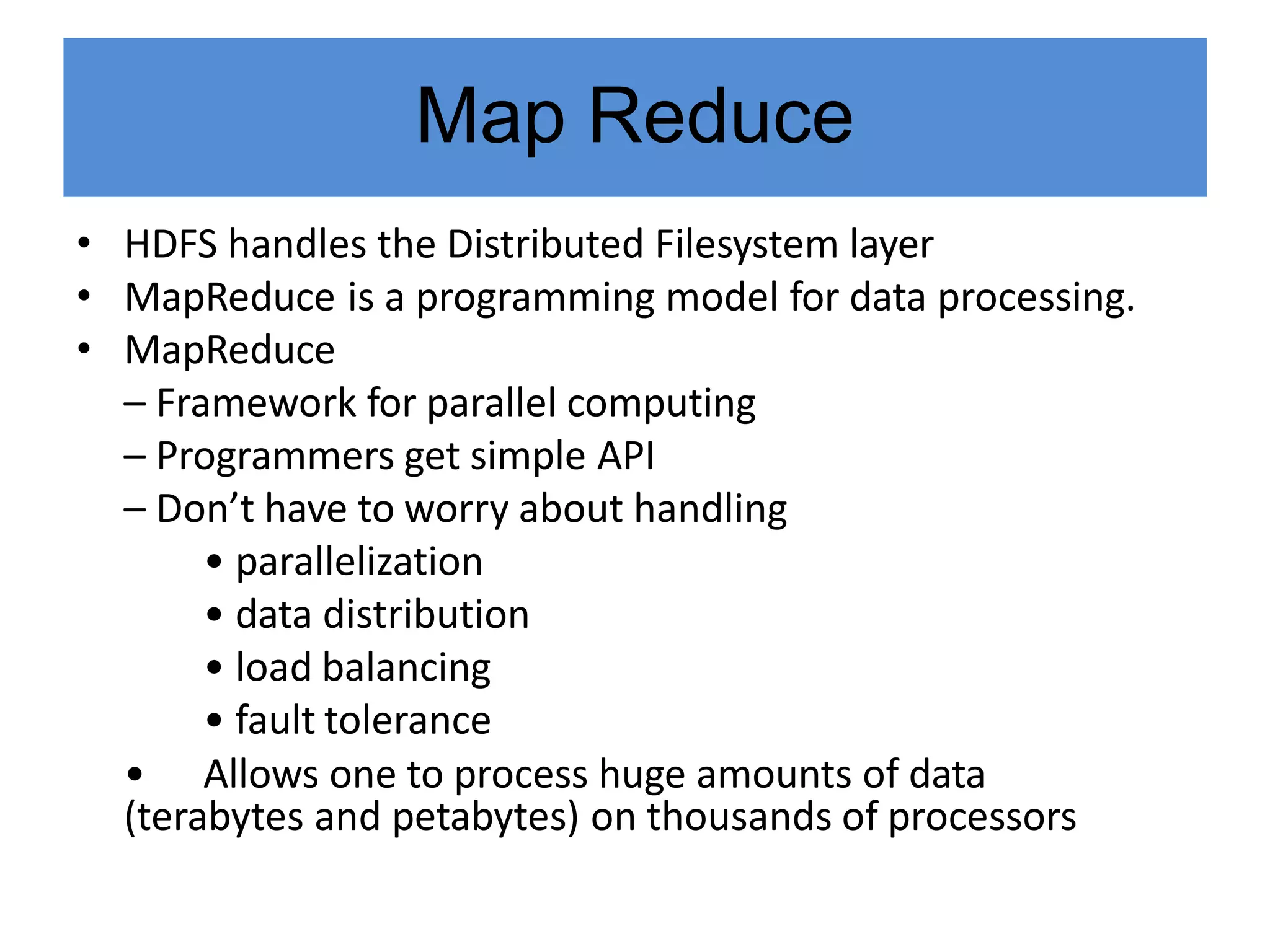
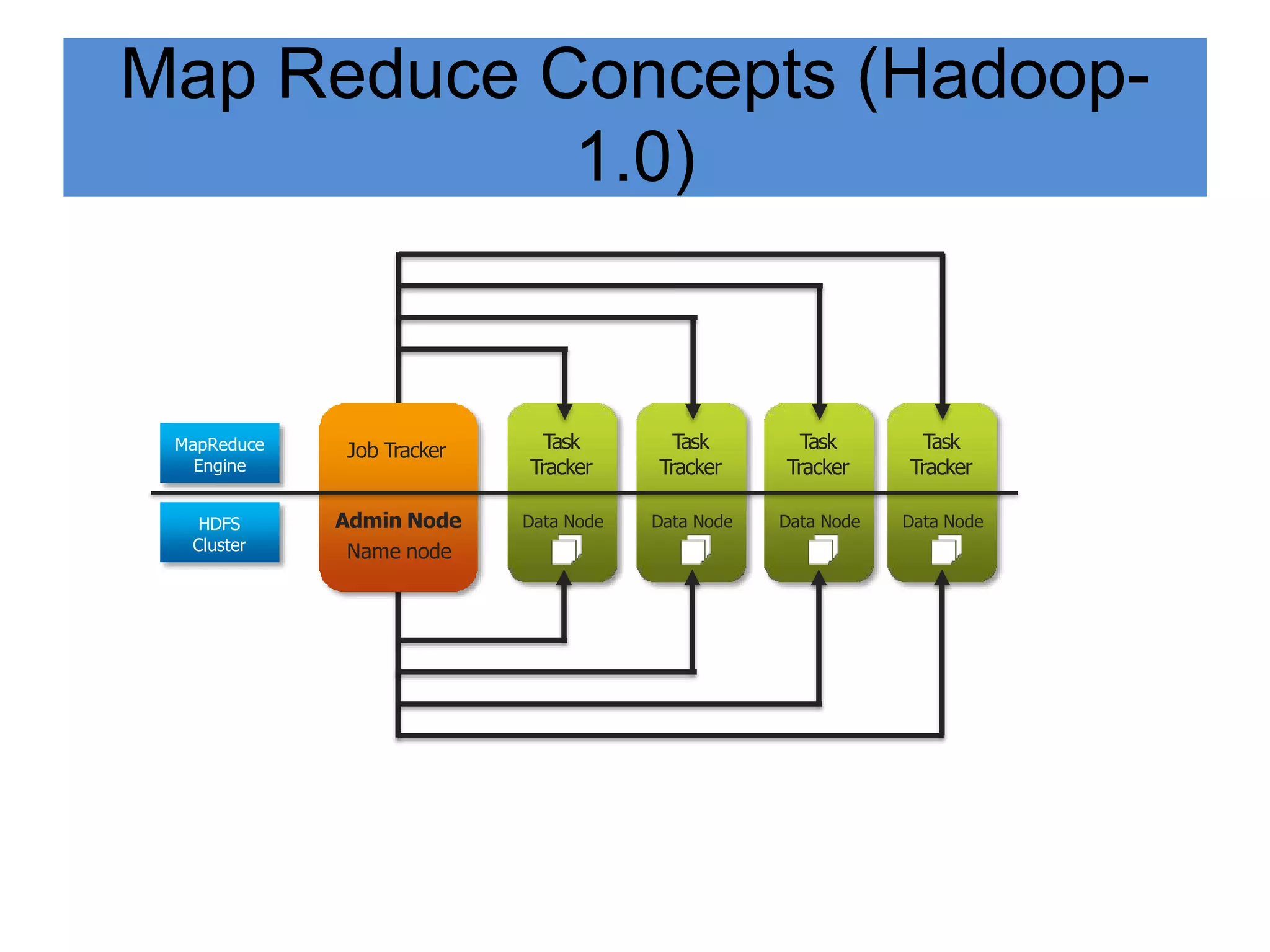
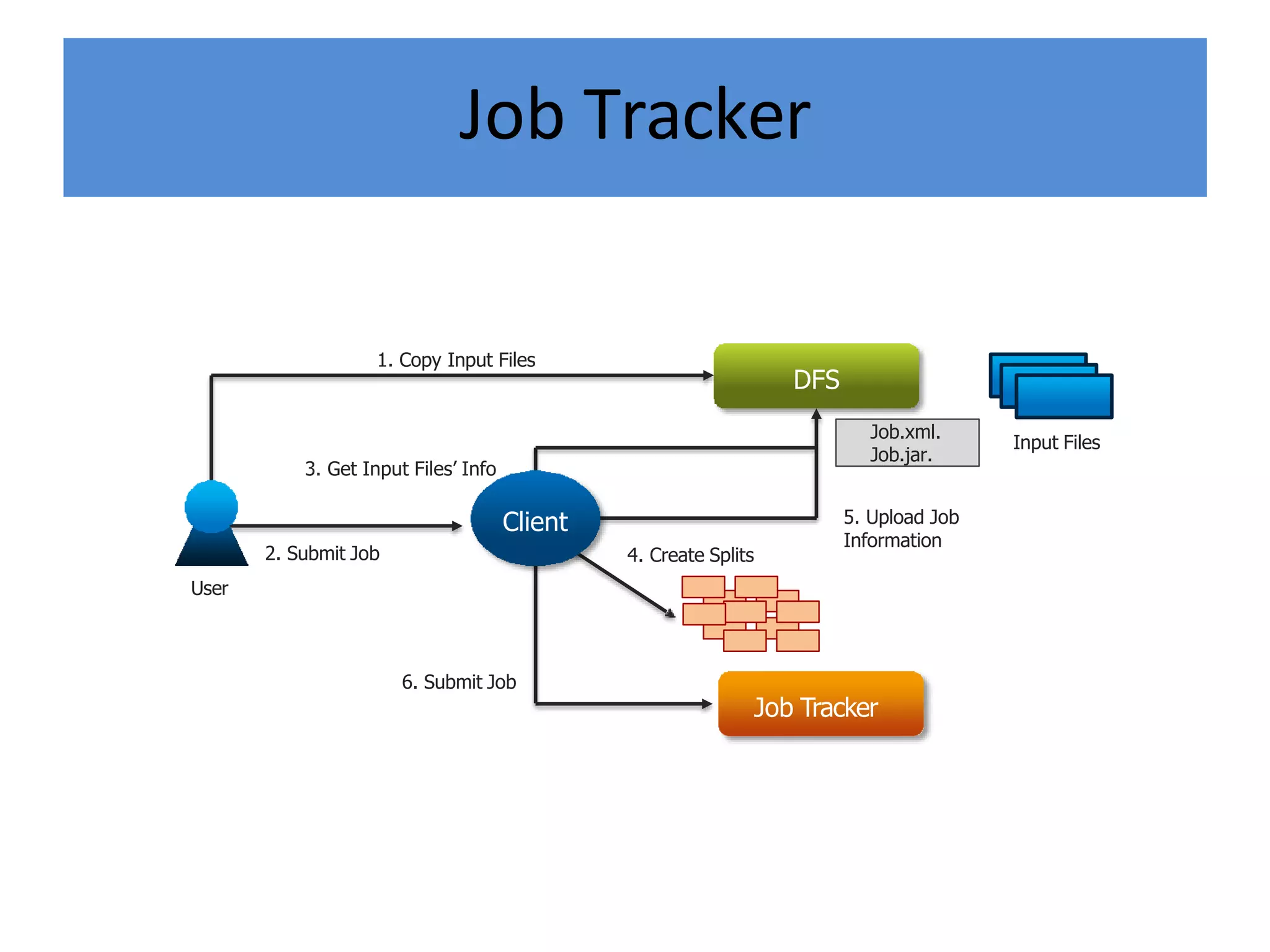
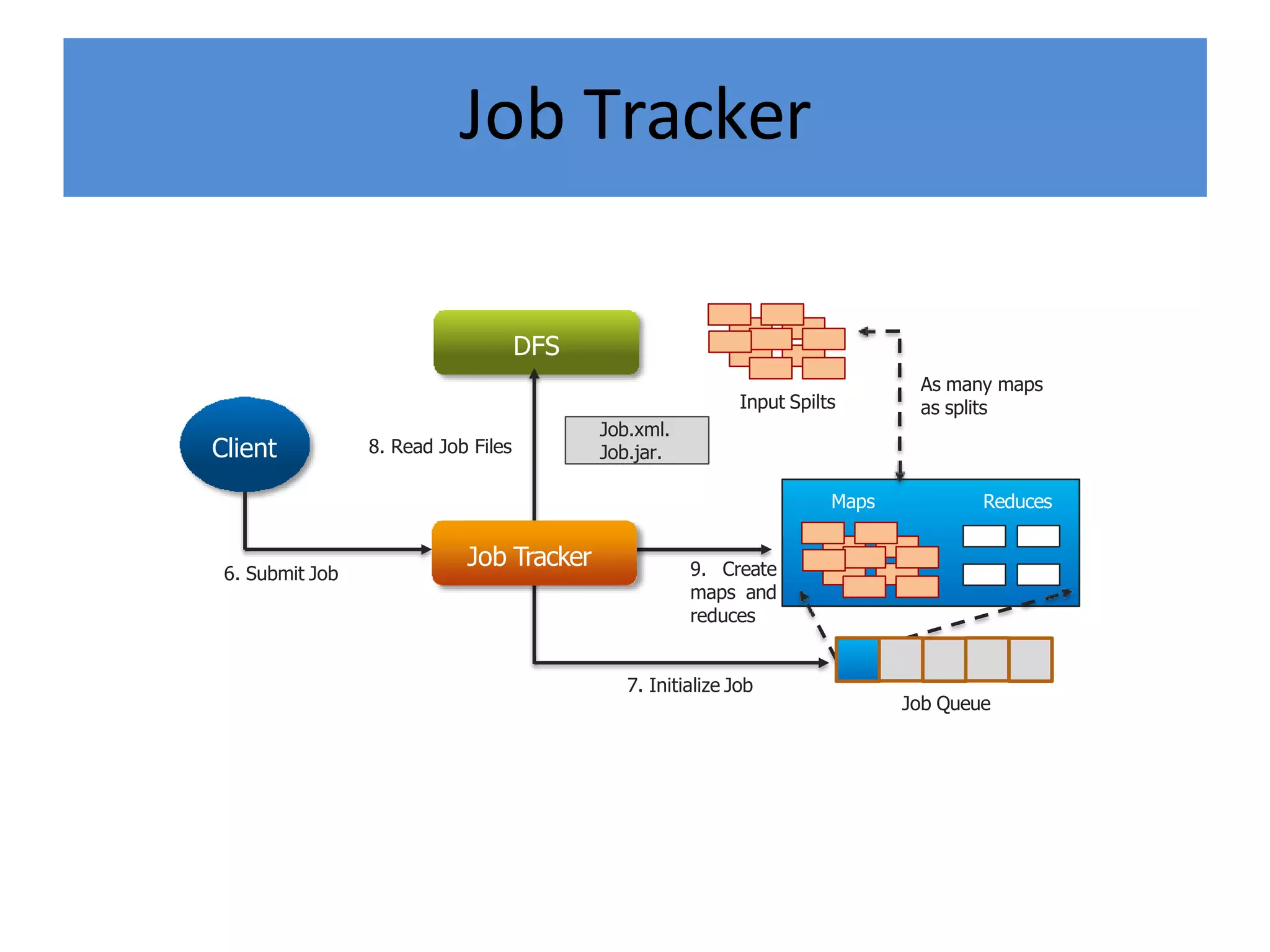
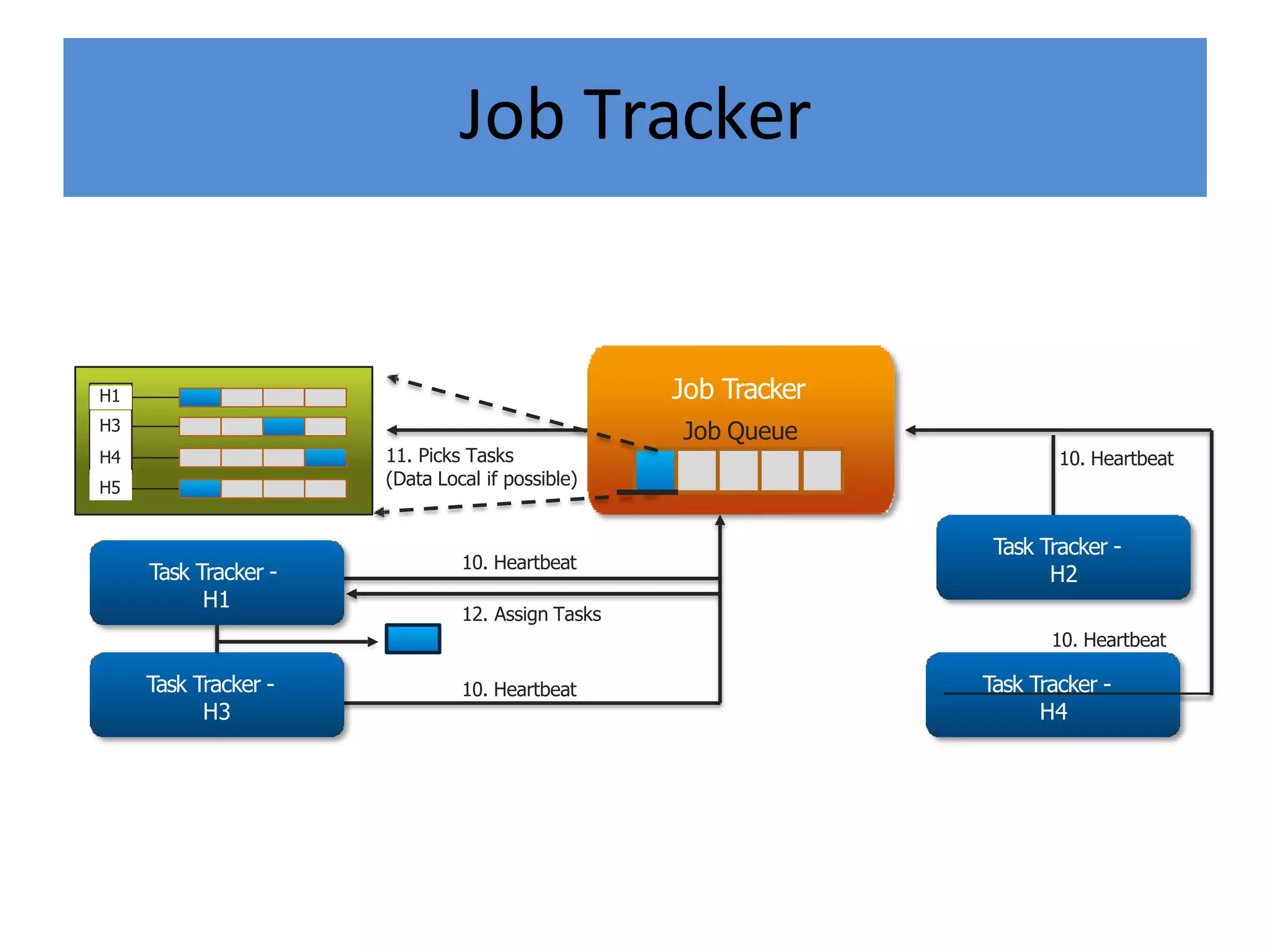
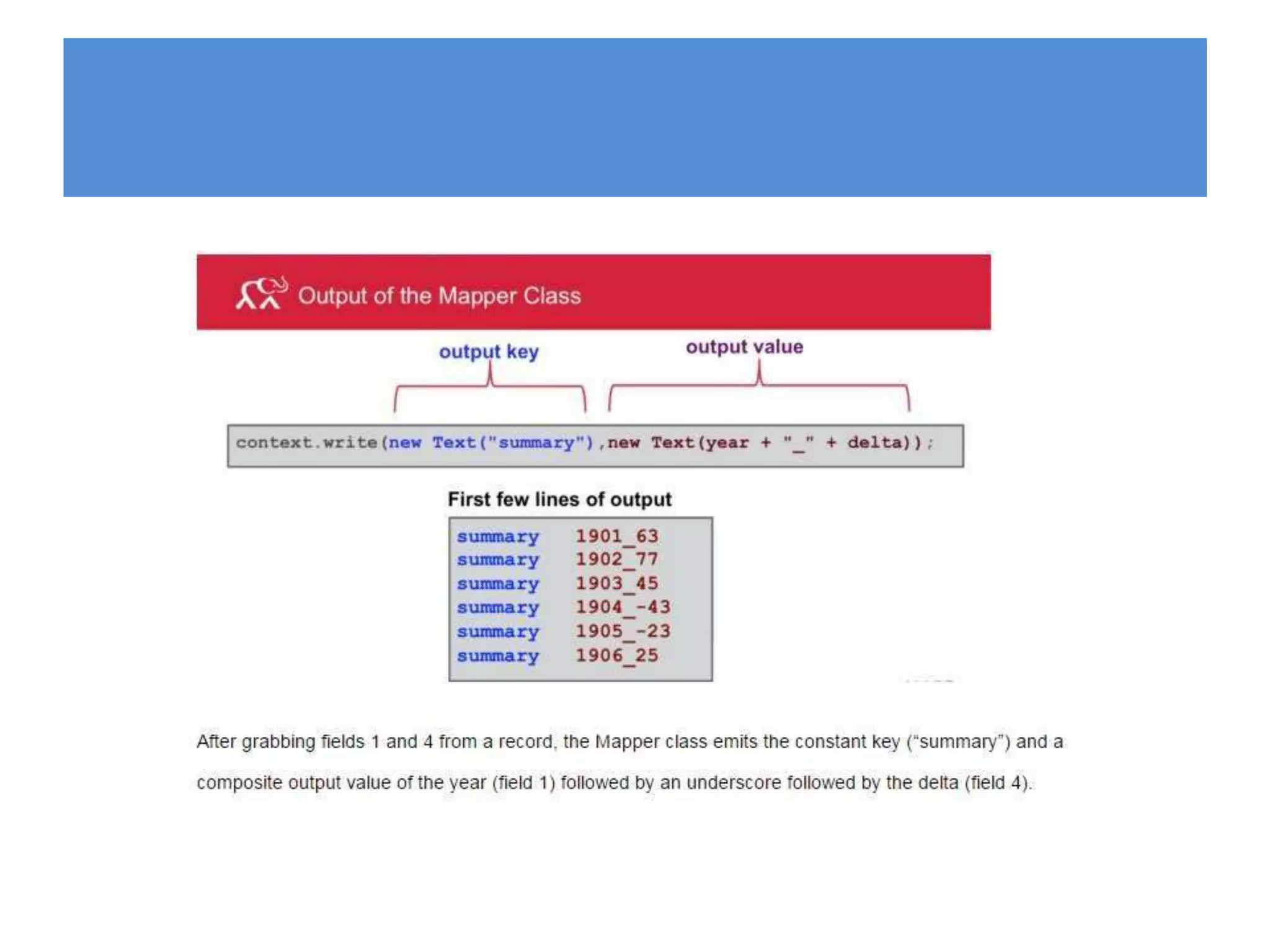
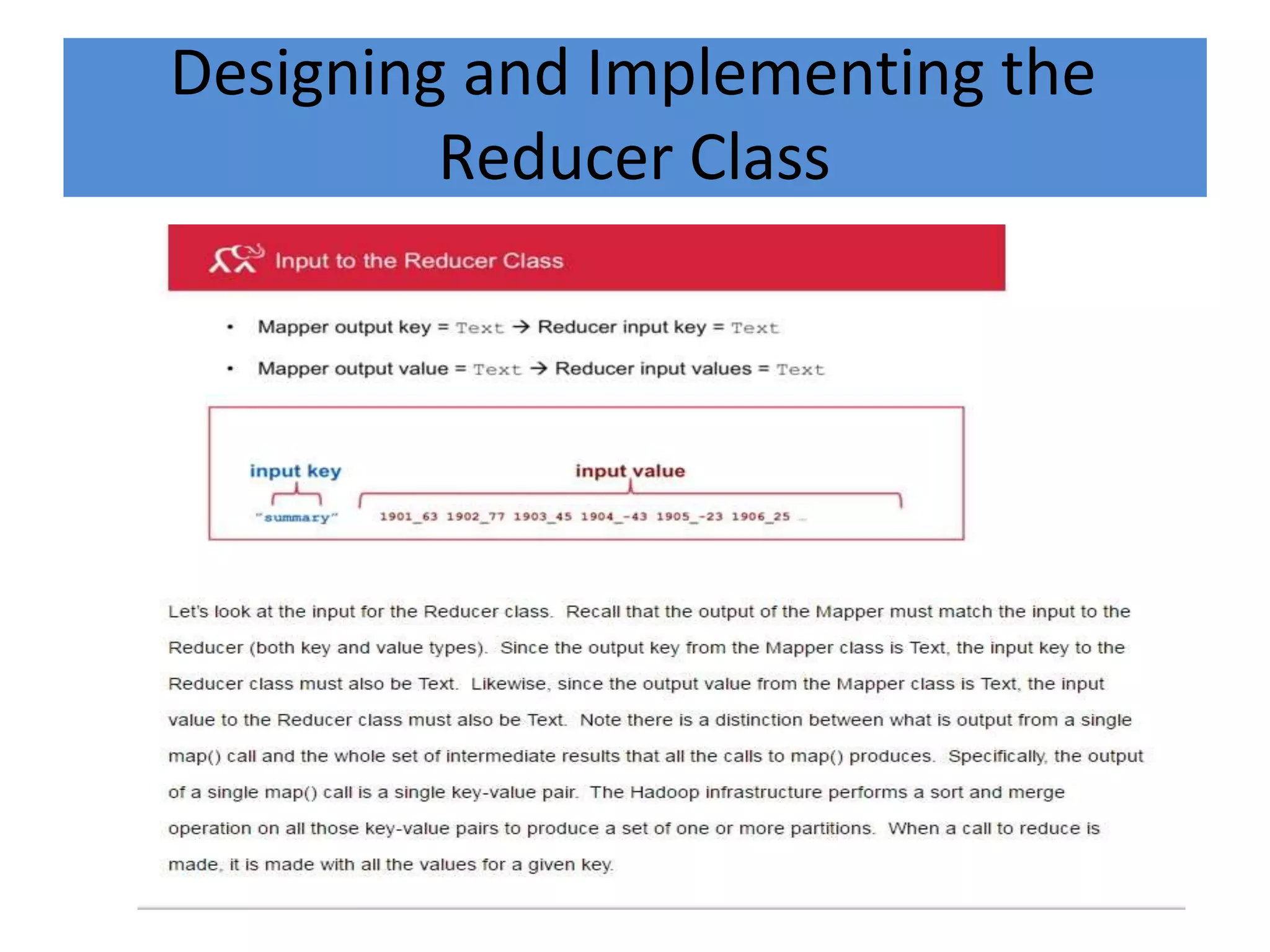
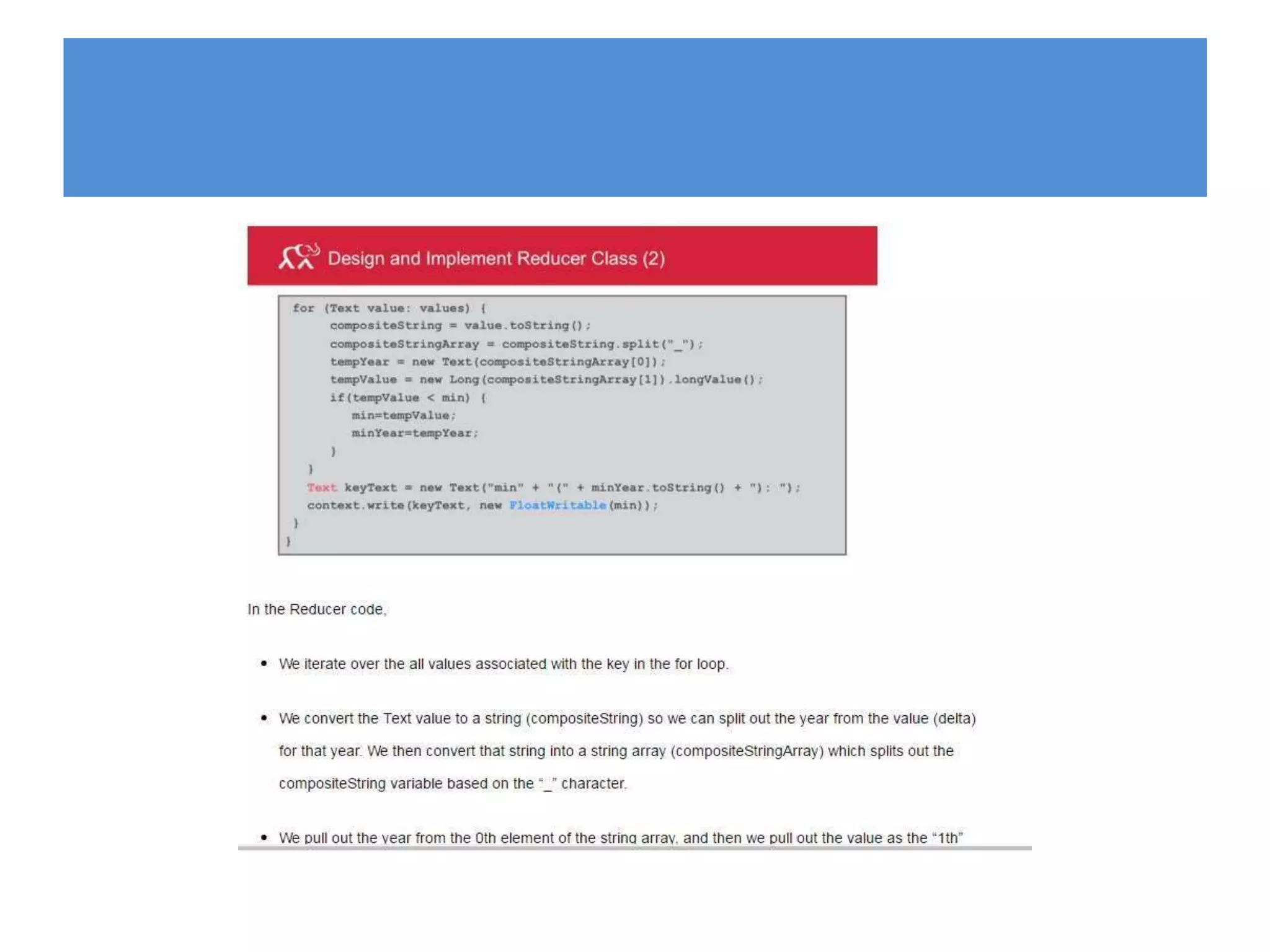
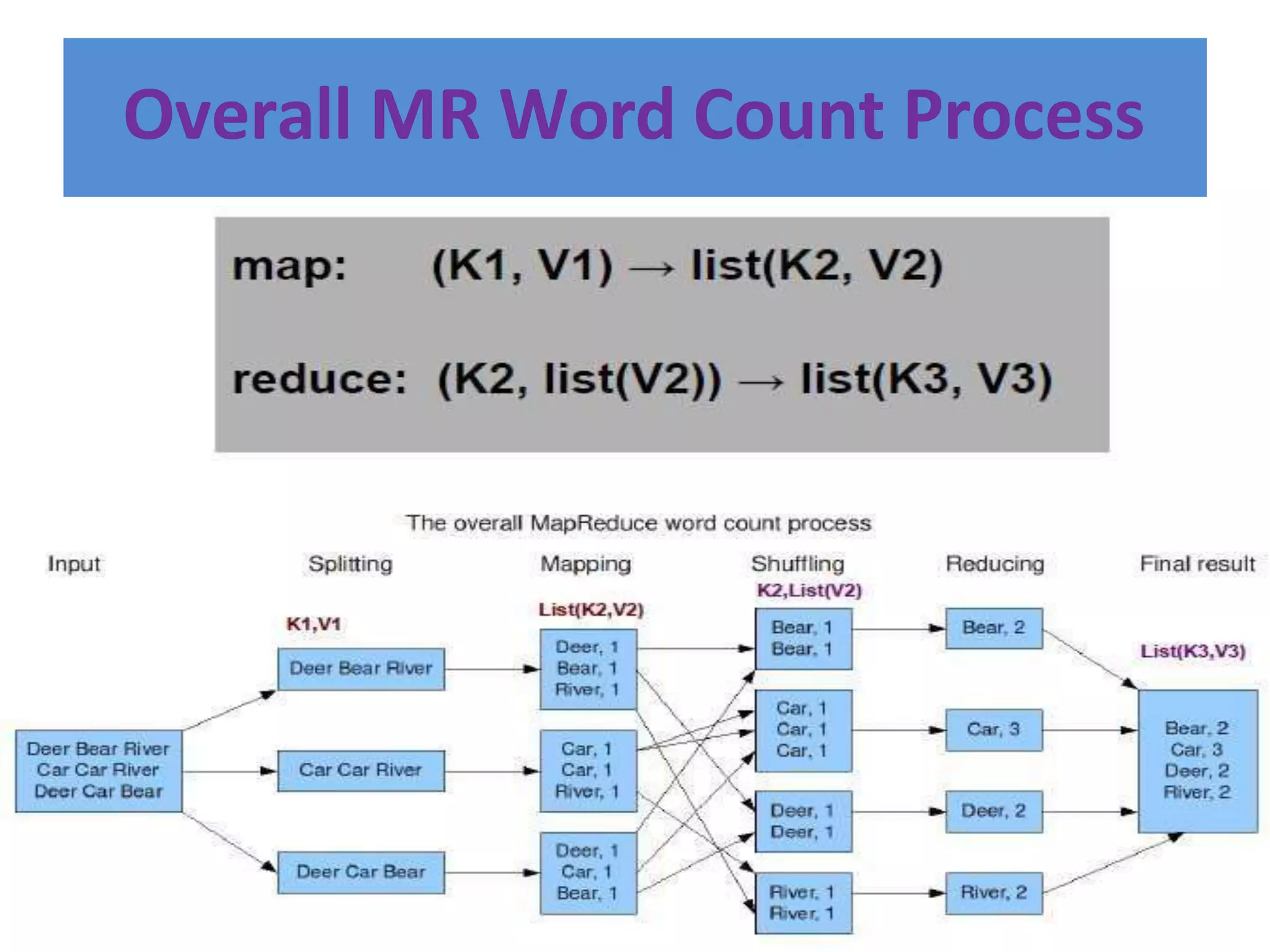
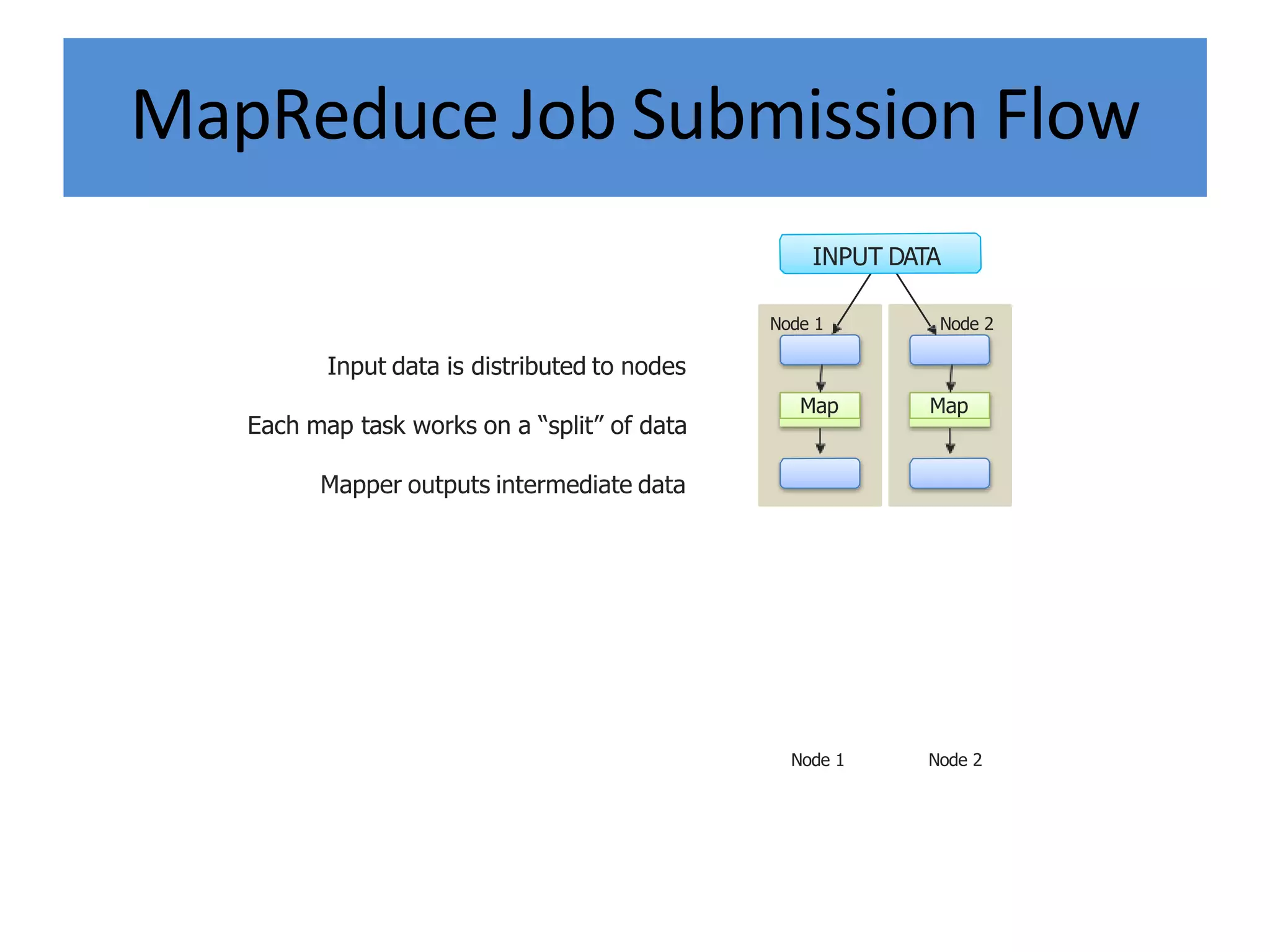
