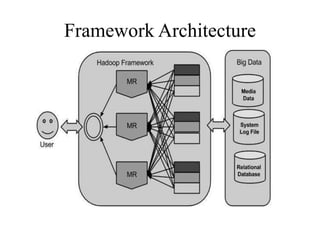
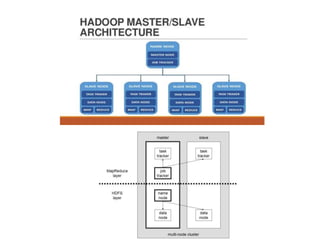
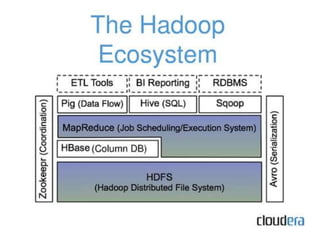
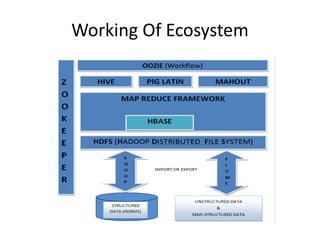
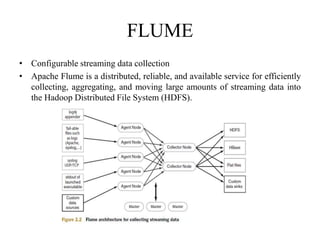
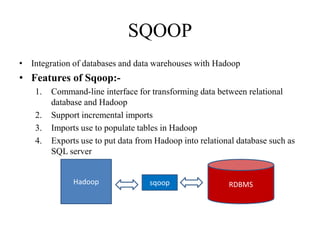
The document provides an overview of Hadoop and its ecosystem. It discusses the history and architecture of Hadoop, describing how it uses distributed storage and processing to handle large datasets across clusters of commodity hardware. The key components of Hadoop include HDFS for storage, MapReduce for processing, and an ecosystem of related projects like Hive, HBase, Pig and Zookeeper that provide additional functions. Advantages are its ability to handle unlimited data storage and high speed processing, while disadvantages include lower speeds for small datasets and limitations on data storage size.