Download as PDF, PPTX



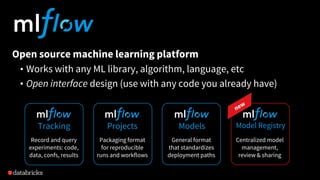


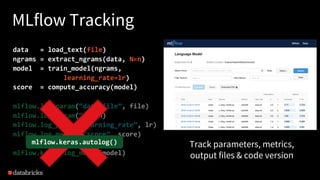

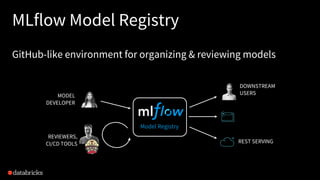







The document discusses the differences between production machine learning and ML research, emphasizing the need for continuous deployment, monitoring, and retraining to solve business problems. It introduces an open-source machine learning platform, MLflow, that facilitates reproducibility, model management, and integrates with various machine learning libraries and tools. Additionally, it highlights use cases for MLflow, showcasing its capabilities in managing numerous independent models and analyzing training results.



































