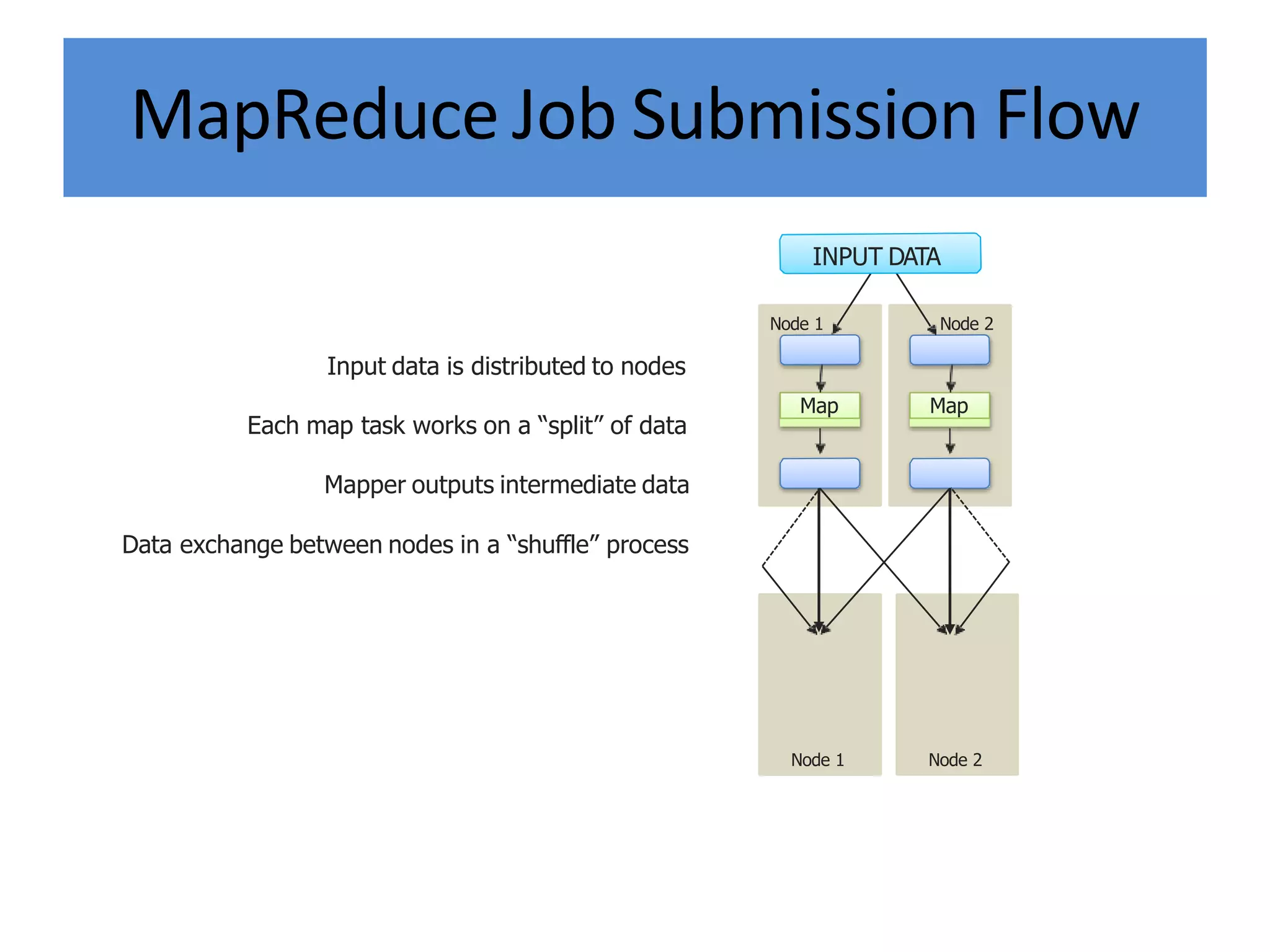
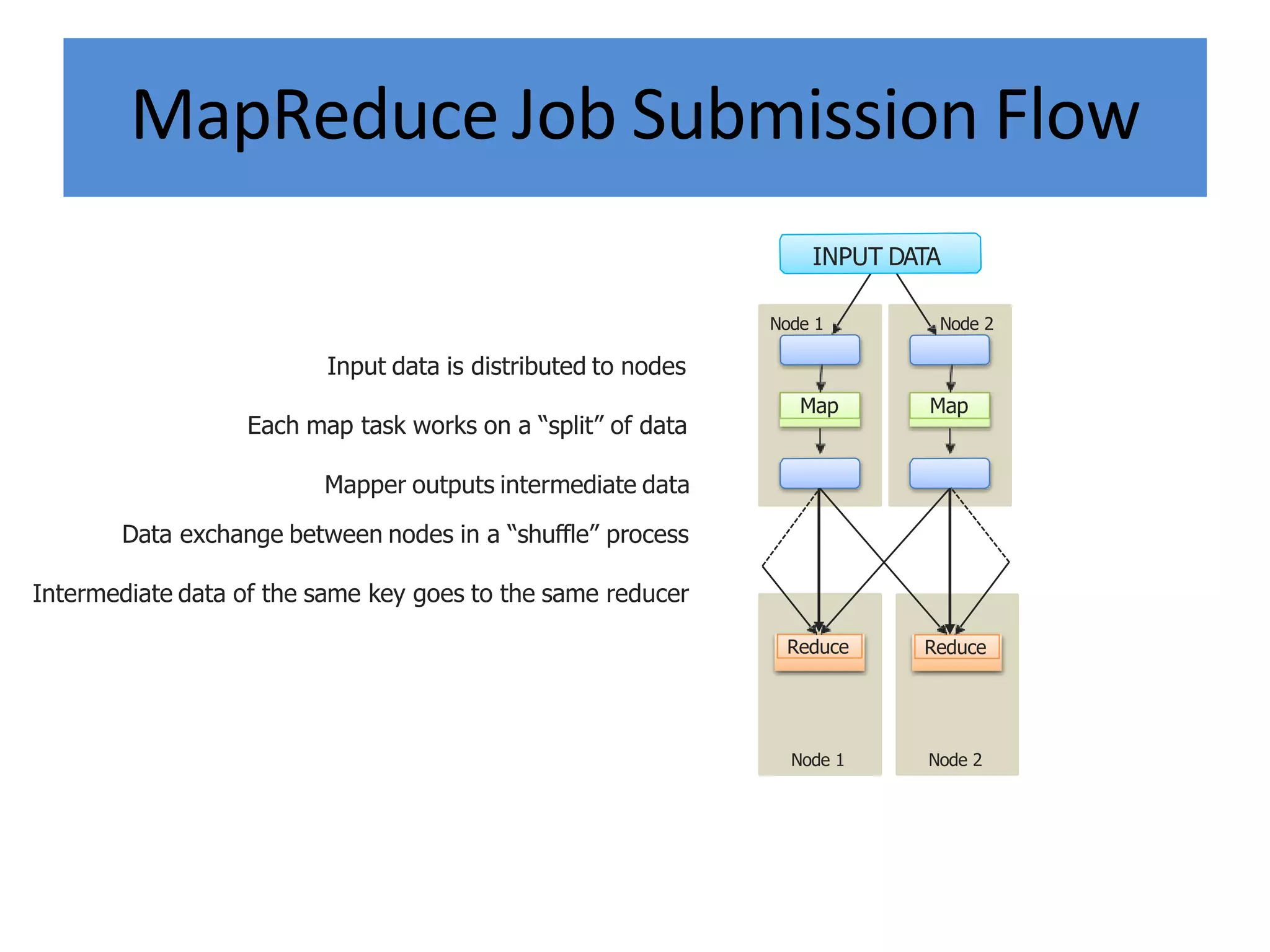
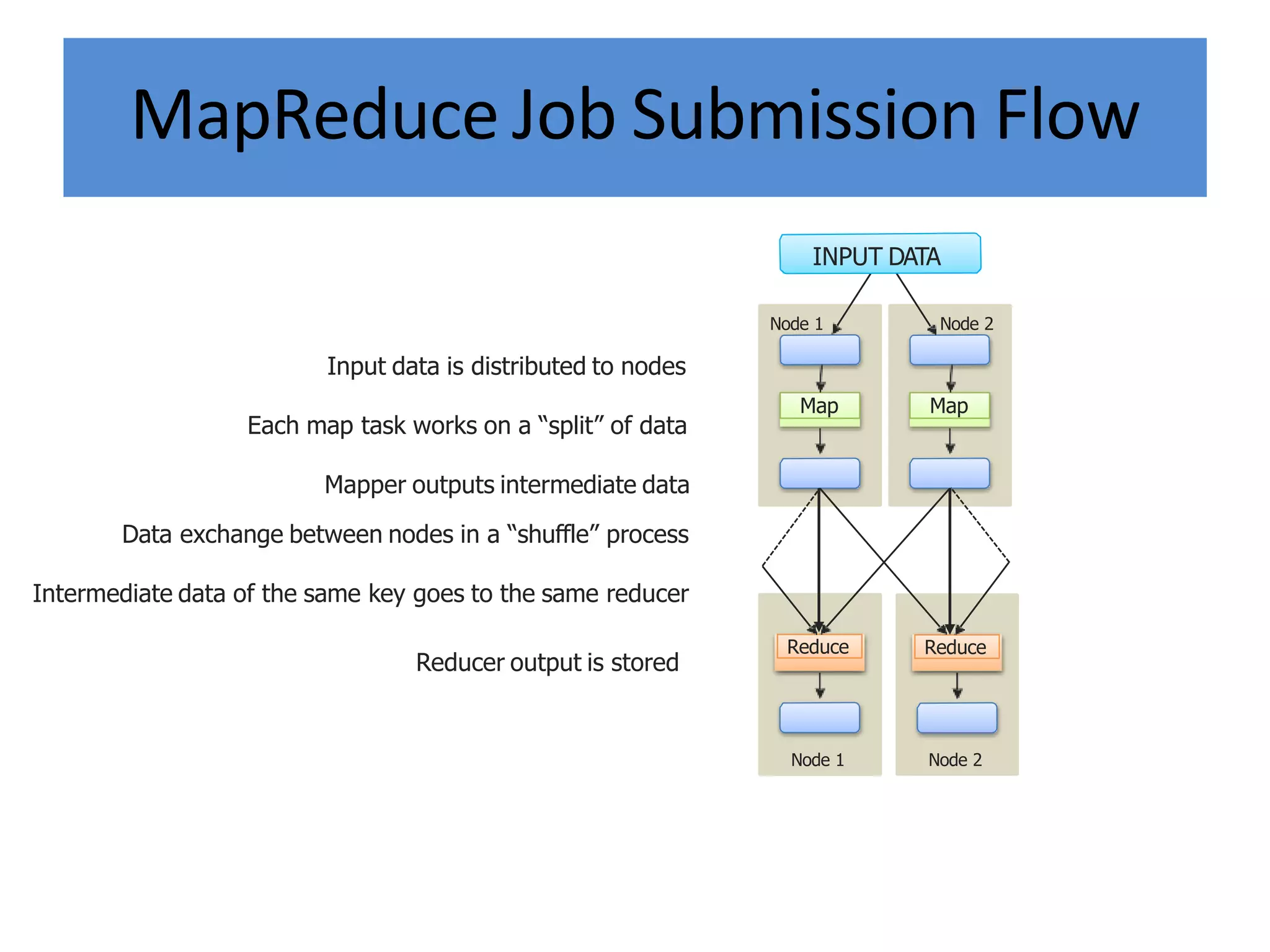
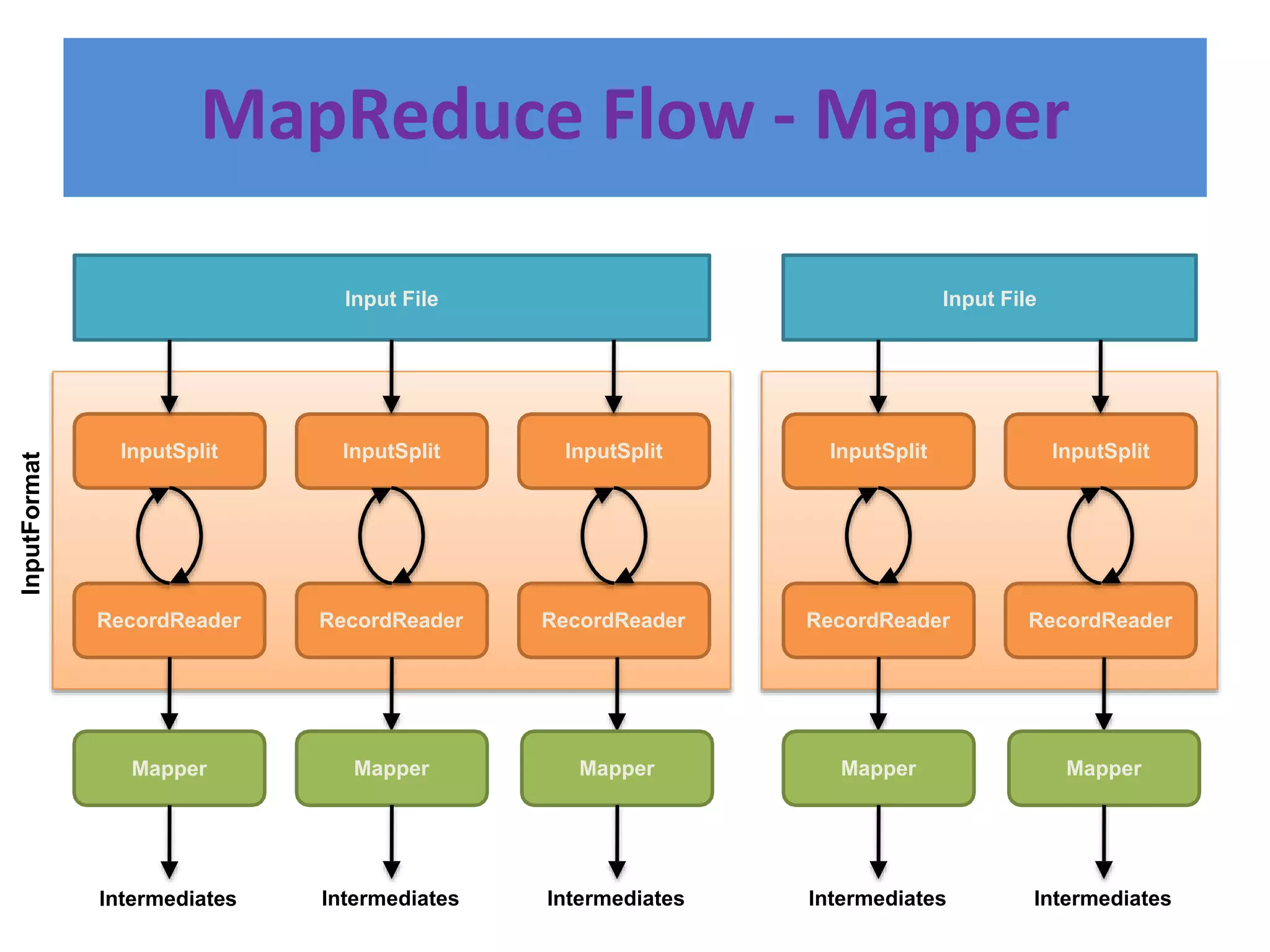
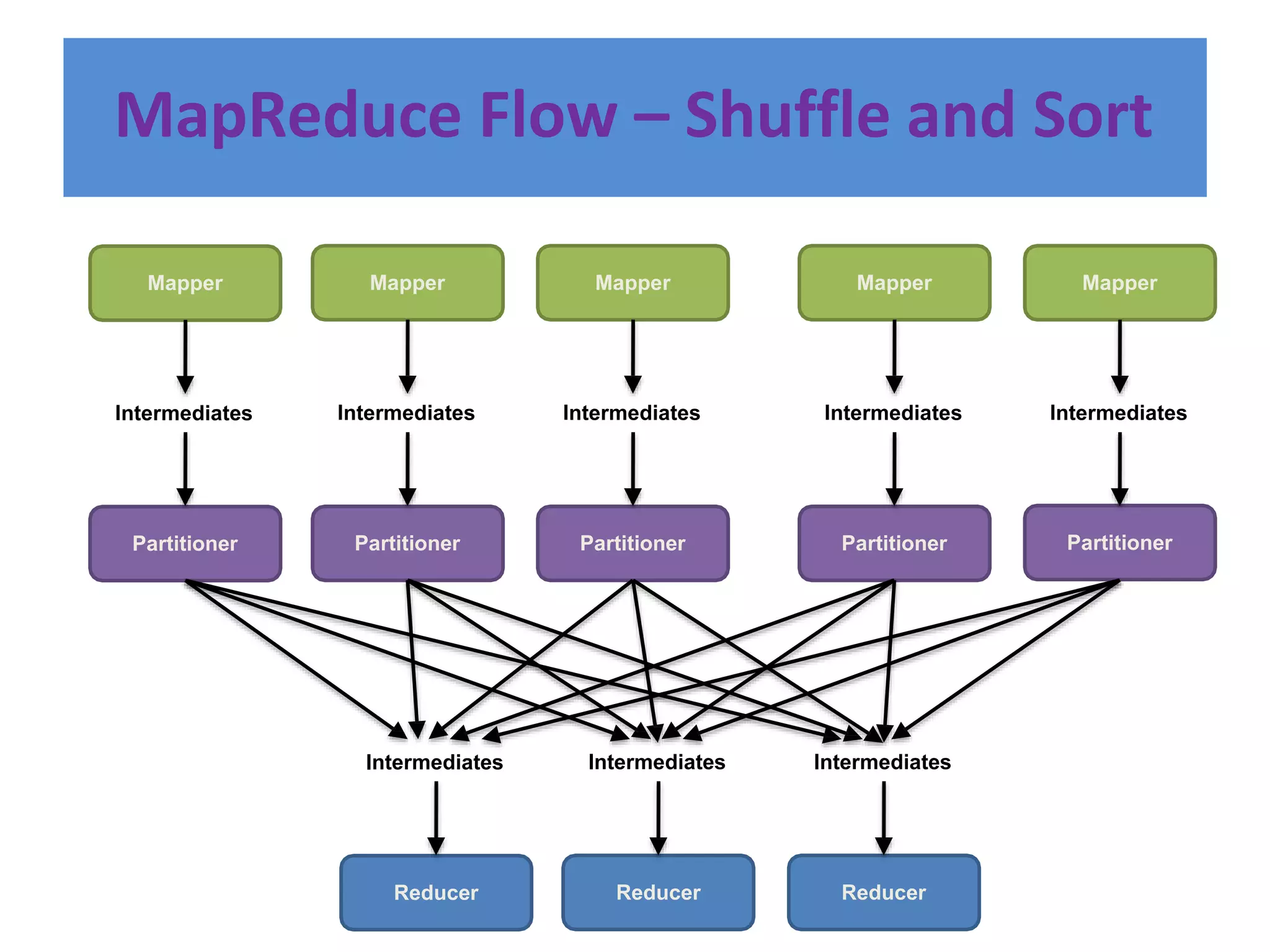
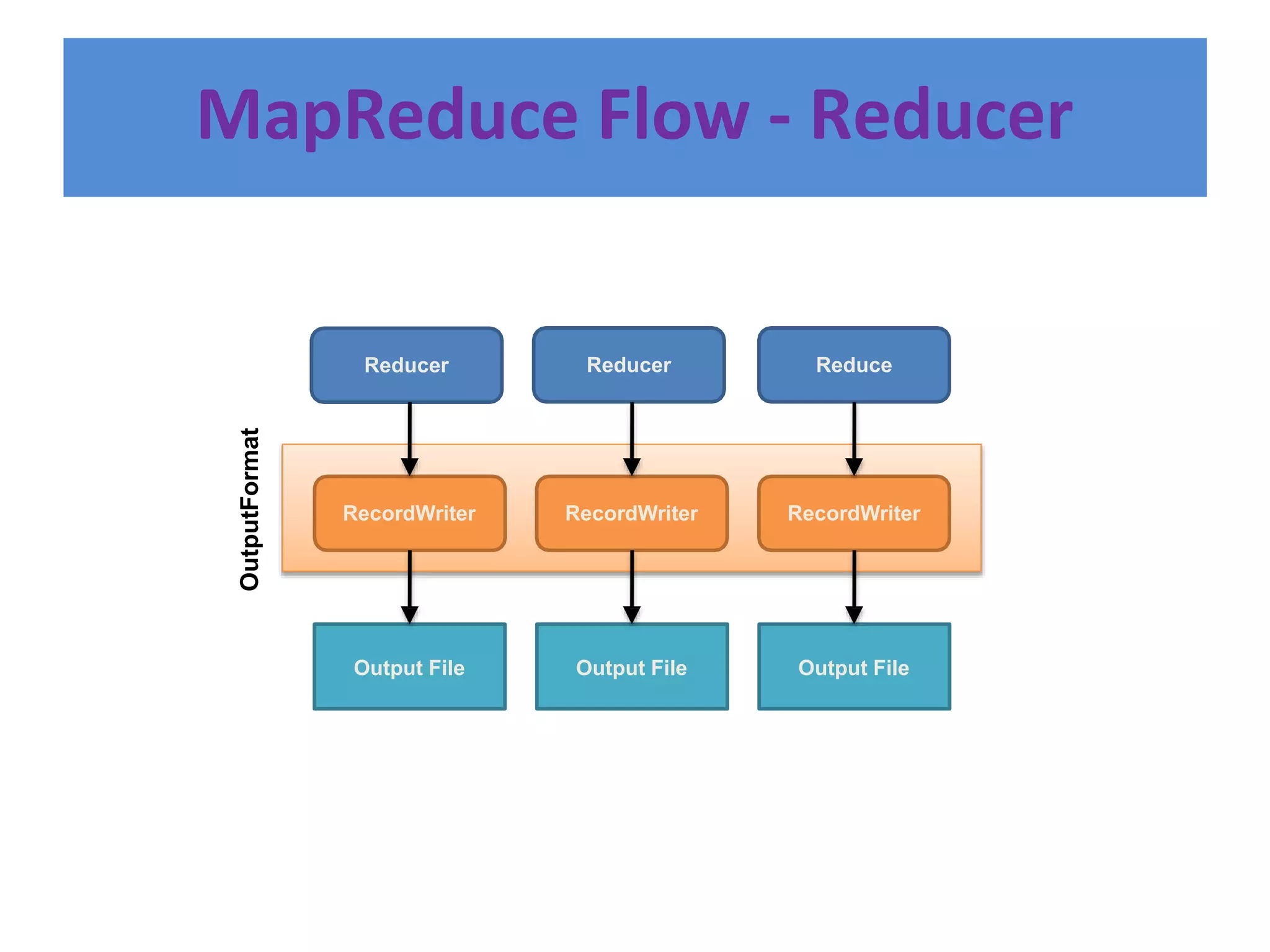
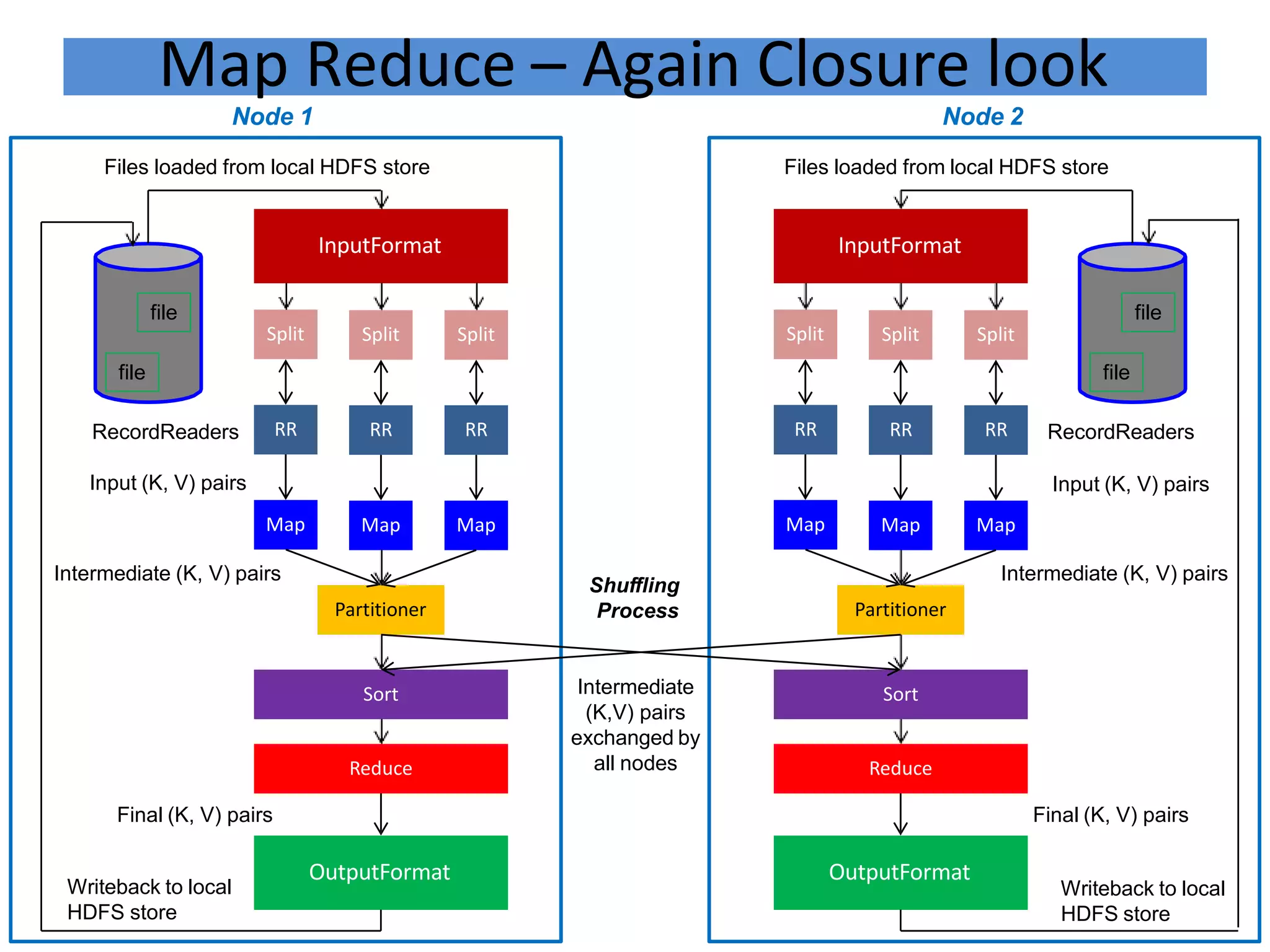
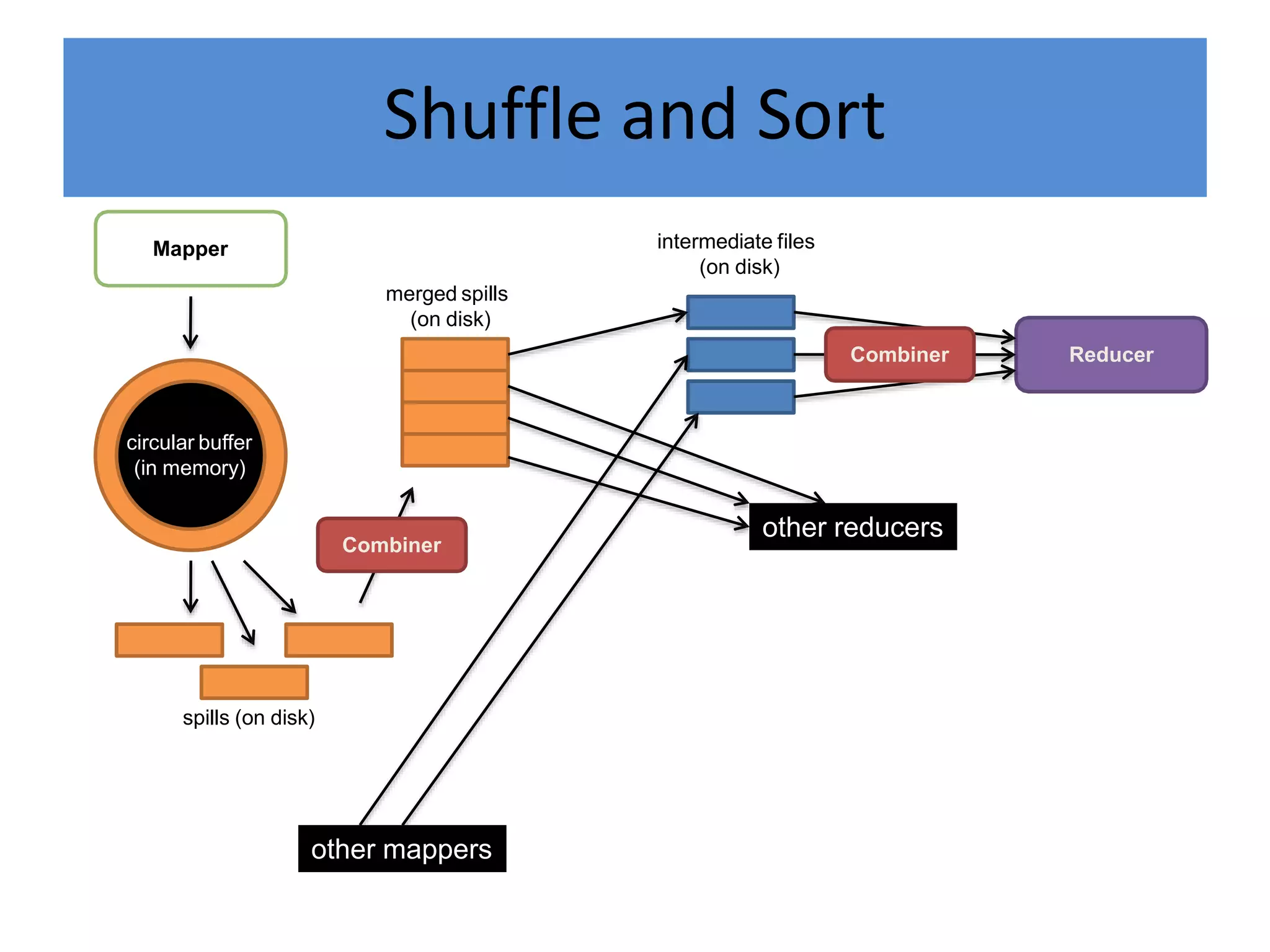
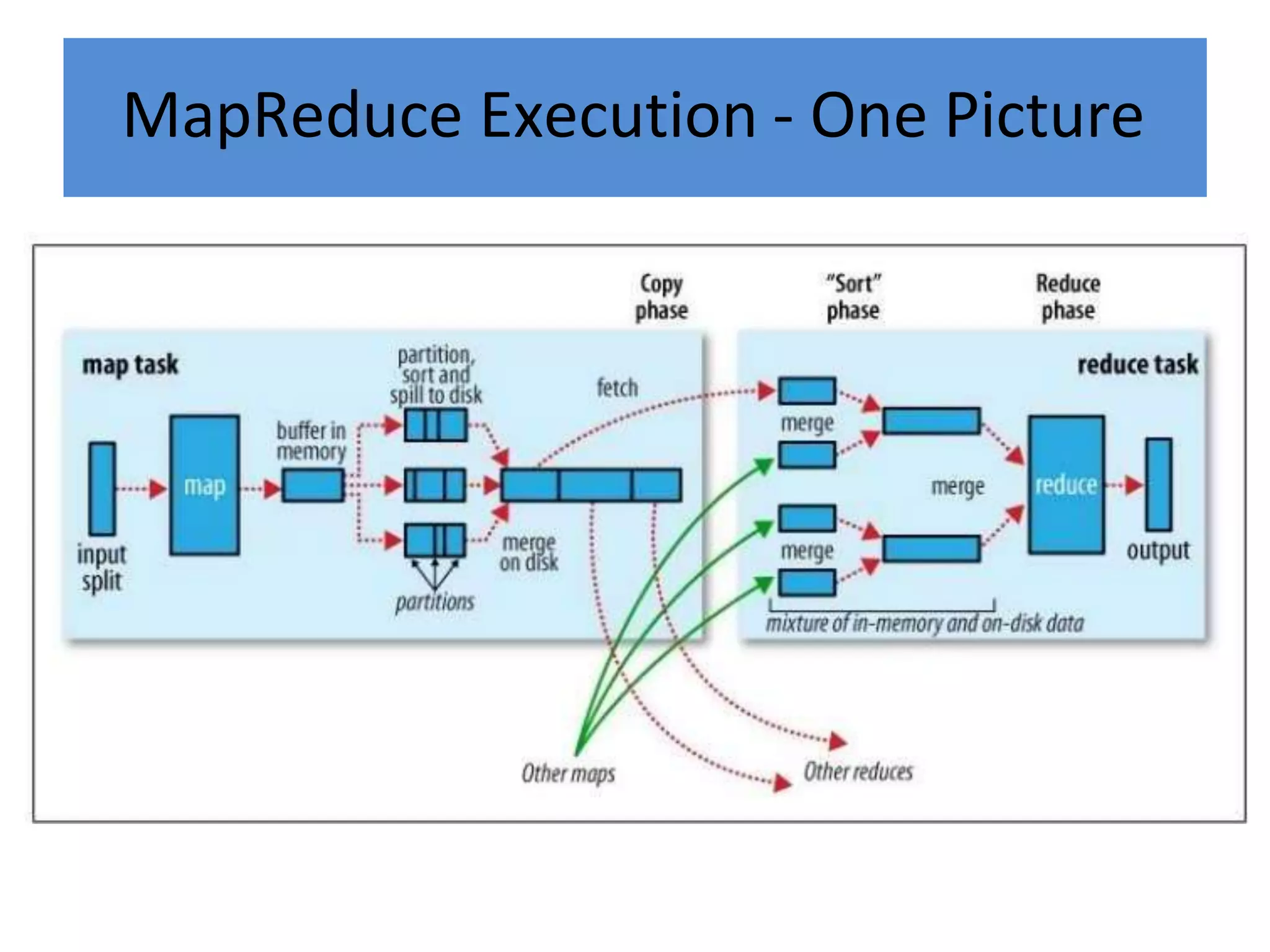
