Downloaded 27 times










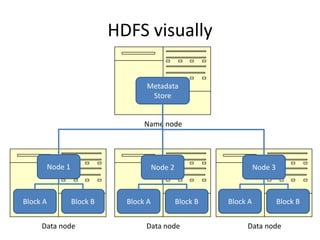


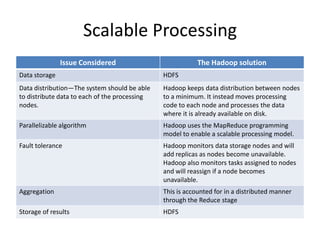

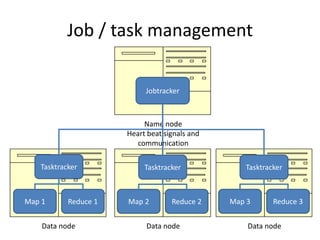








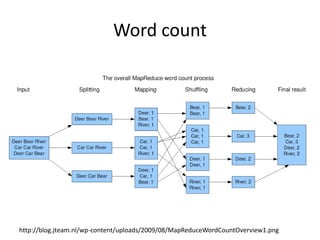
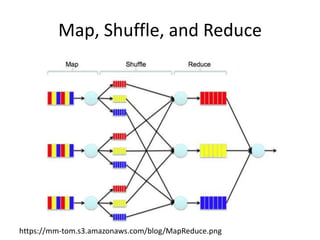


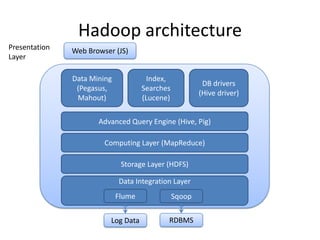



This document provides an introduction to Hadoop and MapReduce. It discusses big data characteristics and challenges. It provides a brief history of Hadoop and compares it to RDBMS. Key aspects of Hadoop covered include the Hadoop Distributed File System (HDFS) for scalable storage and MapReduce for scalable processing. MapReduce uses a map function to process key-value pairs and generate intermediate pairs, and a reduce function to merge values by key and produce final results. The document demonstrates MapReduce through an example word count program and includes demos of implementing it on Hortonworks and Azure HDInsight.




































![[Harvard CS264] 08b - MapReduce and Hadoop (Zak Stone, Harvard)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264hadooplecture2011-110322172329-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)















































