Download as PDF, PPTX






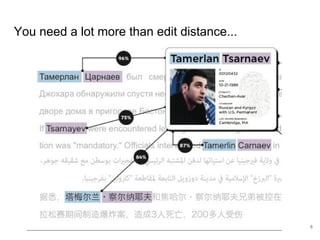


















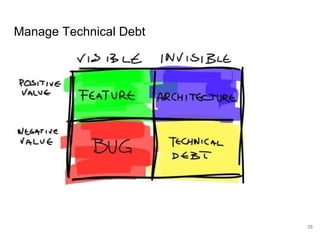
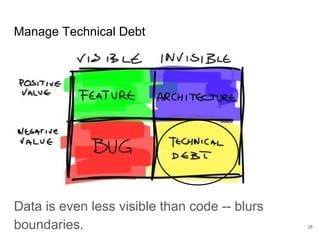









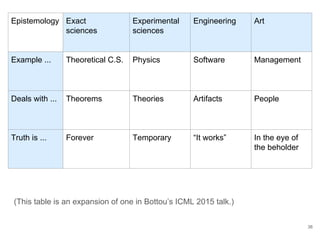
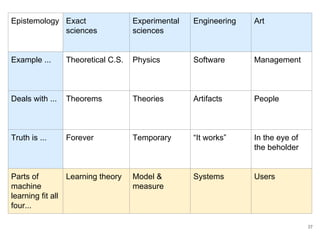
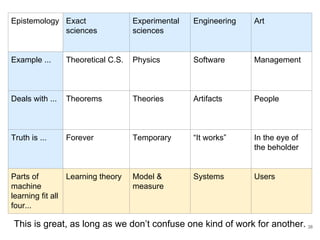

The document discusses the integration of machine learning (ML) into technology development, focusing on its role when desired behaviors cannot be fully articulated in software. It emphasizes the importance of establishing clear business metrics, understanding data representation, and the need for continuous testing to manage ML outputs effectively. Additionally, it outlines organizational structures for ML teams and considerations for experiment design and iteration in the context of technical debt and model improvement.


























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)