Download as PDF, PPTX








![Coefficient of Range
Coefficient of Range = [L-S]/[L+S]
Where,
L = Largest value in the data set
S = Smallest value in the data set](https://image.slidesharecdn.com/measuresofdispersiondiscuss2-200111101318/75/Measures-of-dispersion-discuss-2-2-10-2048.jpg)

![Coefficient of QD
Coefficient of QD= [Q3-Q1]/[Q3+Q1]](https://image.slidesharecdn.com/measuresofdispersiondiscuss2-200111101318/75/Measures-of-dispersion-discuss-2-2-13-2048.jpg)

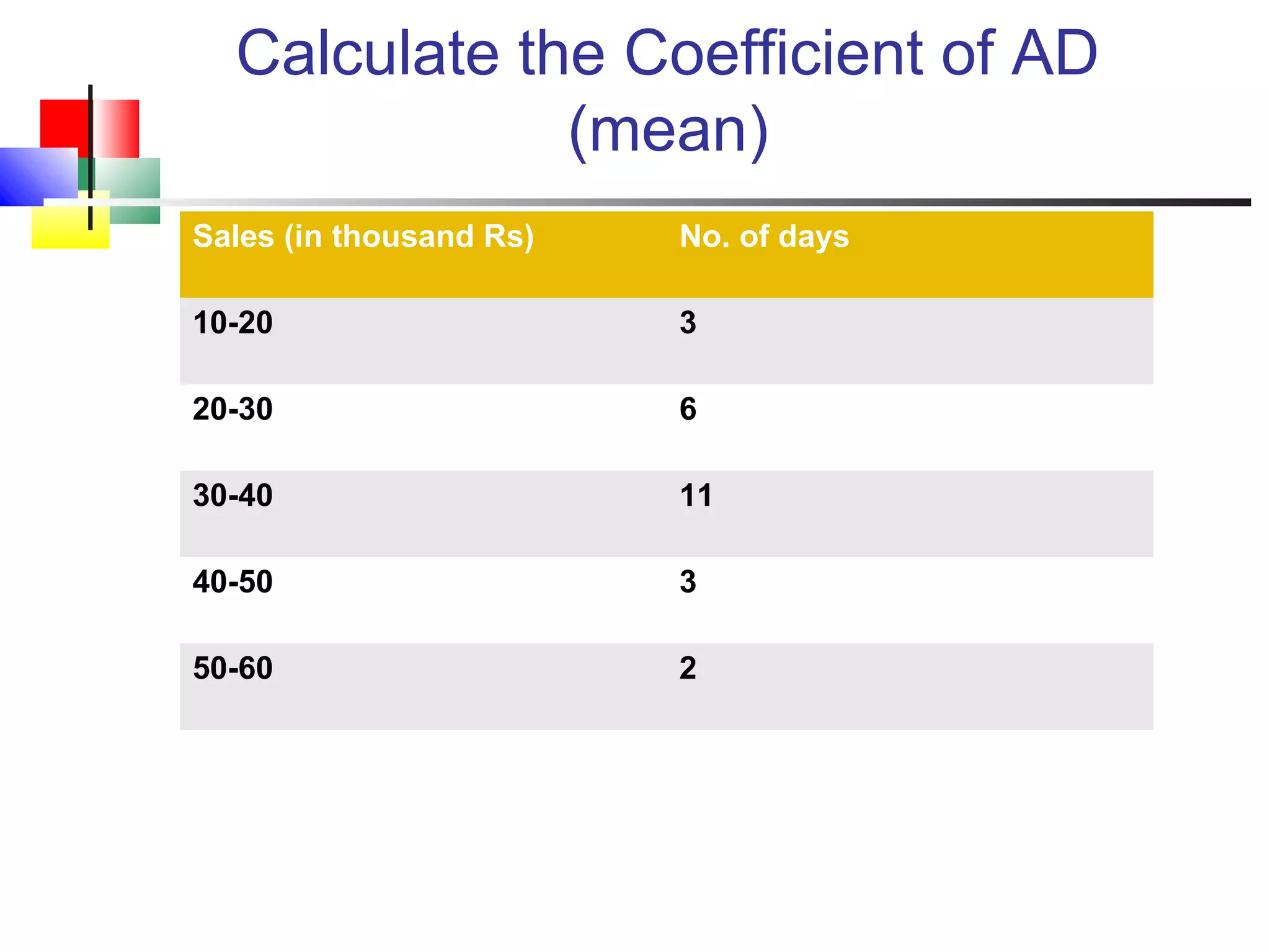





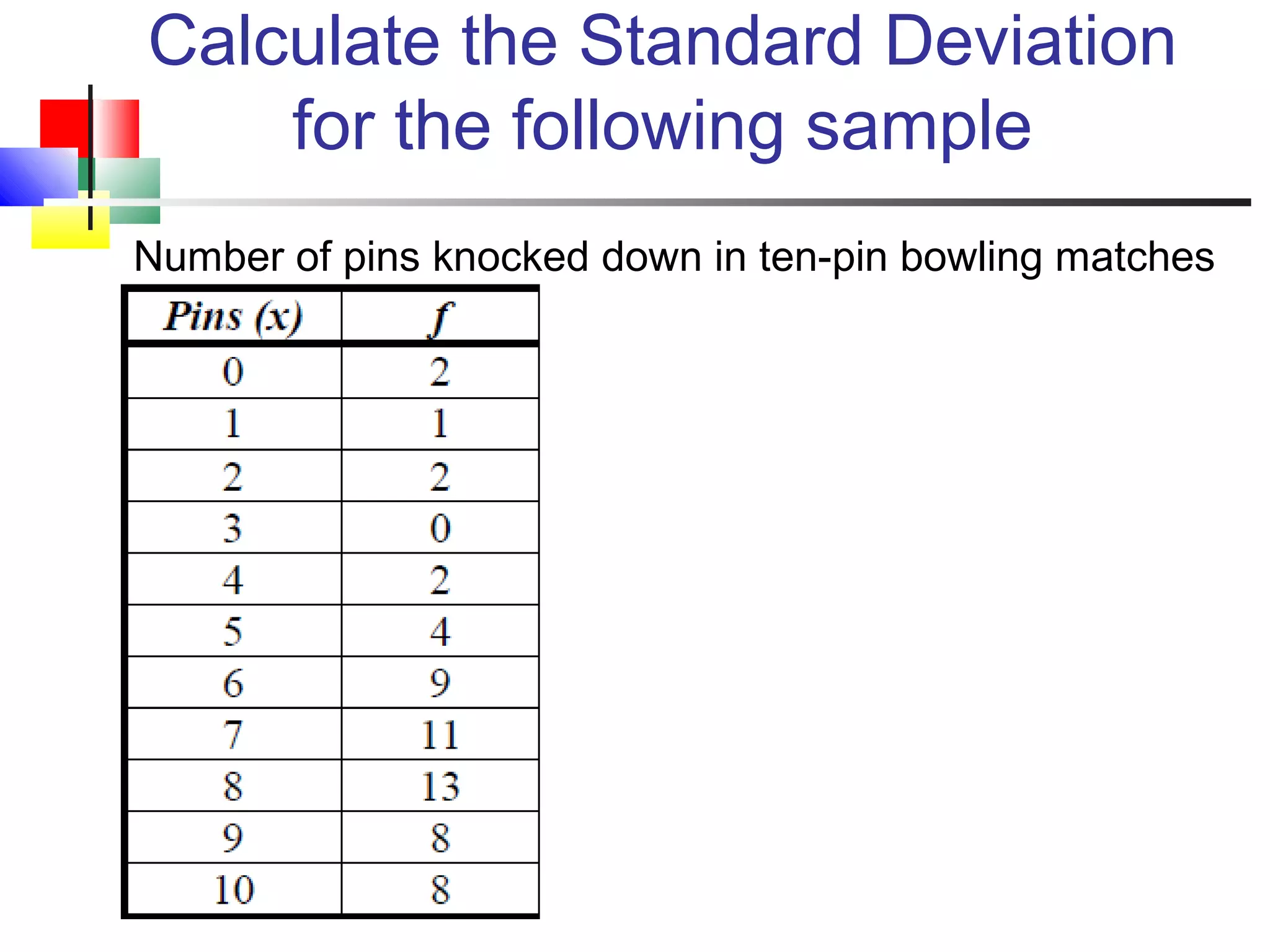
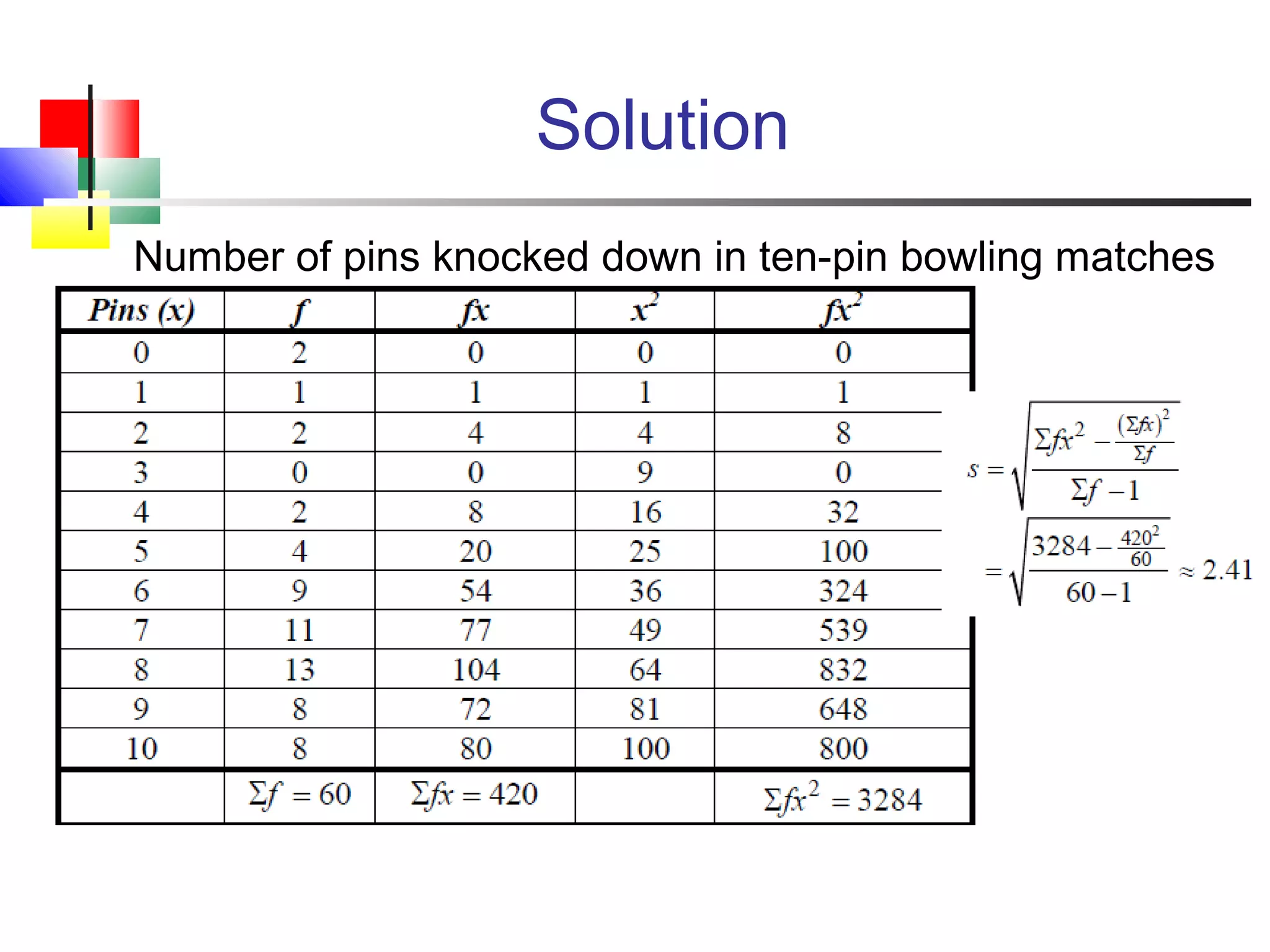
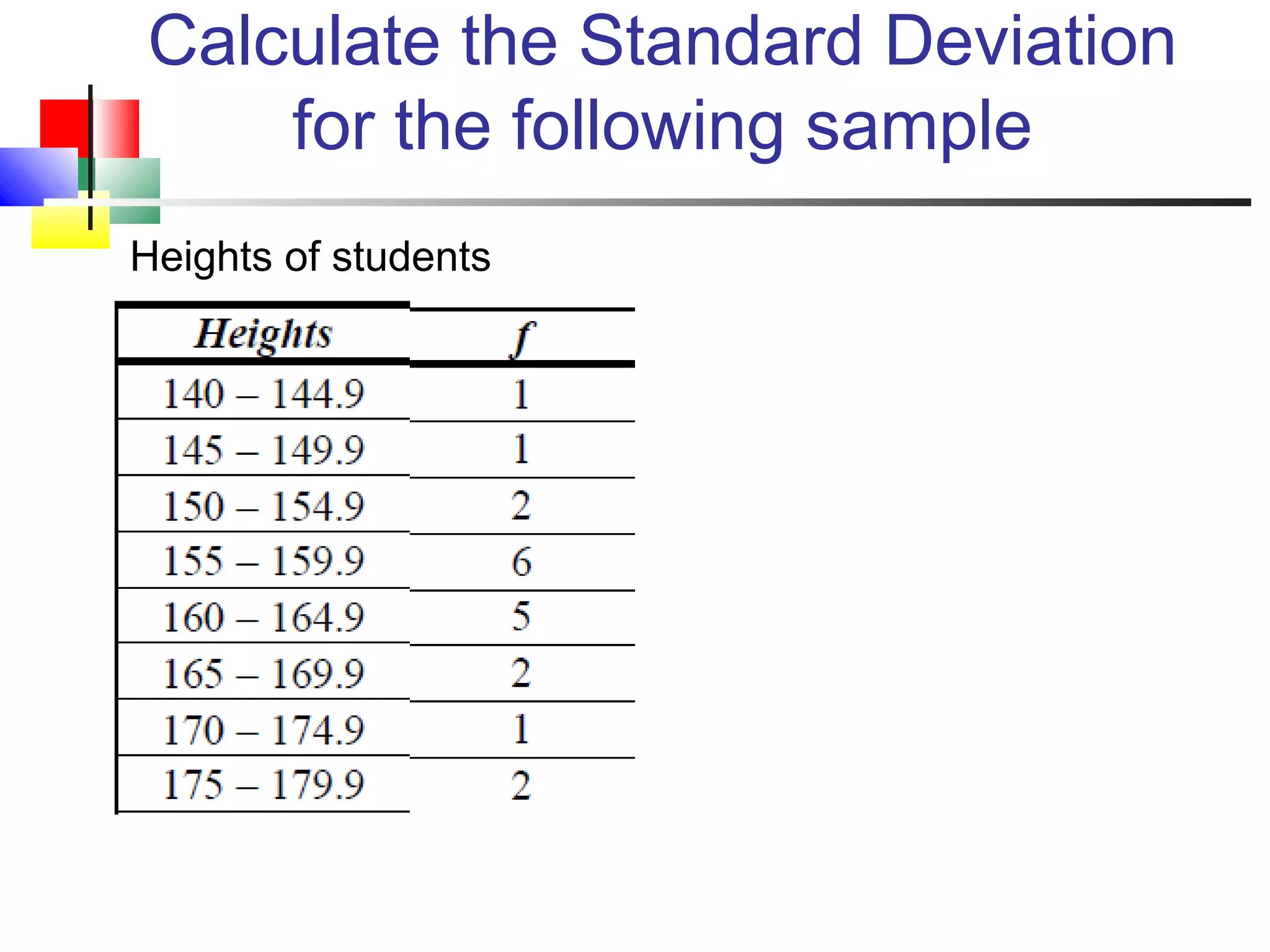
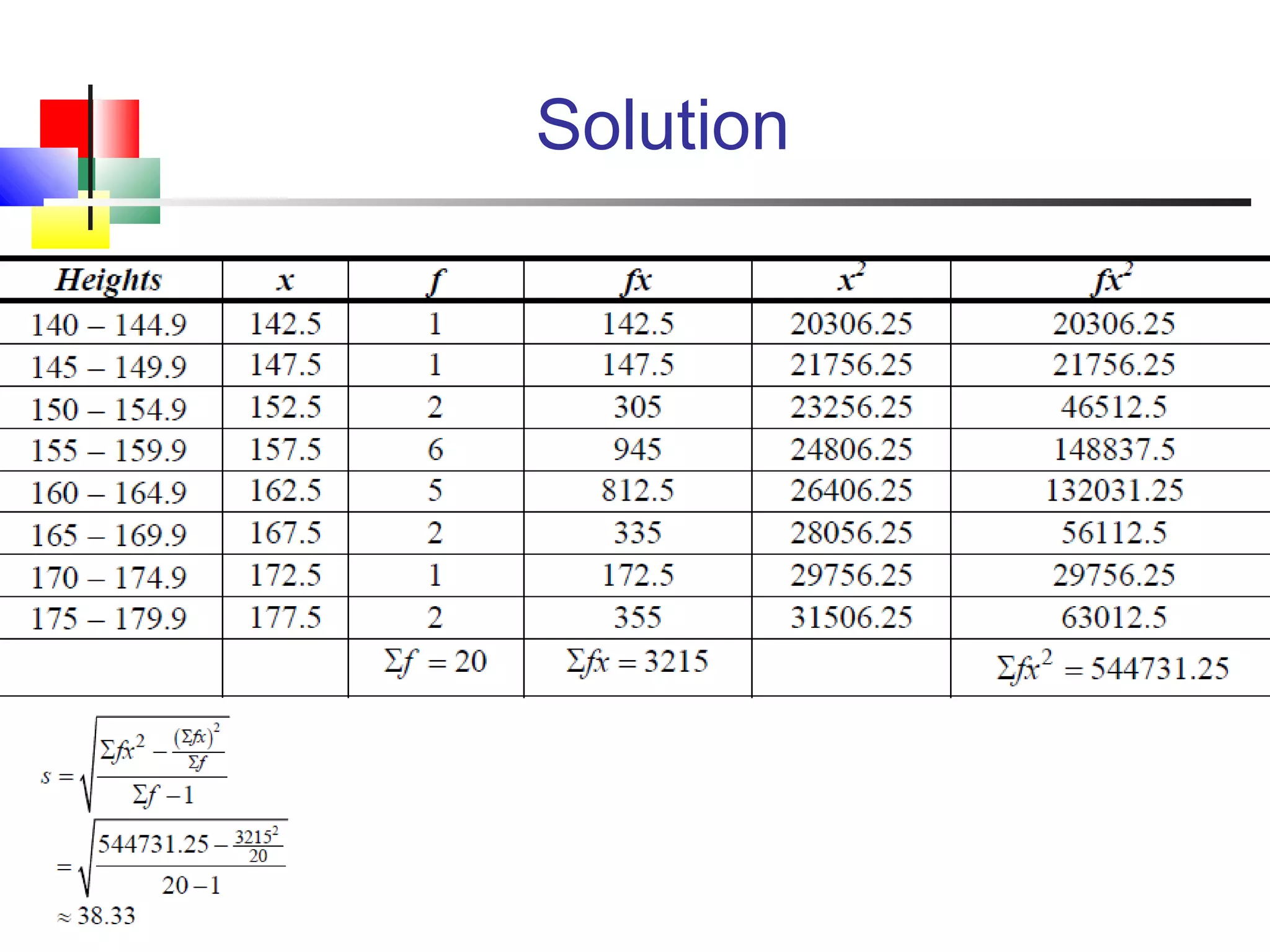
