Downloaded 33 times









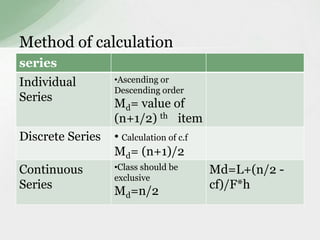















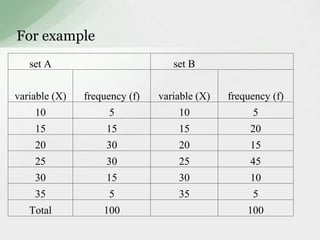
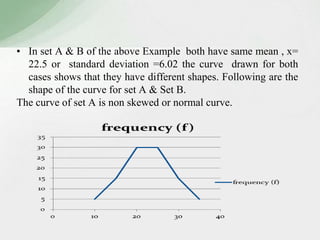
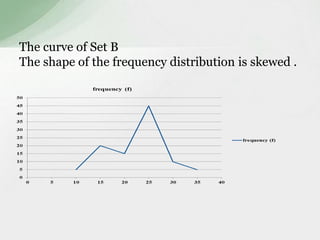


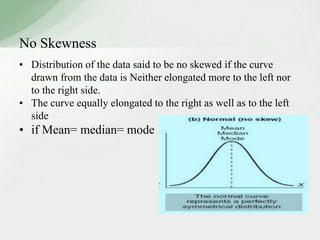
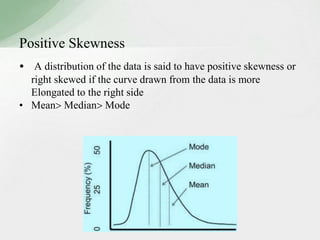
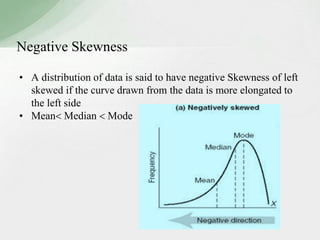
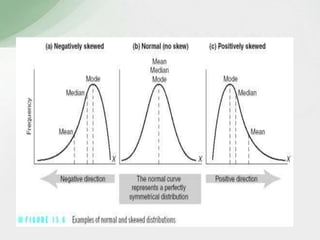







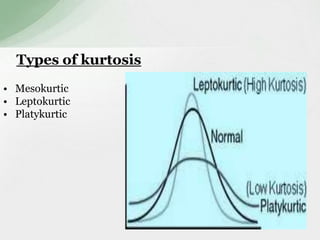







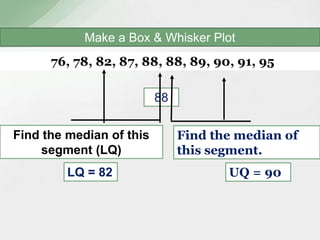
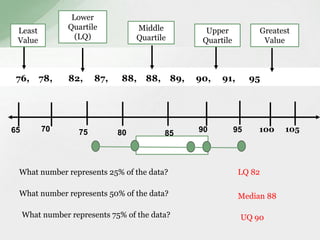




This document summarizes various statistical measures used to analyze and describe data distributions, including measures of central tendency (mean, median, mode), dispersion (range, standard deviation, variance), skewness, and kurtosis. It provides formulas and methods for calculating each measure along with interpretations of the results. Measures of central tendency provide a single value to represent the center of the data set. Measures of dispersion describe how spread out or varied the data values are. Skewness and kurtosis measure the symmetry and peakedness of distributions compared to the normal curve.









































