Hadoop is an open-source software framework for distributed storage and processing of large datasets across clusters of computers. It provides reliable storage through HDFS and distributed processing via MapReduce. HDFS handles storage and MapReduce provides a programming model for parallel processing of large datasets across a cluster. The MapReduce framework consists of a mapper that processes input key-value pairs in parallel, and a reducer that aggregates the output of the mappers by key.











![Skeleton of a MapReduce program
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
FileSystem.get(conf).delete(new Path(args[1]), true);
job.waitForCompletion(true);
}](https://image.slidesharecdn.com/mapreduceindatascience-230308075321-898b053d/75/MAP-REDUCE-IN-DATA-SCIENCE-pptx-21-2048.jpg)























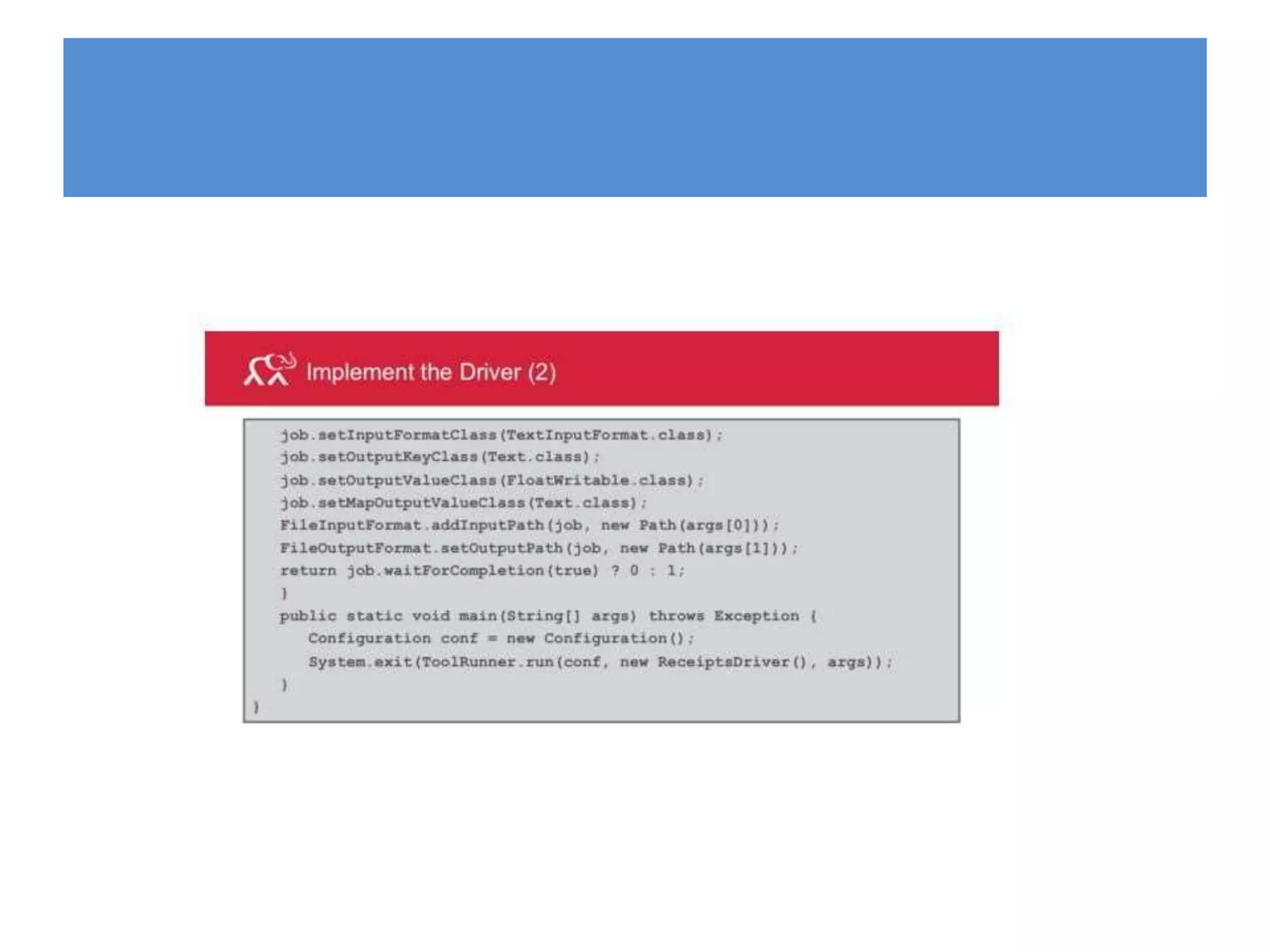
![ToolRunner