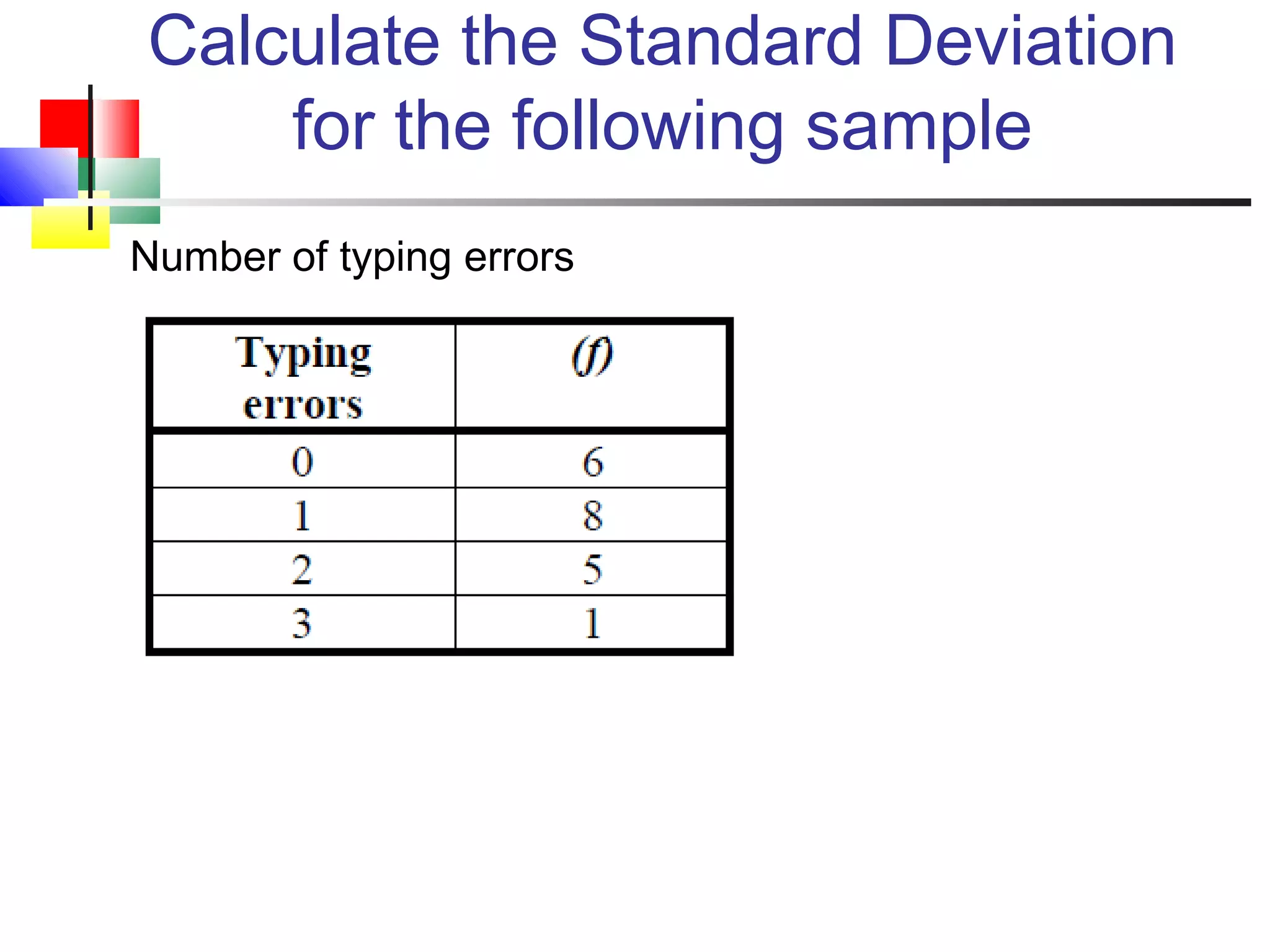
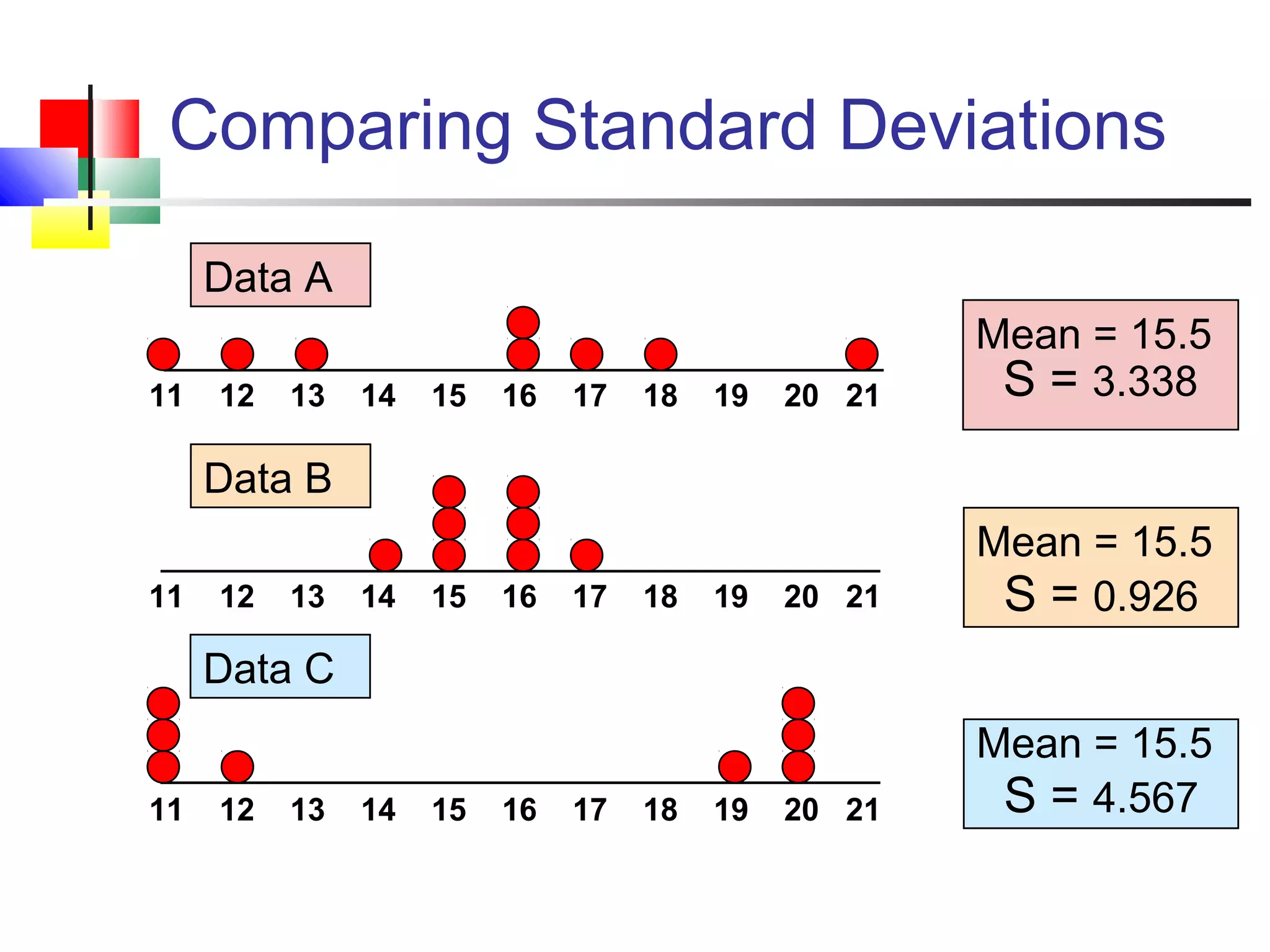
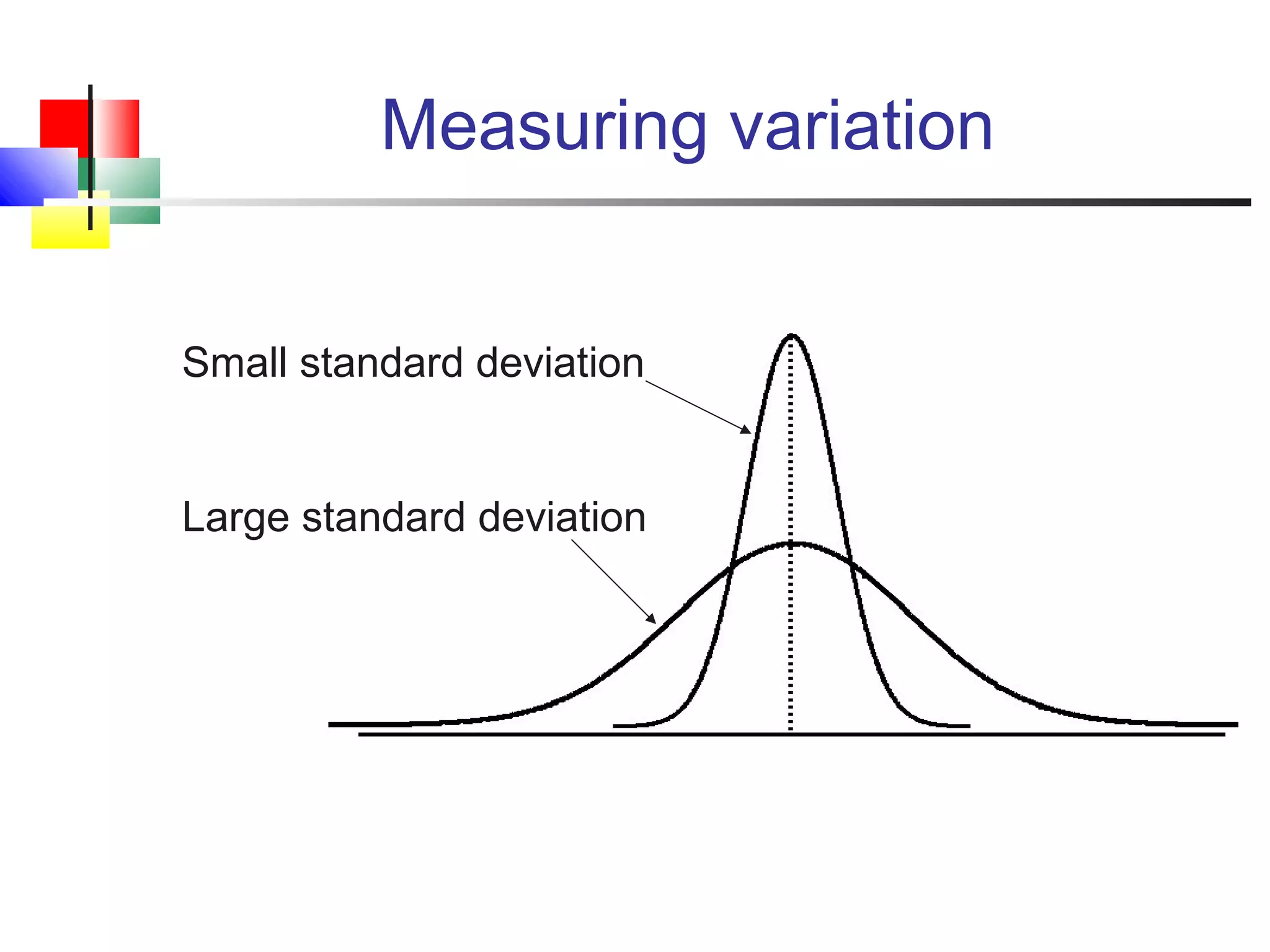






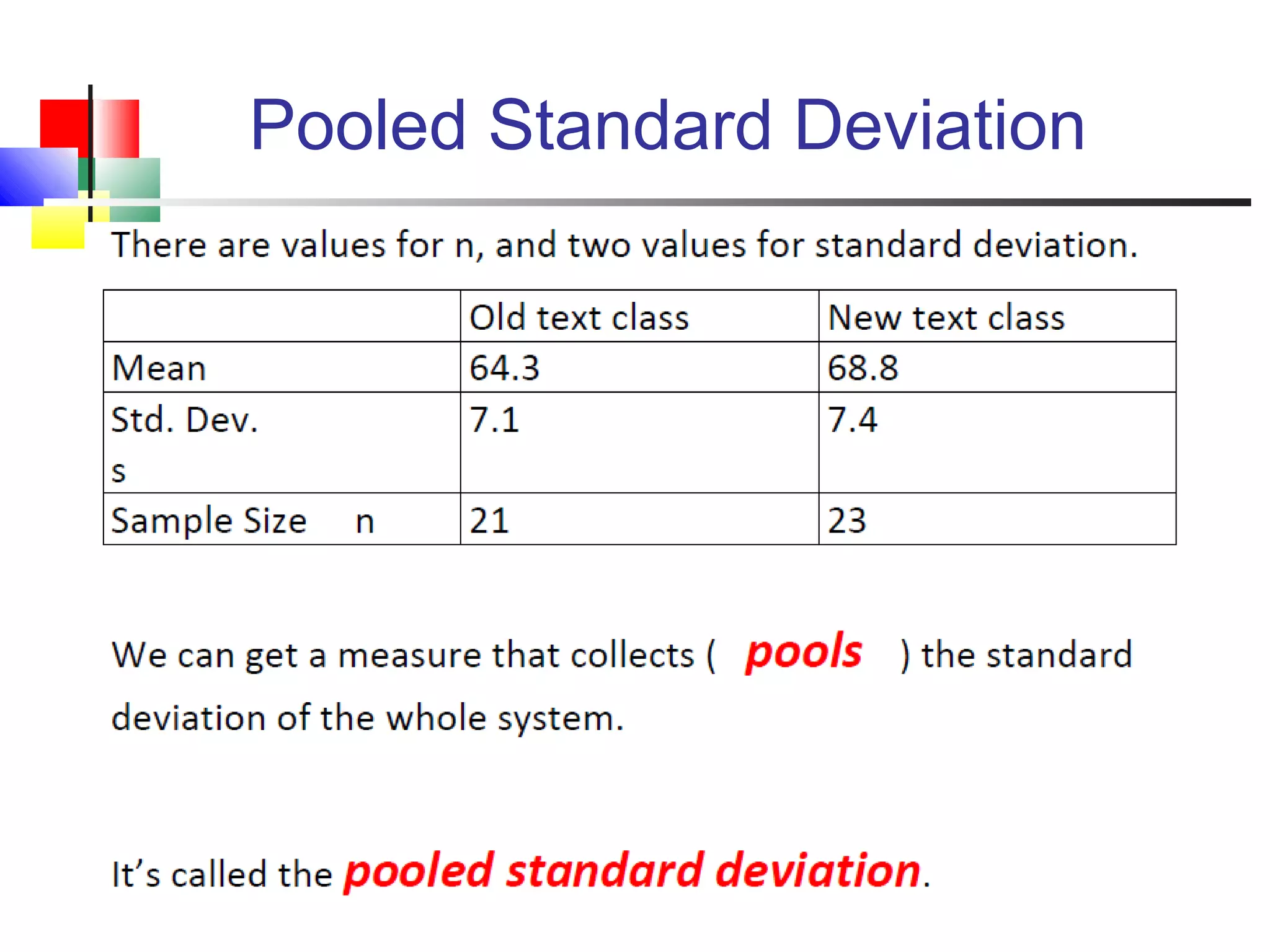



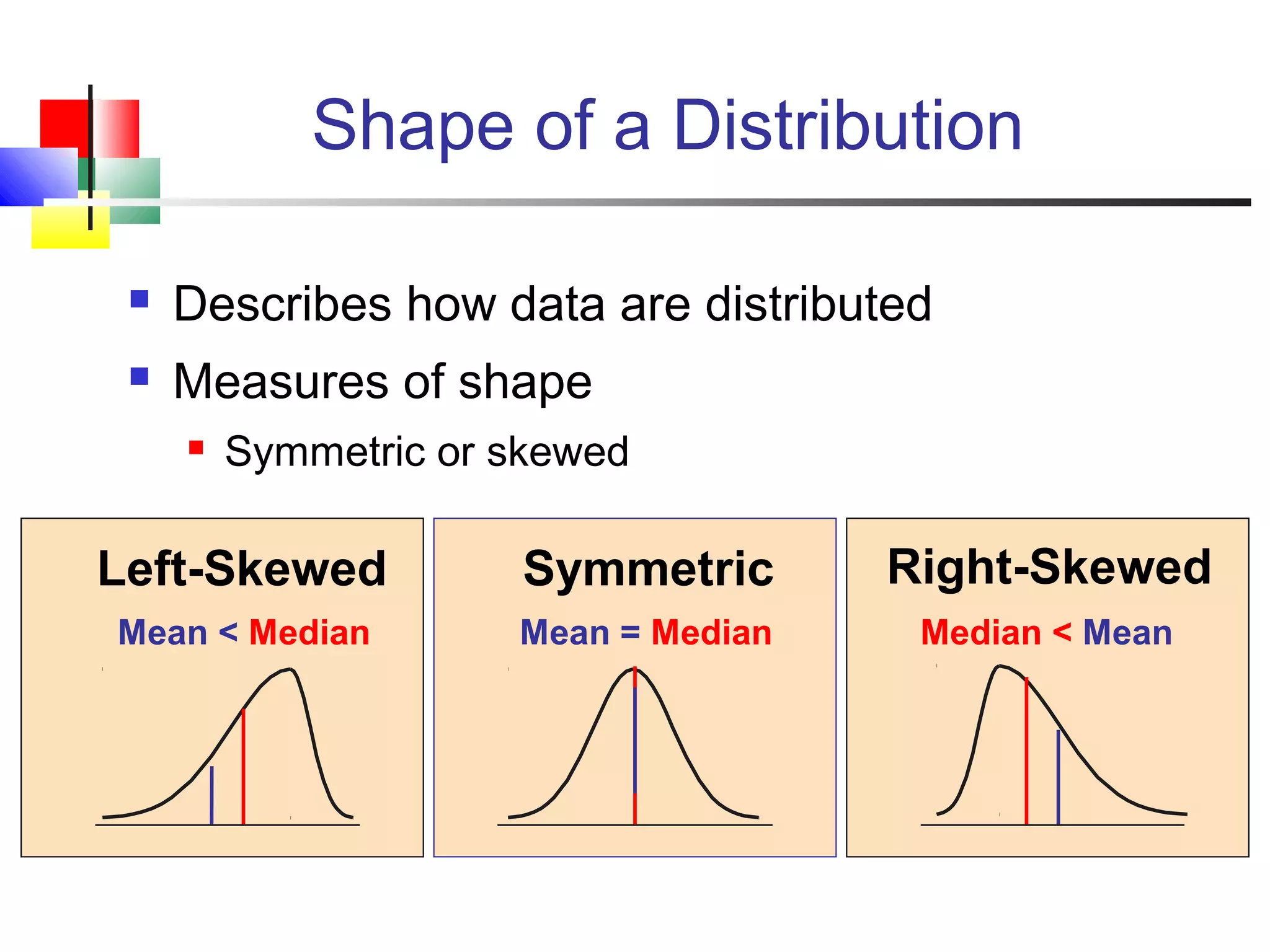
