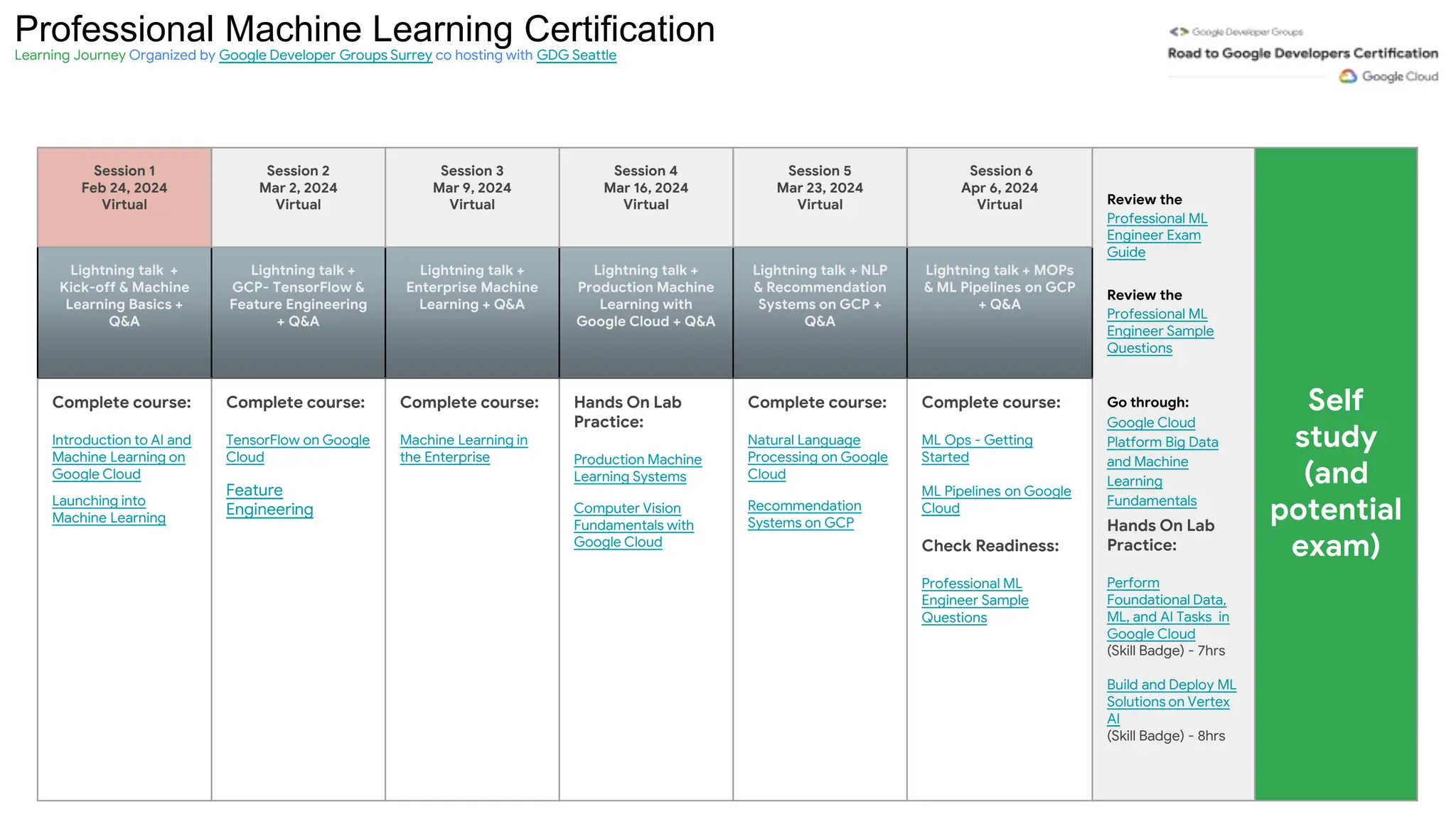