public int run(String[] args) throws Exception
{
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(multiInputFile.class);
…..
……
……
FileOutputFormat.setOutputPath(job, new Path(args[2]));
FileSystem.get(conf).delete(new Path(args[2]), true);
return (job.waitForCompletion(true) ? 0 : 1);
}
public static void main(String[] args) throws Exception
{
int ecode = ToolRunner.run(new multiInputFile(), args);
System.exit(ecode);
}](https://image.slidesharecdn.com/mapreduceindatascience-230308075321-898b053d/75/MAP-REDUCE-IN-DATA-SCIENCE-pptx-67-2048.jpg)































![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Dobrica Cosic - Savings by the Second: How Dynamic Pricing an...](https://cdn.slidesharecdn.com/ss_thumbnails/znp09f3smtqz3w2sq6wn-1-dobrica-cosic-savings-by-the-second-how-dynamic-pricing-and-smart-data-are-bu-251208151905-26e6f41e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Zdravkovic - The road less traveled in District Heating...](https://cdn.slidesharecdn.com/ss_thumbnails/nfaboniqwsz4ucyctnmy-2-milan-zdravkovic-dsc2025-the-road-less-traveled-in-district-heating-operation-251208151905-f56388a5-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Sara Polak - The Ancient Operating System: What Archaeology T...](https://cdn.slidesharecdn.com/ss_thumbnails/3vch2p6tttdnwhsgazoz-3-sara-polak-smart-cities-251208152532-64404202-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Sara Polak - The Archaeology of Innovation: AI as the Next Cr...](https://cdn.slidesharecdn.com/ss_thumbnails/7ecbscdnt8mlcuqbd2ln-2-sara-polak-ai-creative-industries-251208152533-aa1fcf54-thumbnail.jpg?width=640&height=640&fit=bounds)

