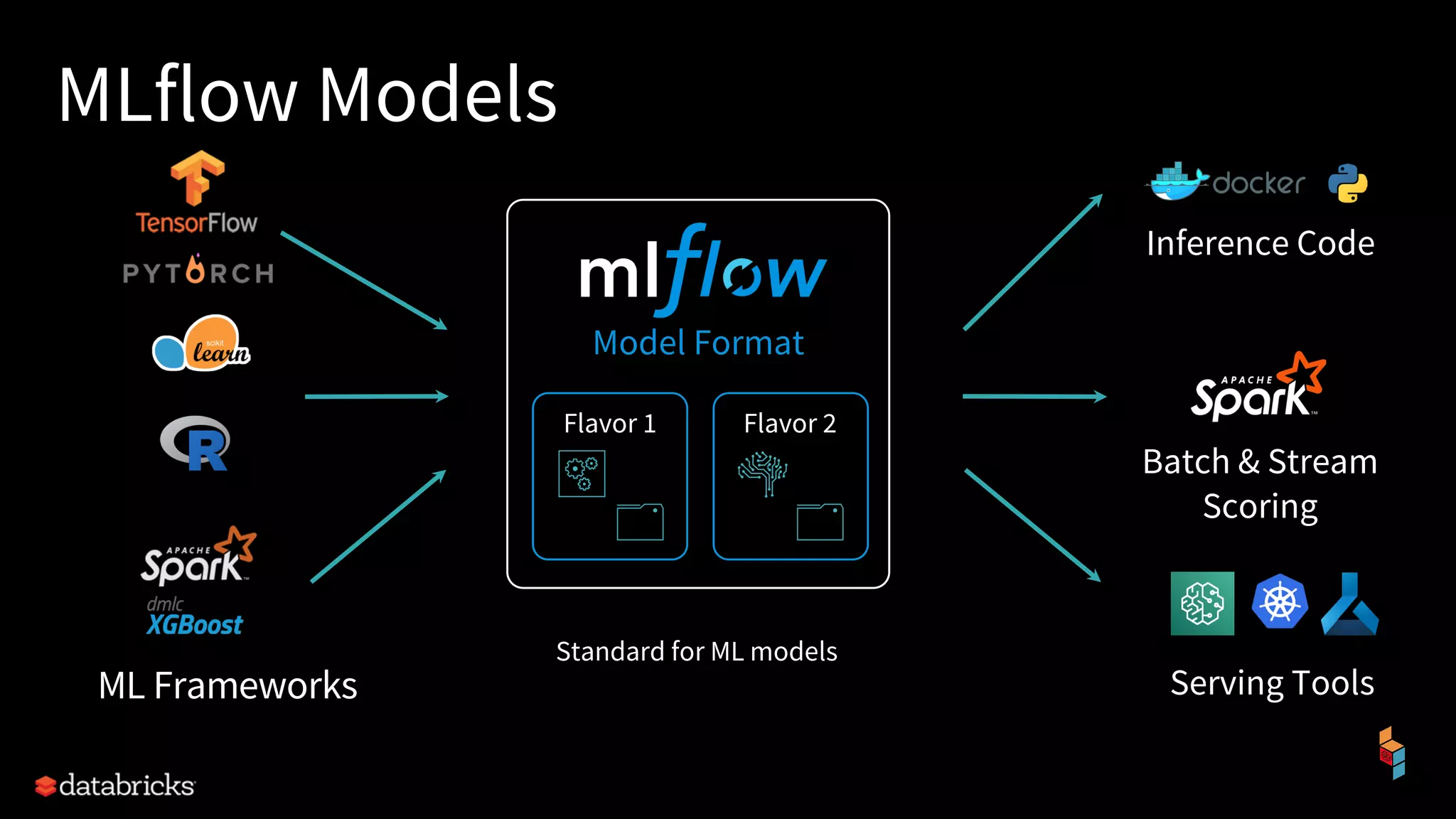
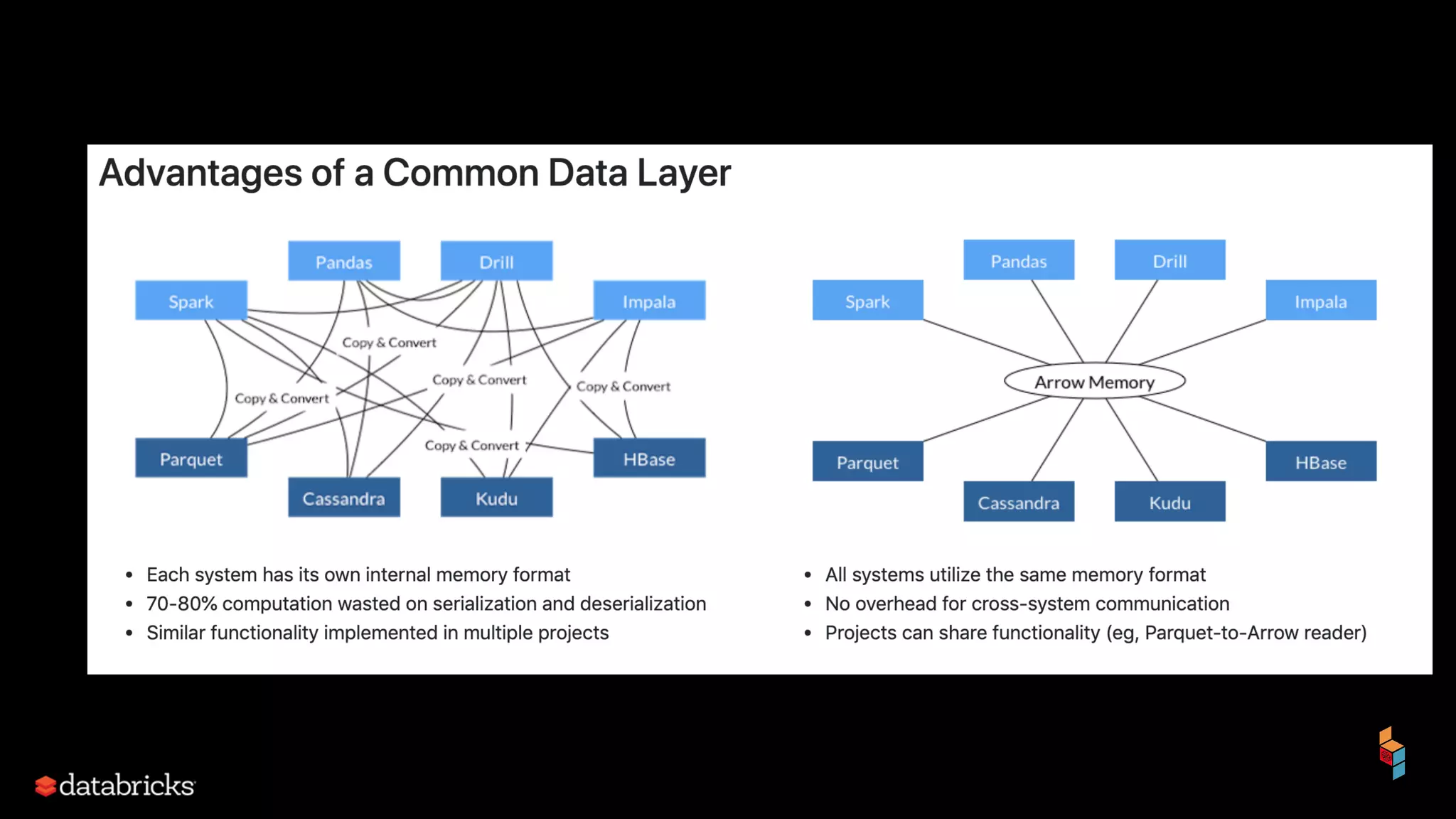

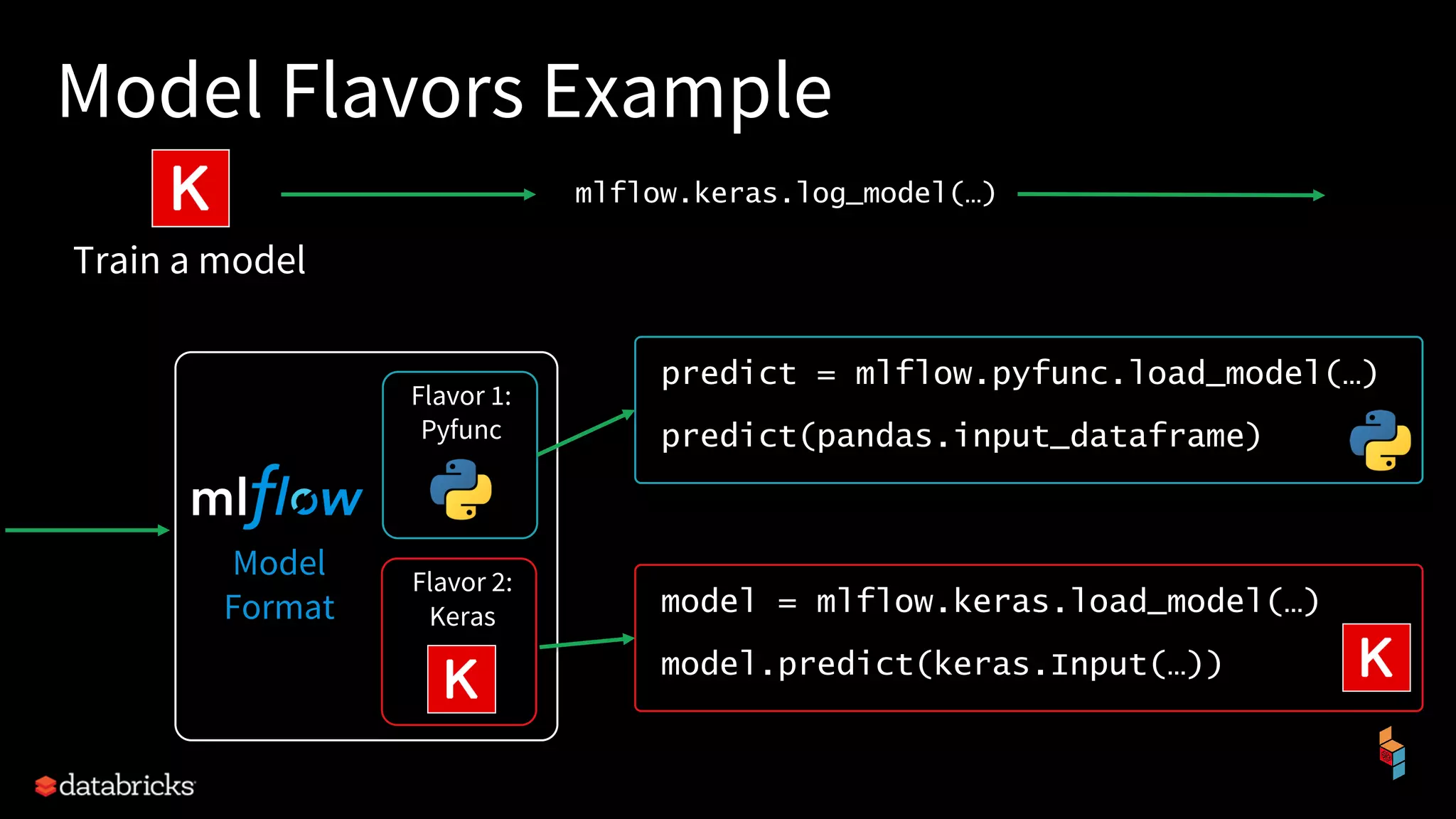