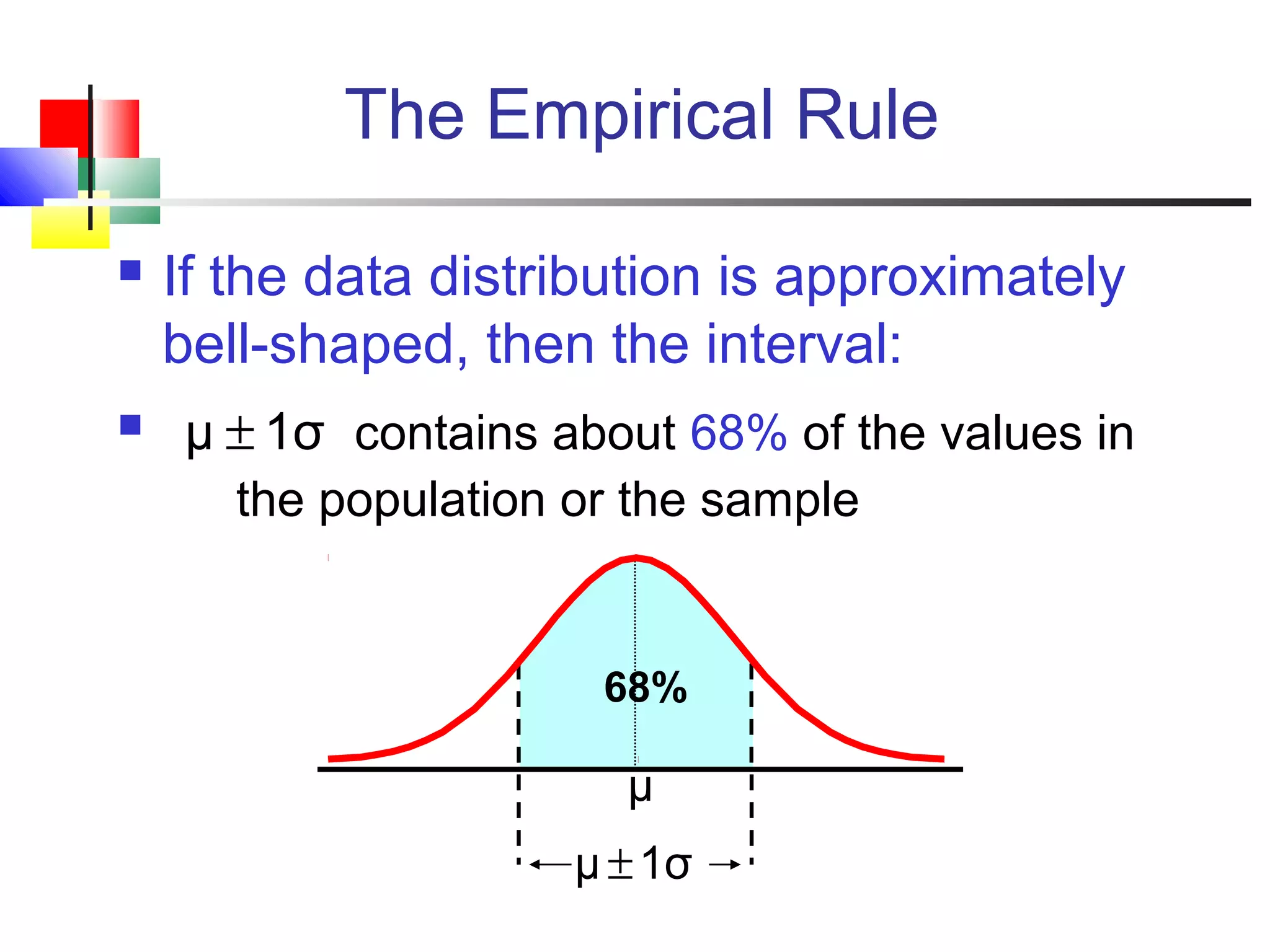

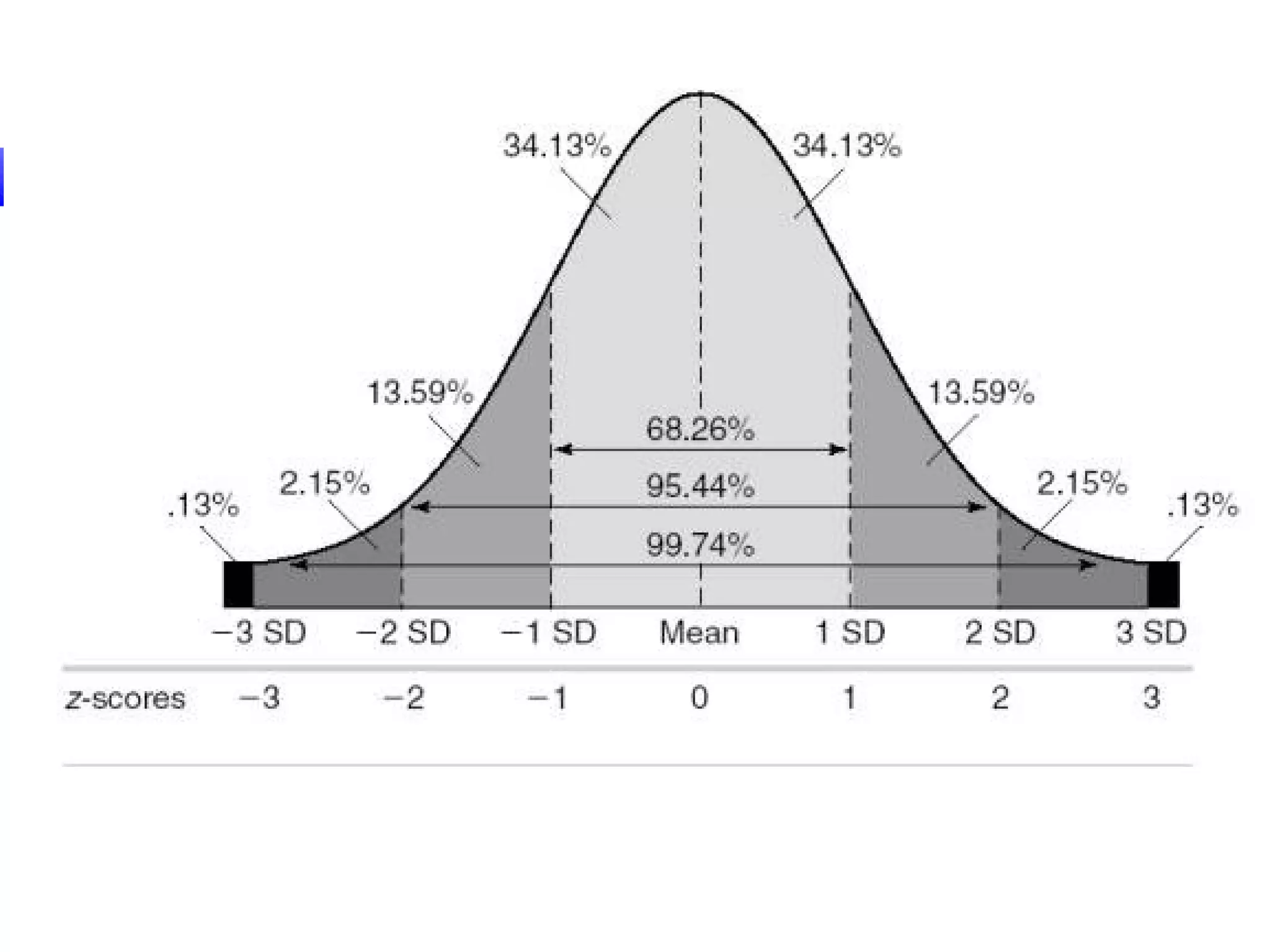

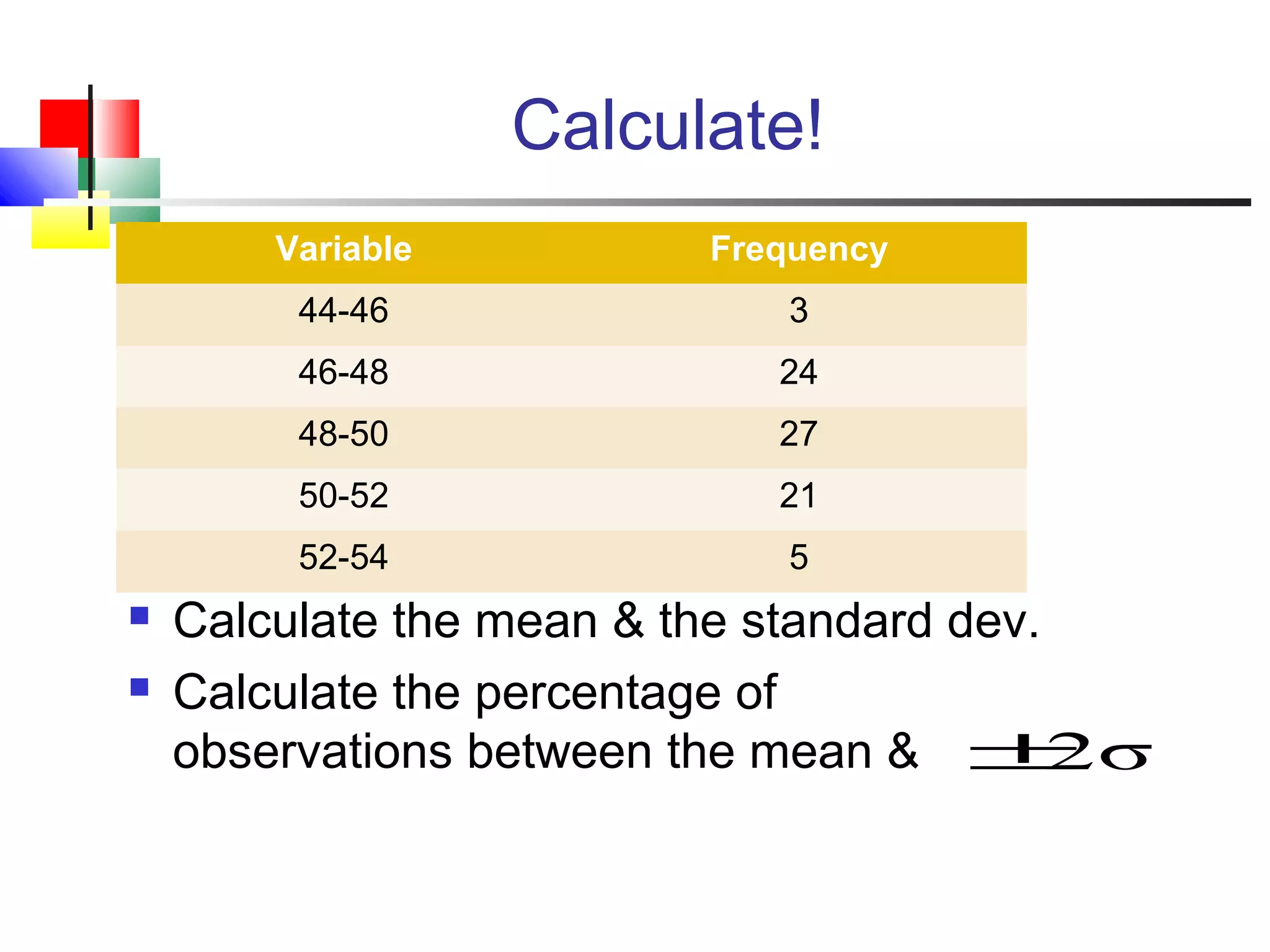




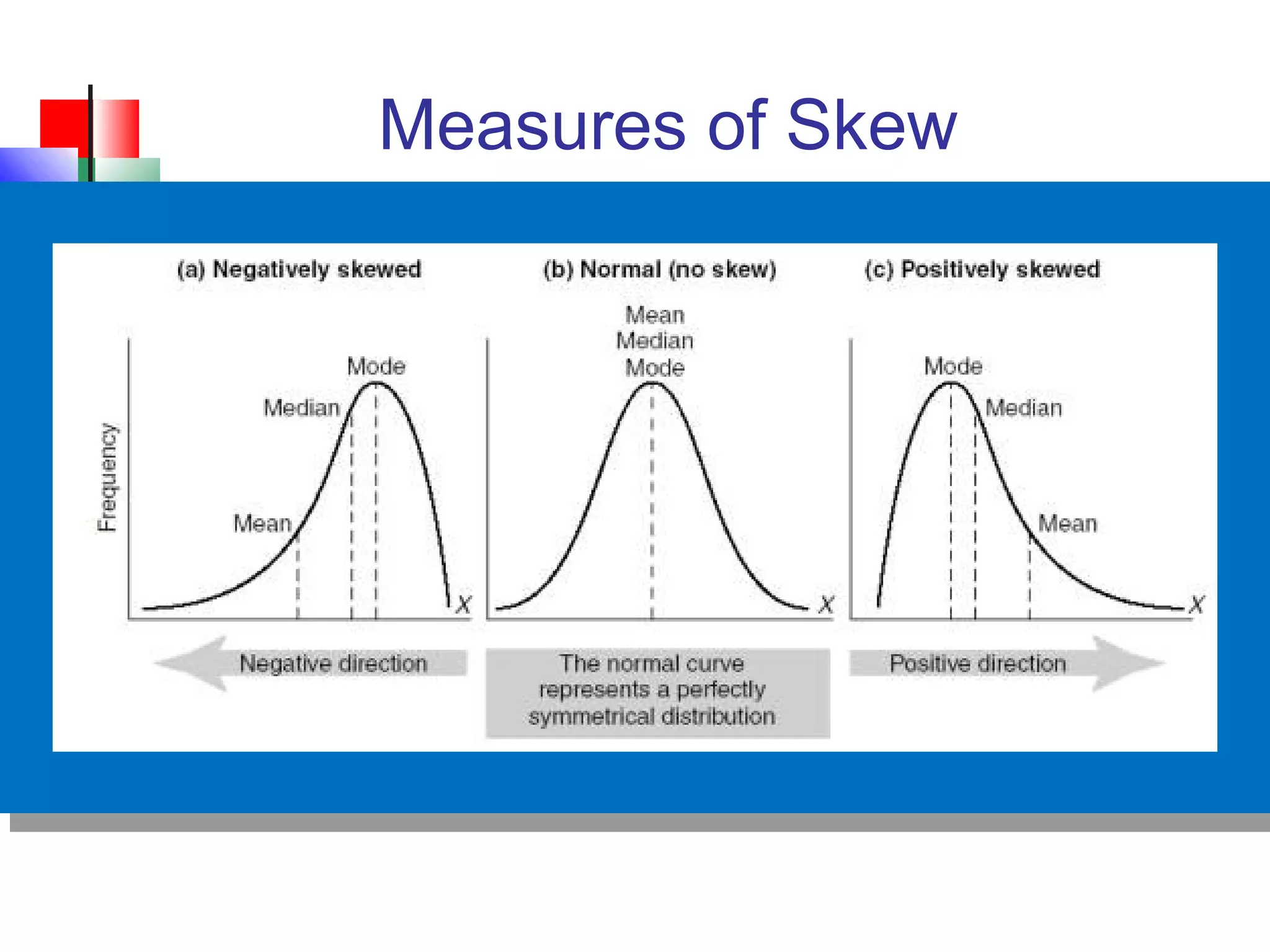




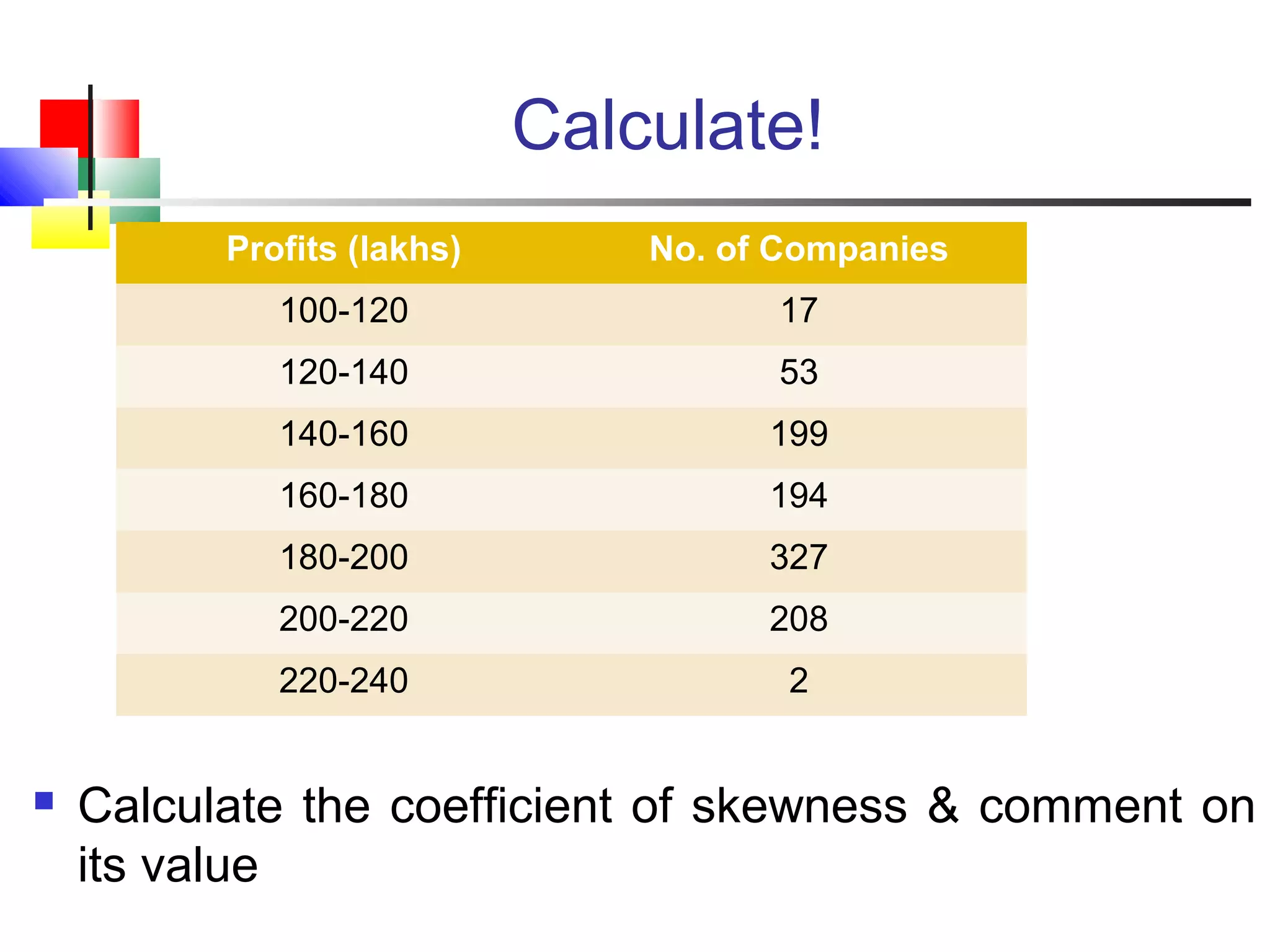




