






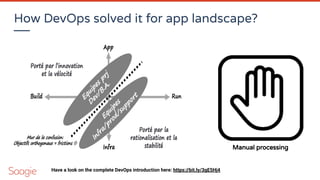
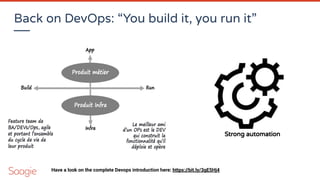



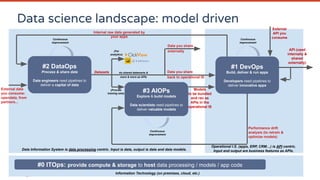





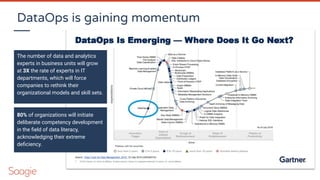

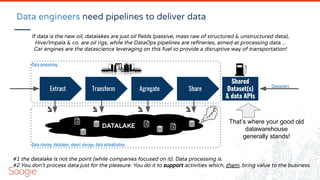
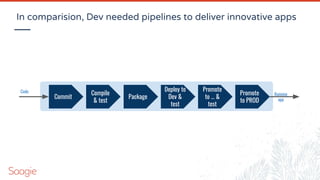
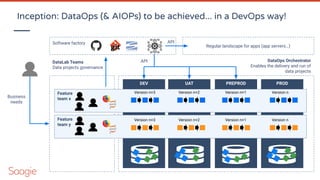


![Matrix organization & serendipity
This matrix organization (transversal datasets owned by the Datahub, securely shared to several isolated
usecases) enable to factorize the work (so raise your dataset ROI). Each time a usecase team needs a new
dataset, it should be capitalized by integratin the data catalog owned by the datahub (see the central team’s
value ?)
Serendipity: by having a clear understanding of your data patrimony, you can valorize it of course, but it may
also help to give new ideas! “Since I’ve this data, and this one, so I may be able to [your_new_idea_here]”
“If only HP knew what HP knows, we'd be three times more productive”
- Lew Platt, former CEO of Hewlett-Packard
Dataset #1 Dataset #2 Dataset #3 Dataset #4
Usecase #1
Usecase #2
Usecase #3
Data Catalog](https://image.slidesharecdn.com/webinardataops-200804101136/85/Introdution-to-Dataops-and-AIOps-or-MLOps-39-320.jpg)

![Data engineering vs Data Science
[80%]
of a data project is roughly about
data aquisition/preparation/sharing
(data engineering)
[20%]
of a data project is roughly about
data valorization
(data science, data analytics)
→ Your datascientists generally spend most of their time at doing data engineering empirically
when a clear data engineer position doesn’t exist in your organization!
- It’s not very efficient (as datascientists costs much more than data engineers and are difficult to hire)
- They generally doesn’t like this activity (and may leave your company at the end!)
- Happens regularly: two datascientists using same data for different usecases will probably create 2 identical
ingestion/preparation pipelines for their projects (you miss a factorization effect)](https://image.slidesharecdn.com/webinardataops-200804101136/85/Introdution-to-Dataops-and-AIOps-or-MLOps-41-320.jpg)







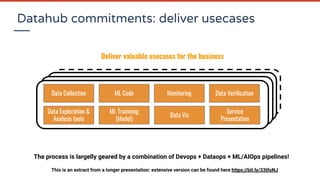
The document discusses DataOps and AIOps (or MLOps) in the context of operationalizing data projects for organizations, emphasizing the need for improved collaboration between data engineers and data scientists. It outlines various challenges in delivering value from big data and AI, including fragmented technologies, organizational silos, and the importance of establishing effective processes and governance. The presentation also highlights the significance of using data pipelines and automation to enhance data management and promote quicker, more predictable delivery of data-driven insights.




































![[DSC Europe 24] Josip Saban - Buidling cloud data platforms in enterprises](https://cdn.slidesharecdn.com/ss_thumbnails/josipsaban-buidlingclouddataplatformsinenterprises-250217194546-5568421d-thumbnail.jpg?width=640&height=640&fit=bounds)

















![Docker, cornerstone of cloud hybridation ? [Cloud Expo Europe 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/dockercloudhybridationv2-161129152507-thumbnail.jpg?width=640&height=640&fit=bounds)
































