Download as PDF, PPTX





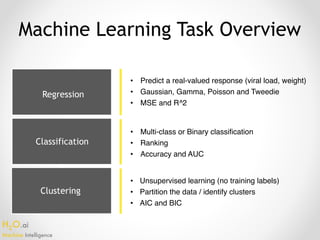
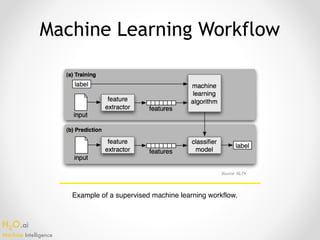





























The document outlines the top 10 pitfalls faced by data science practitioners, particularly emphasizing the importance of proper data partitioning into training, validation, and test sets, as well as the challenges of class imbalance and missing data. It discusses the consequences of data leakage, the management of categorical data, and the risk of creating 'useless' models that do not align with actionable insights. Additionally, it stresses that there is no one-size-fits-all solution in machine learning, encouraging practitioners to engage in continuous learning and iterative improvement.

































































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)








