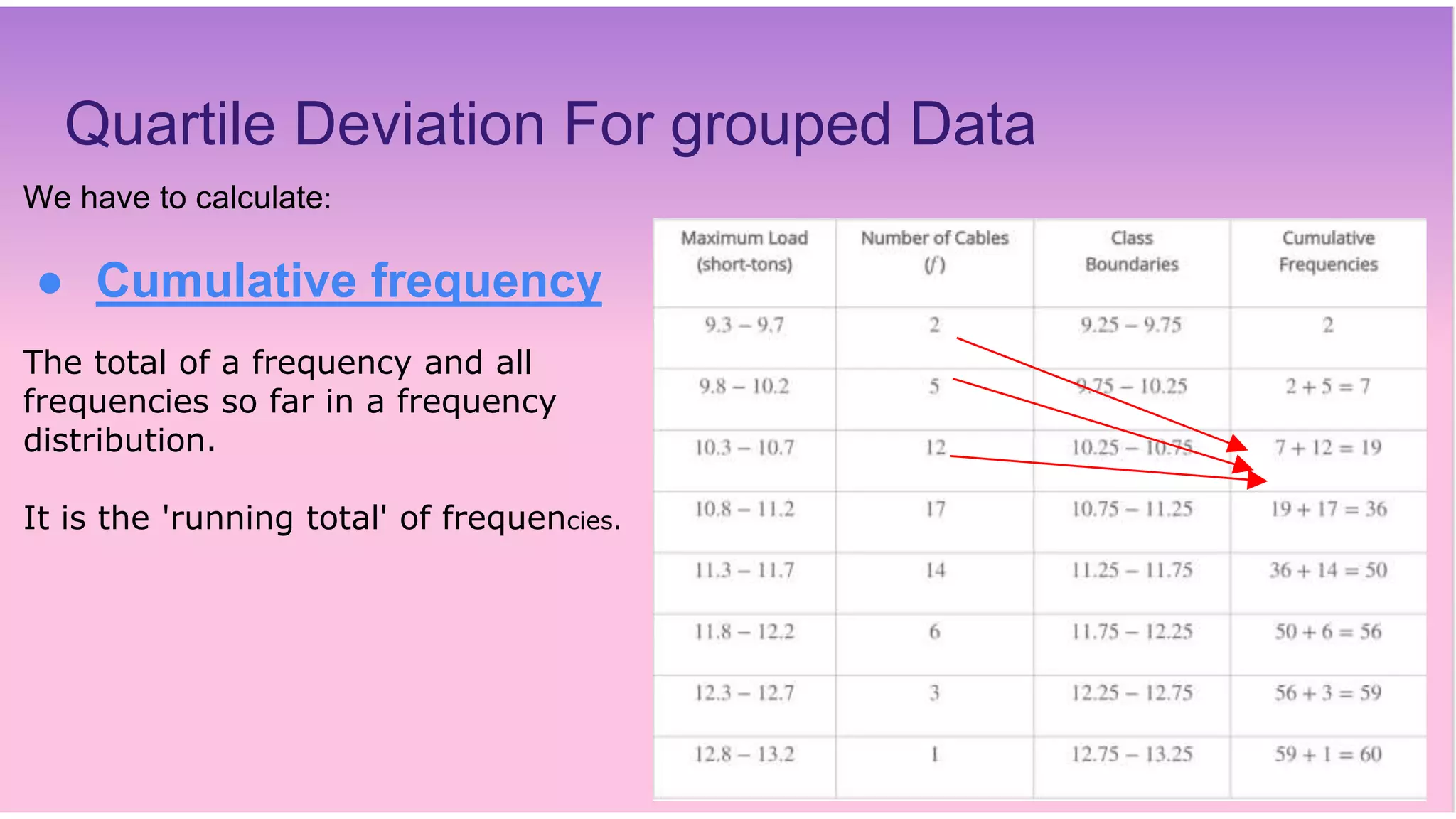
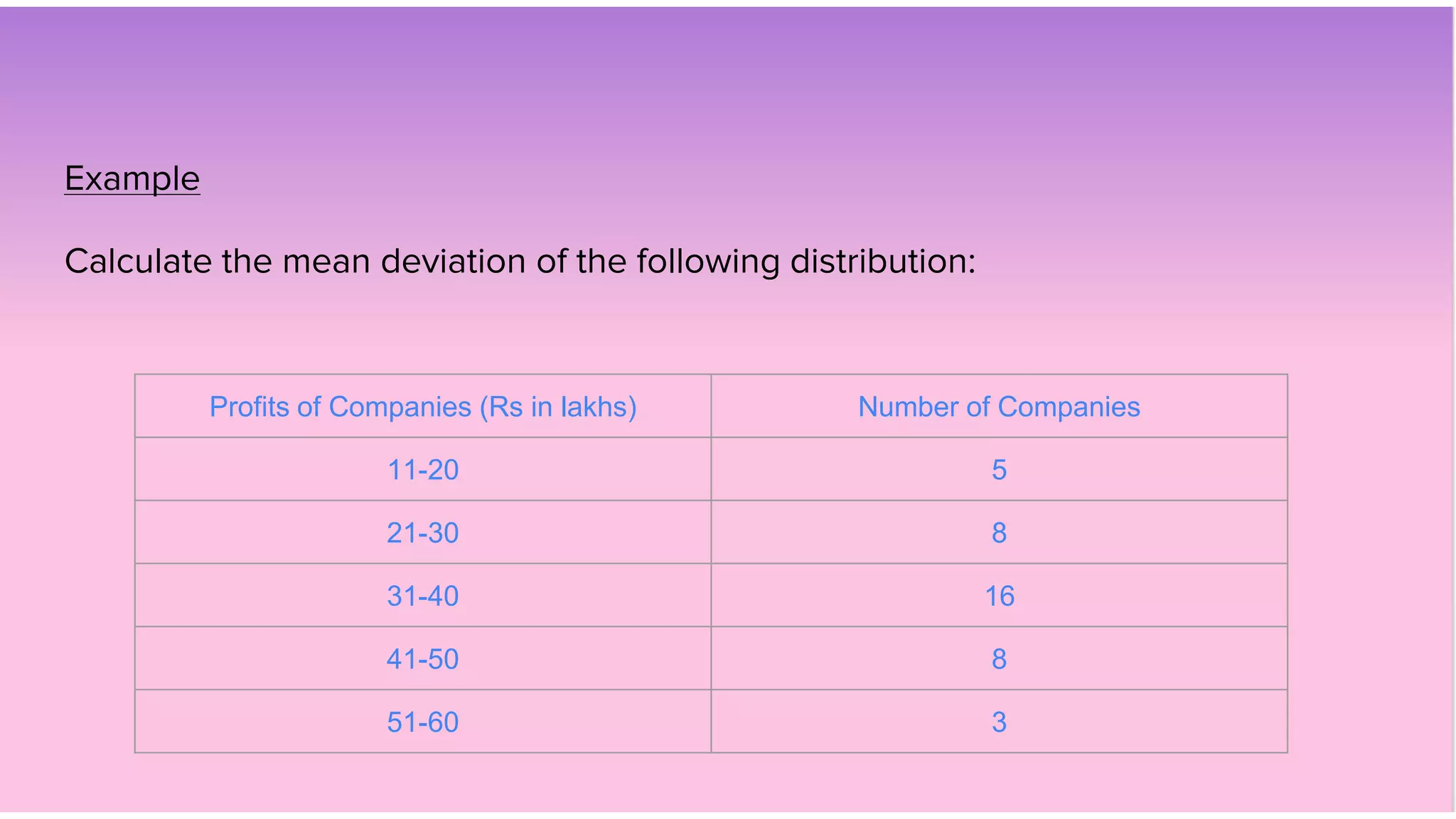
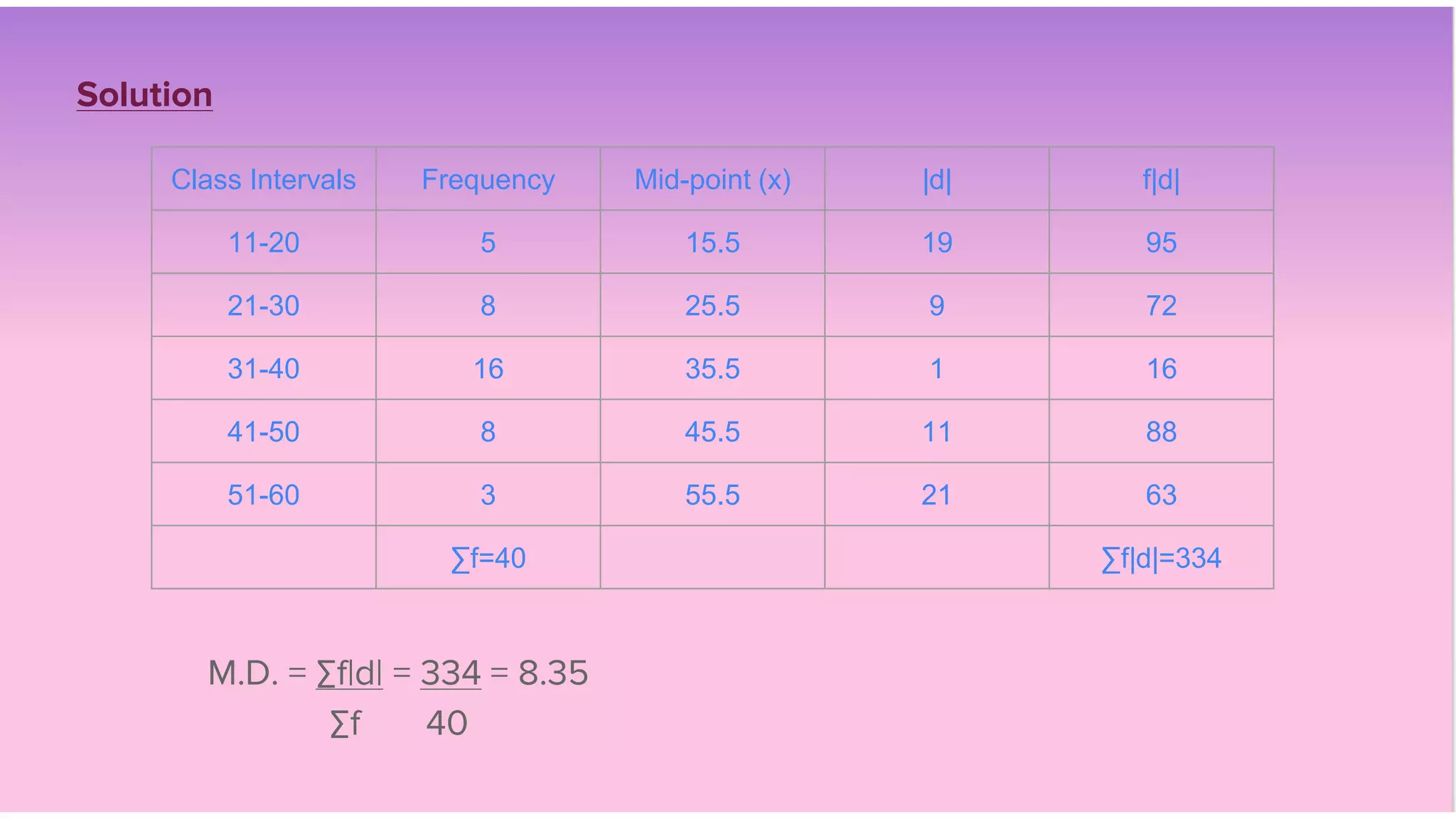
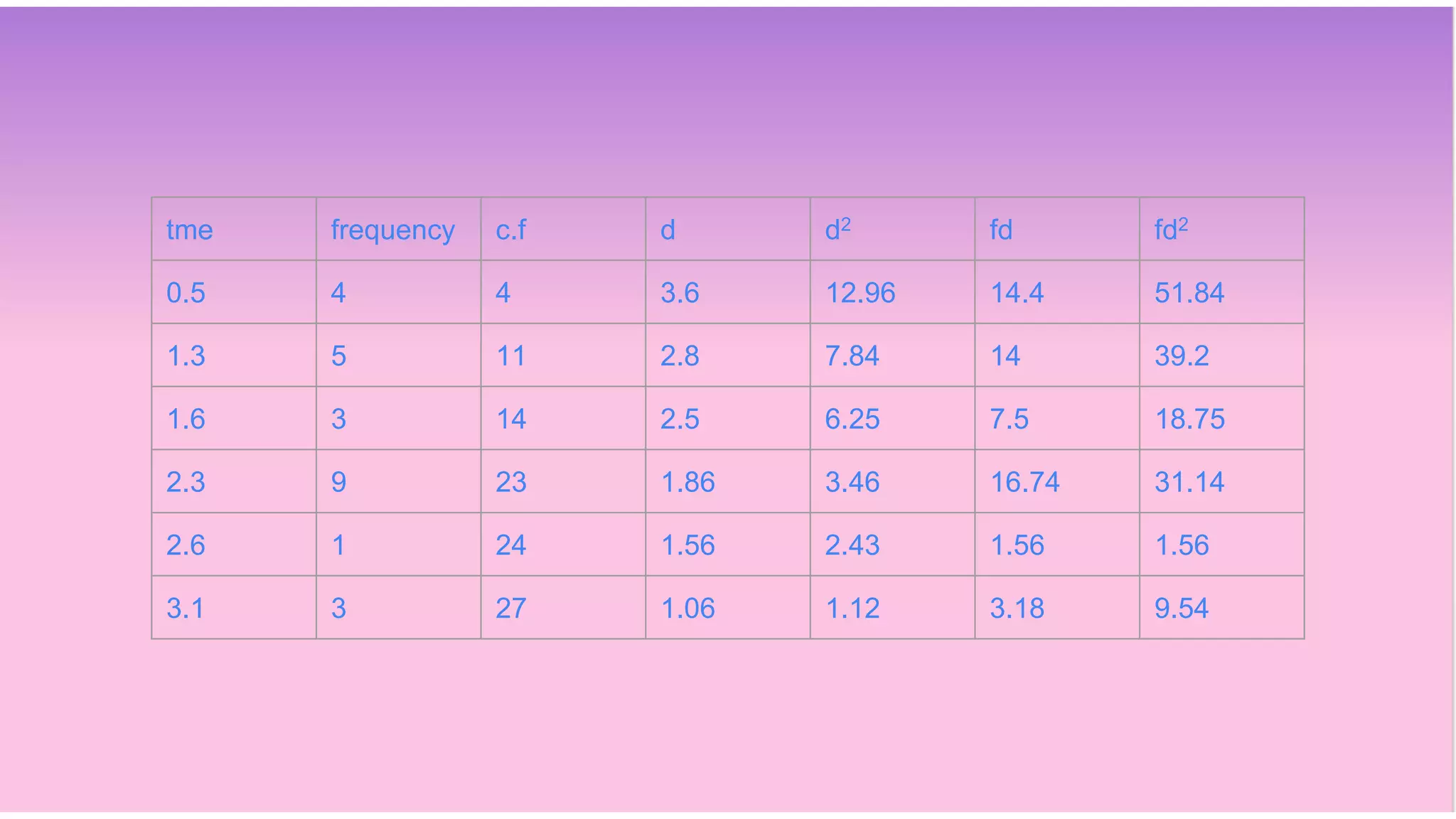
This document discusses various measures of dispersion used in statistics including range, quartile deviation, mean deviation, and standard deviation. It provides definitions and formulas for calculating each measure, as well as examples of calculating the measures for both ungrouped and grouped quantitative data. The key measures discussed are the range, which is the difference between the maximum and minimum values; quartile deviation, which is the difference between the third and first quartiles; mean deviation, which is the mean of the absolute deviations from the mean; and standard deviation, which is the square root of the mean of the squared deviations from the arithmetic mean.