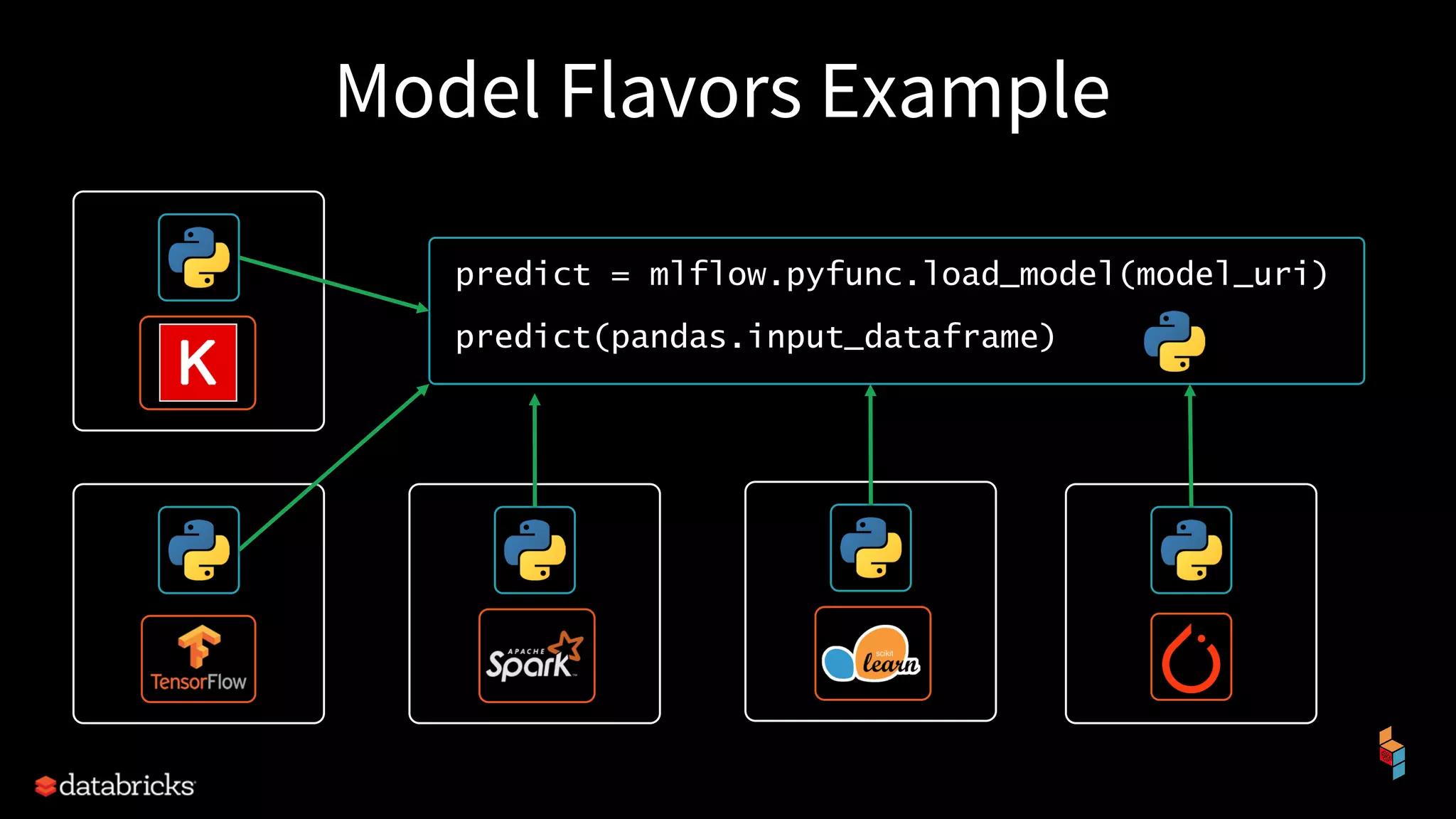
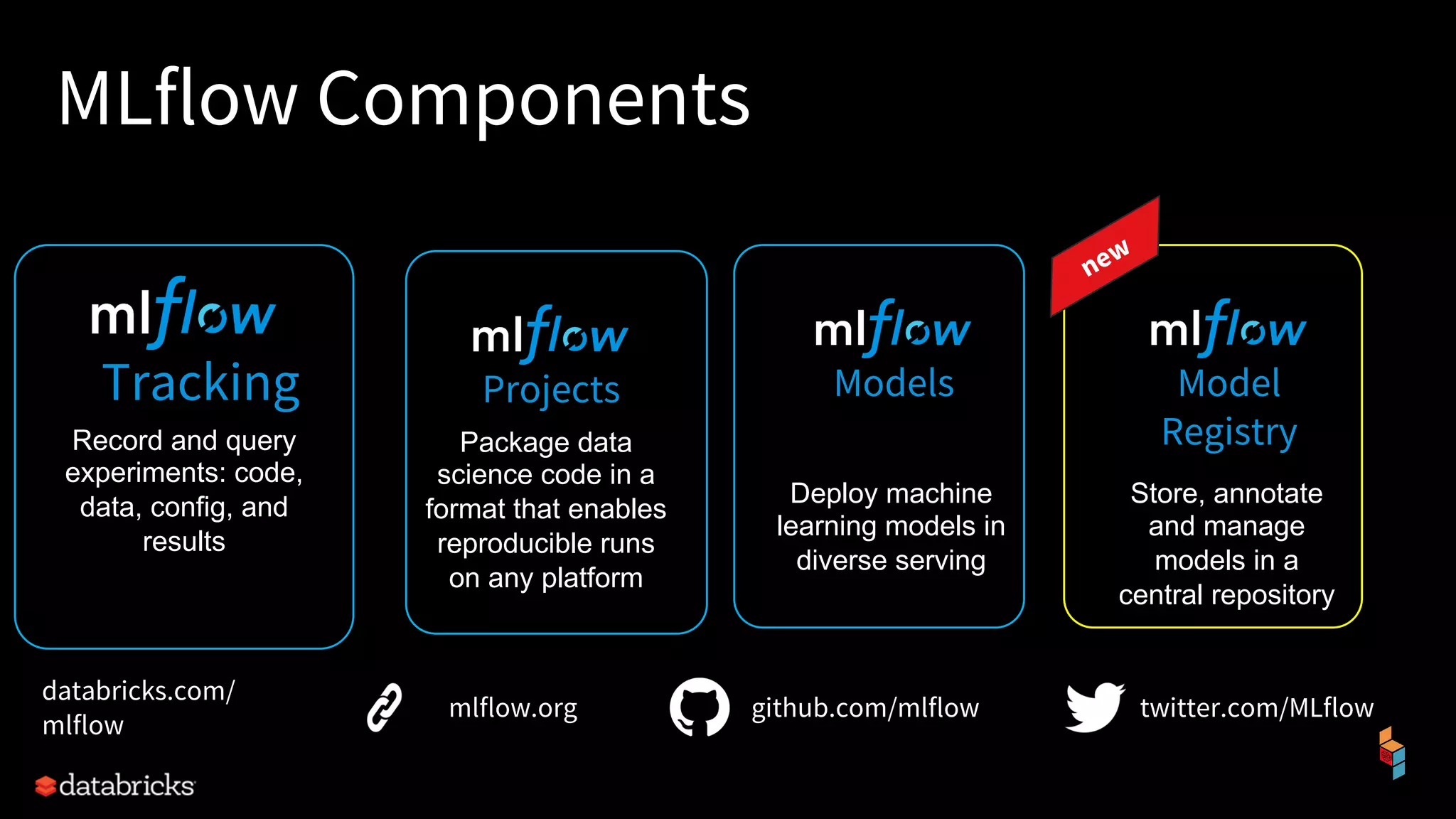


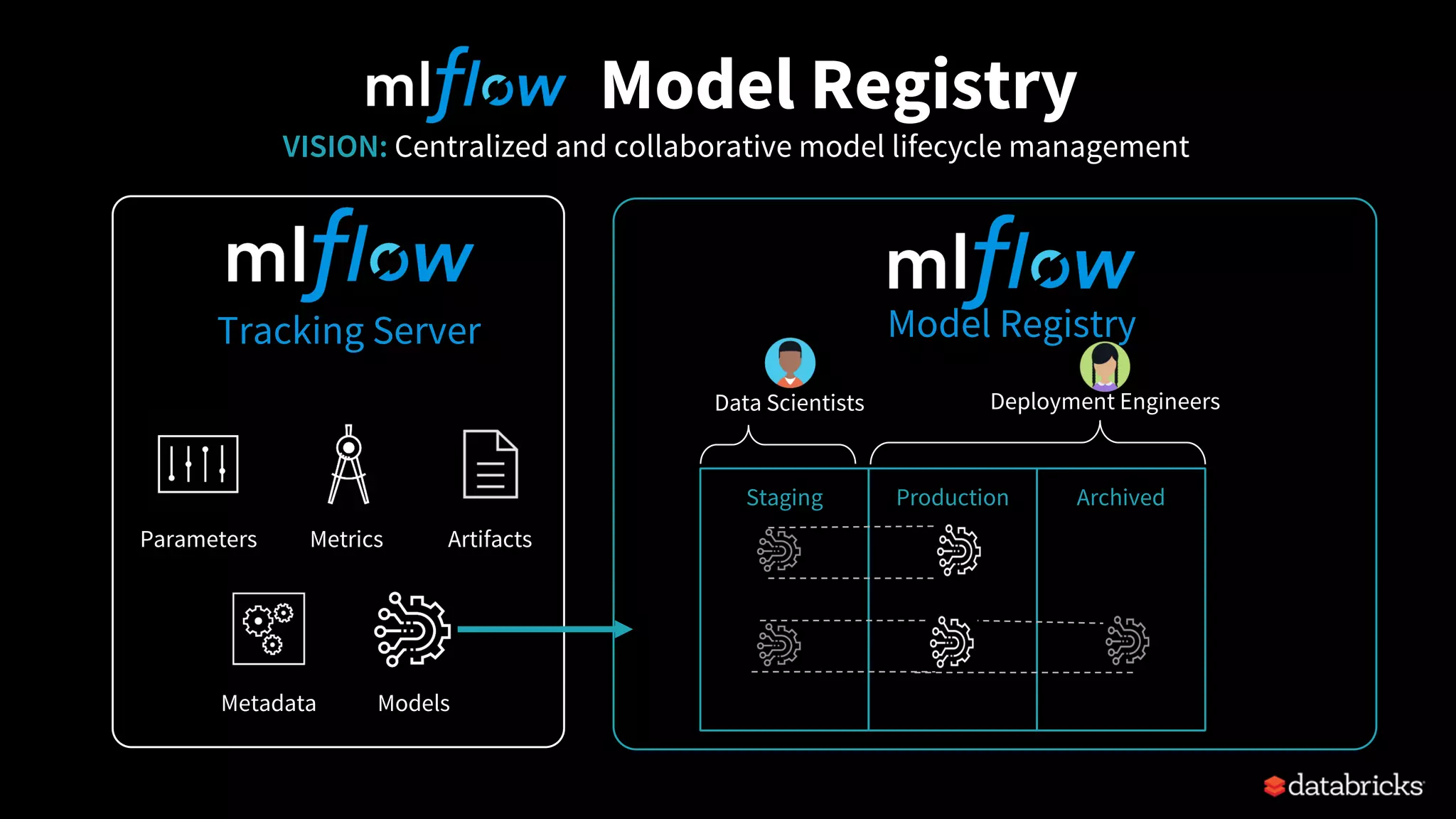