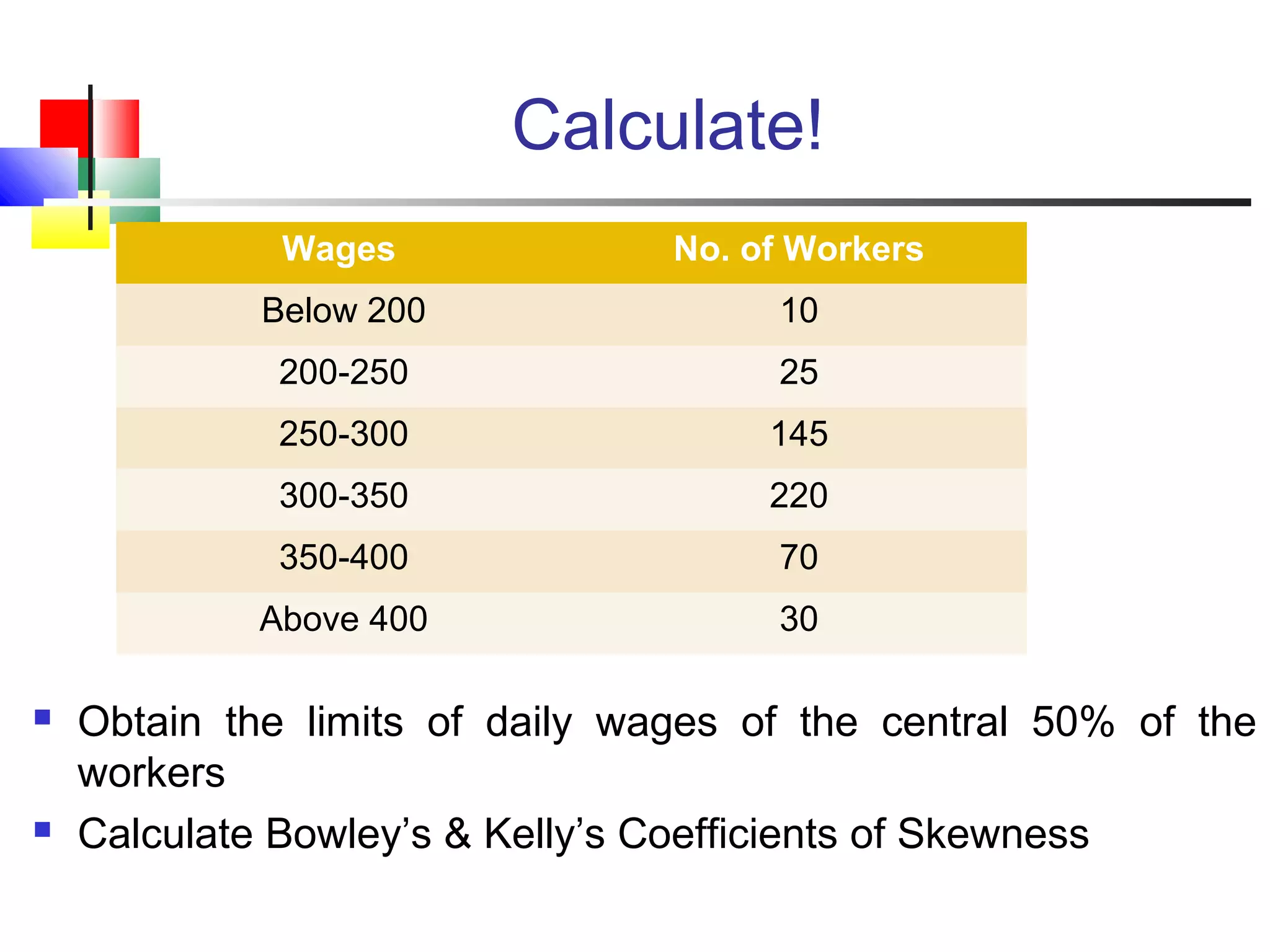


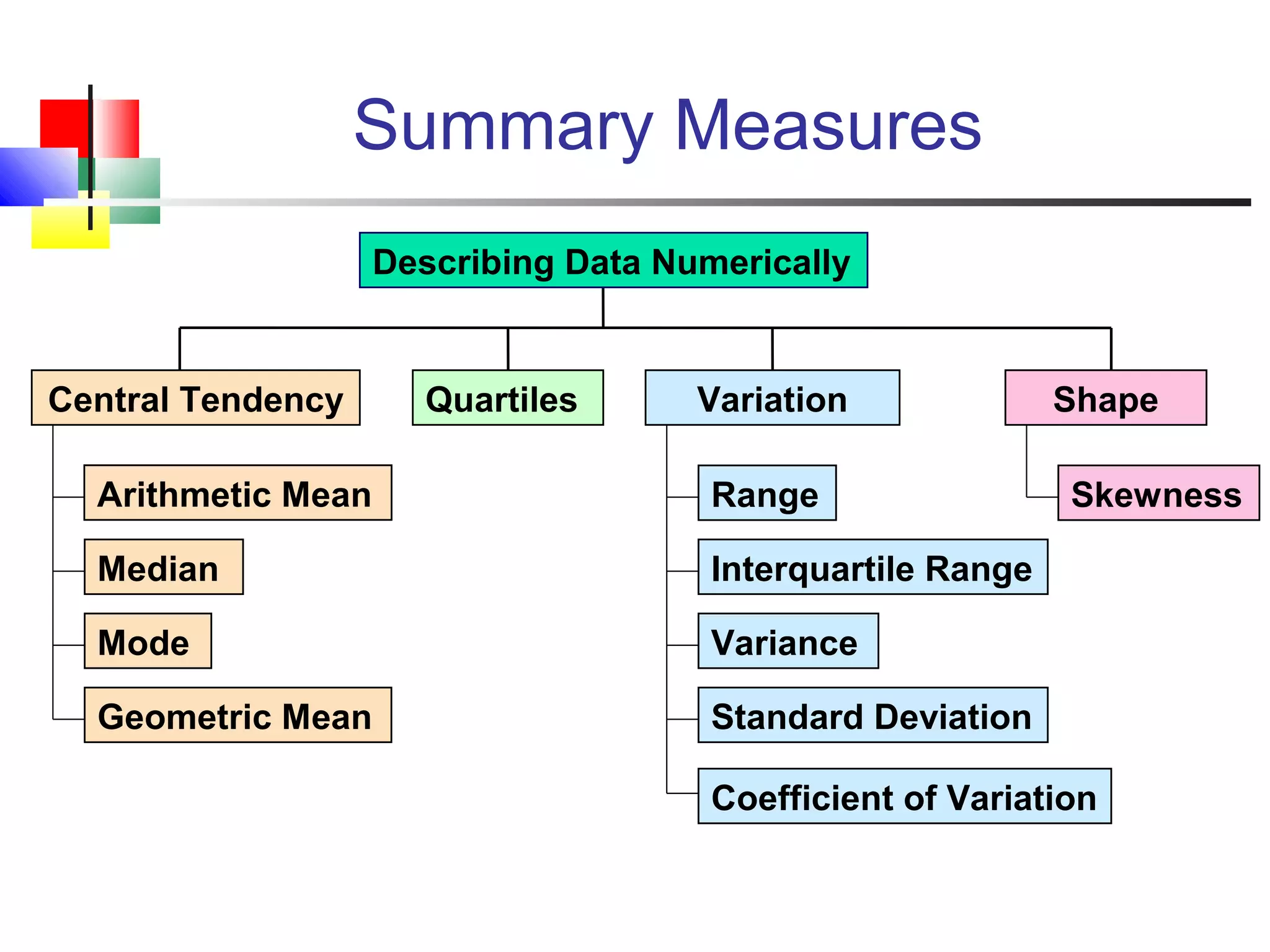
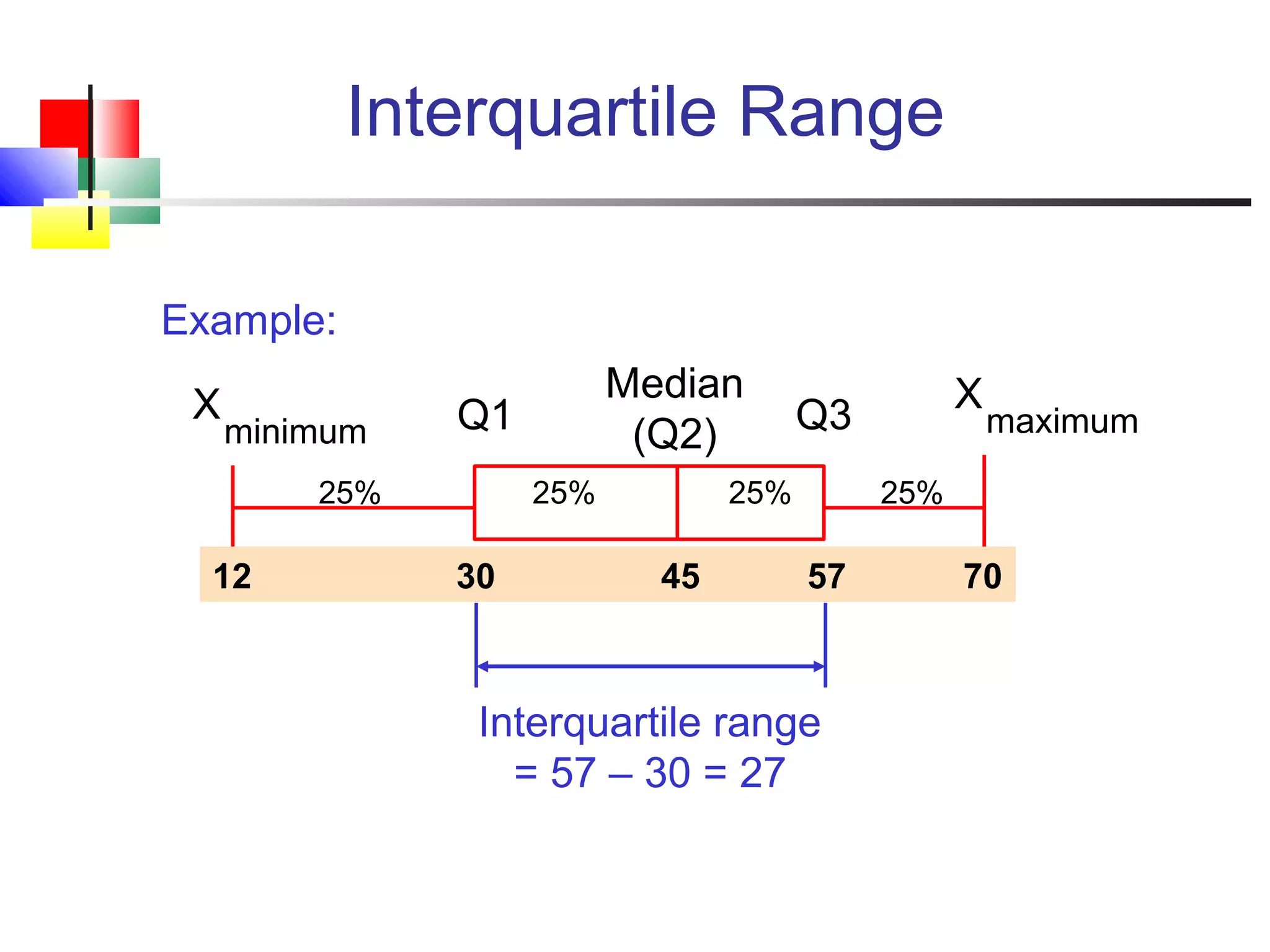
The document discusses various measures of central tendency, dispersion, and shape used to describe data numerically. It defines terms like mean, median, mode, variance, standard deviation, coefficient of variation, range, interquartile range, skewness, and quartiles. It provides formulas and examples of how to calculate these measures from data sets. The document also discusses concepts like normal distribution, empirical rule, and how measures of central tendency and dispersion do not provide information about the shape or symmetry of a distribution.