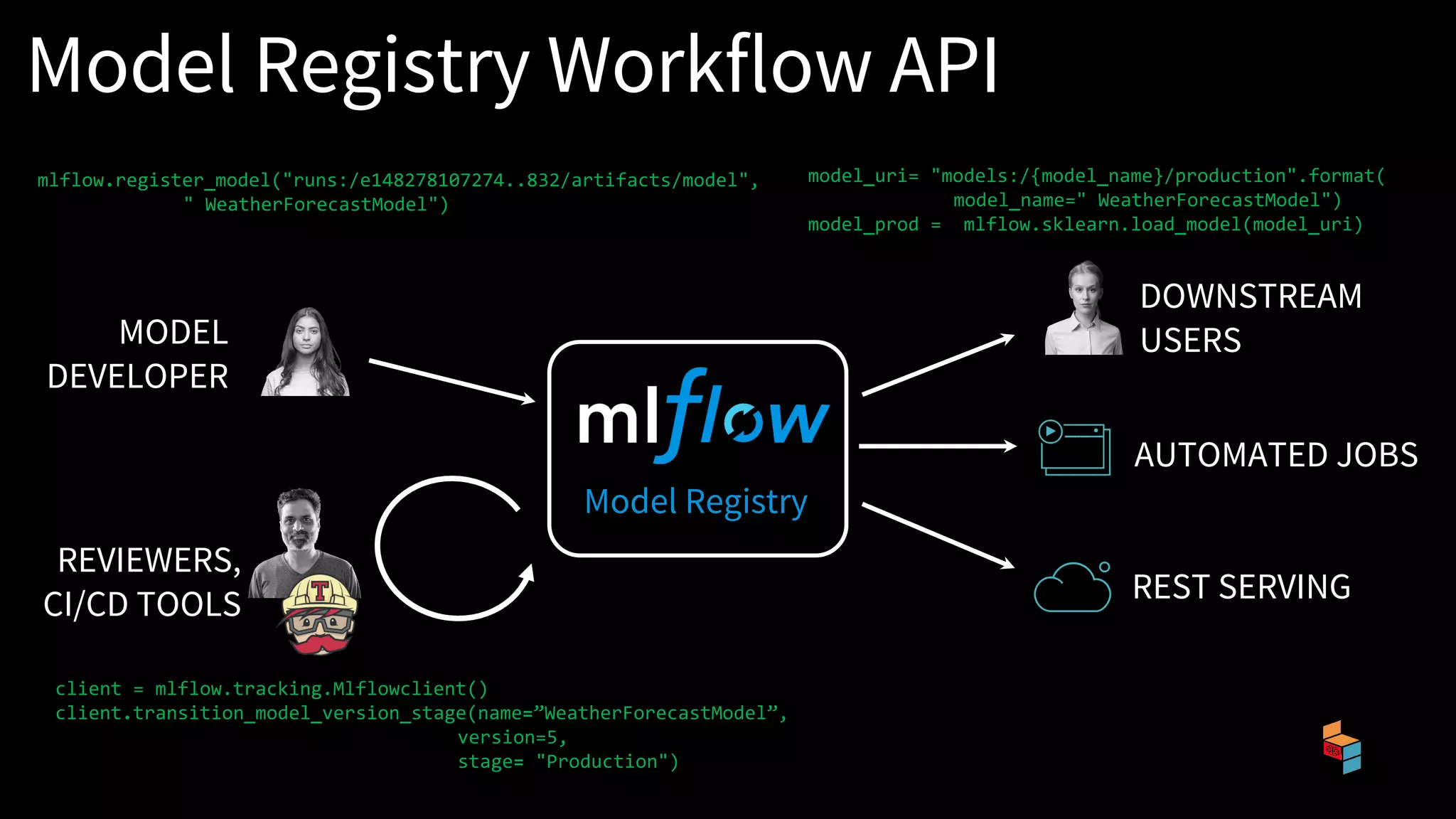

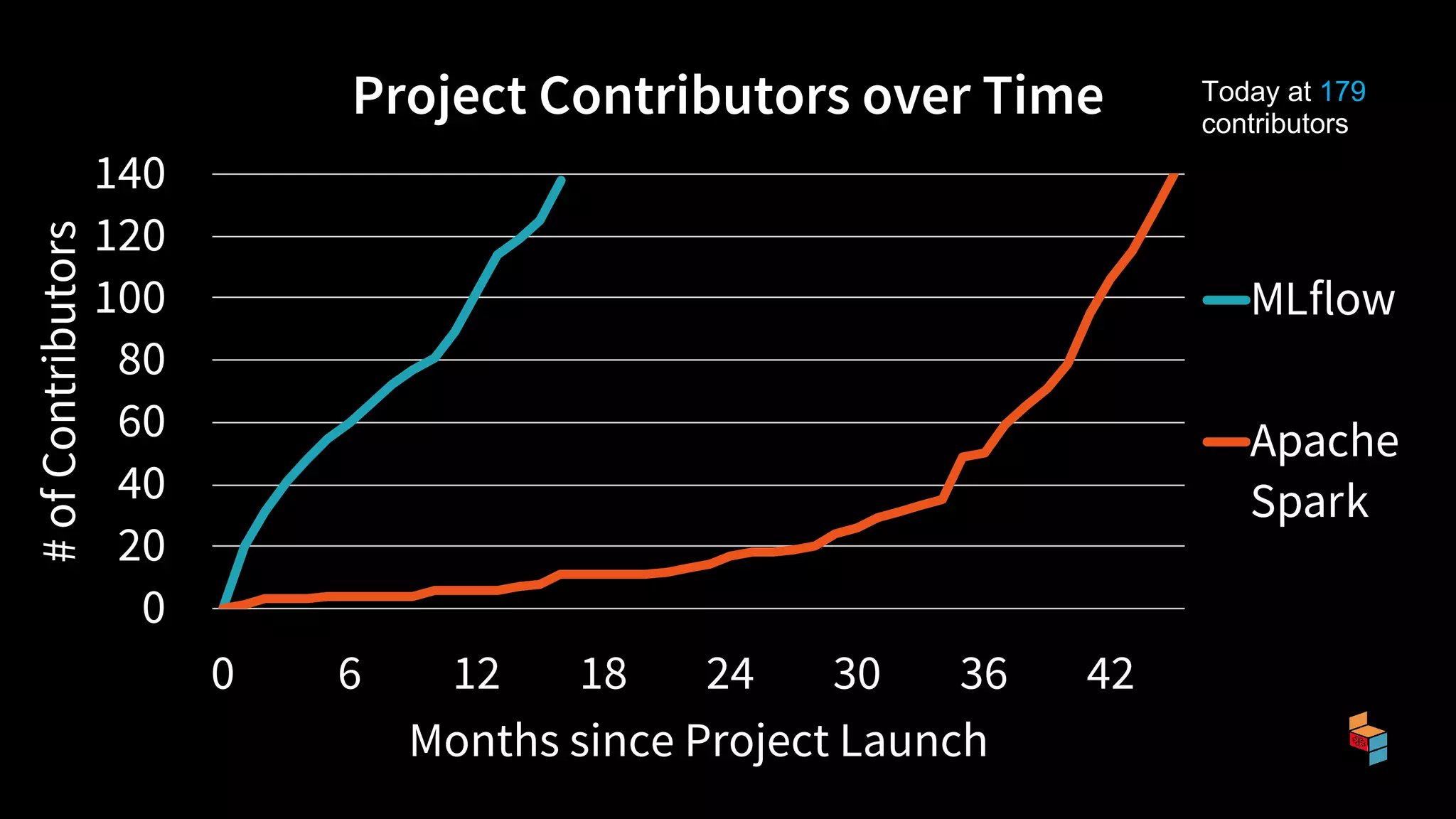




The document discusses the challenges of machine learning (ML) development and introduces MLflow, an open platform designed to streamline the entire ML lifecycle. It explains MLflow's modular components, including tracking experiments, packaging code, deploying models, and managing model registries, allowing for reproducibility across different environments. The document emphasizes the importance of collaboration and accessibility for teams of all sizes in the field of data science and engineering.























































