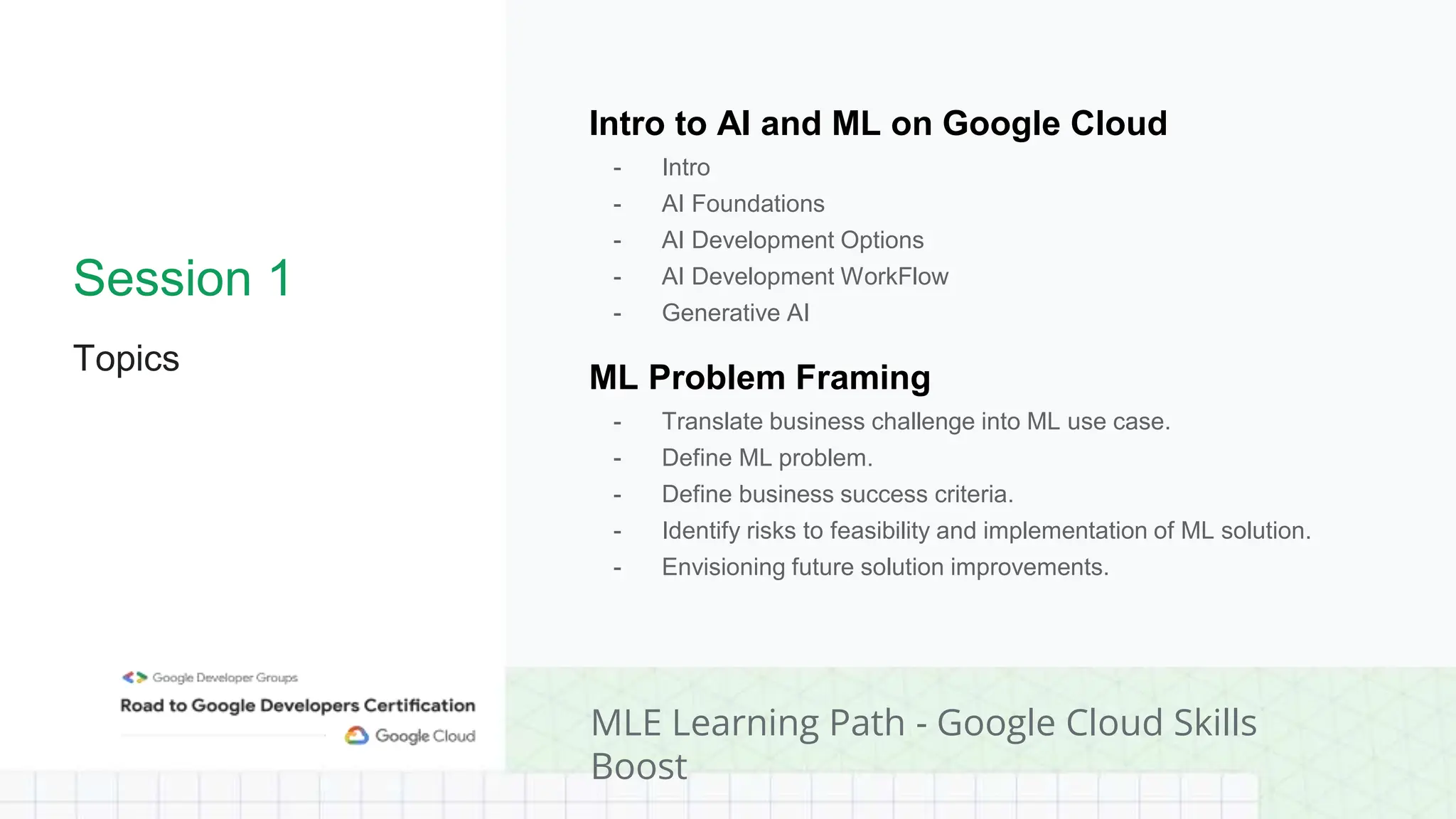
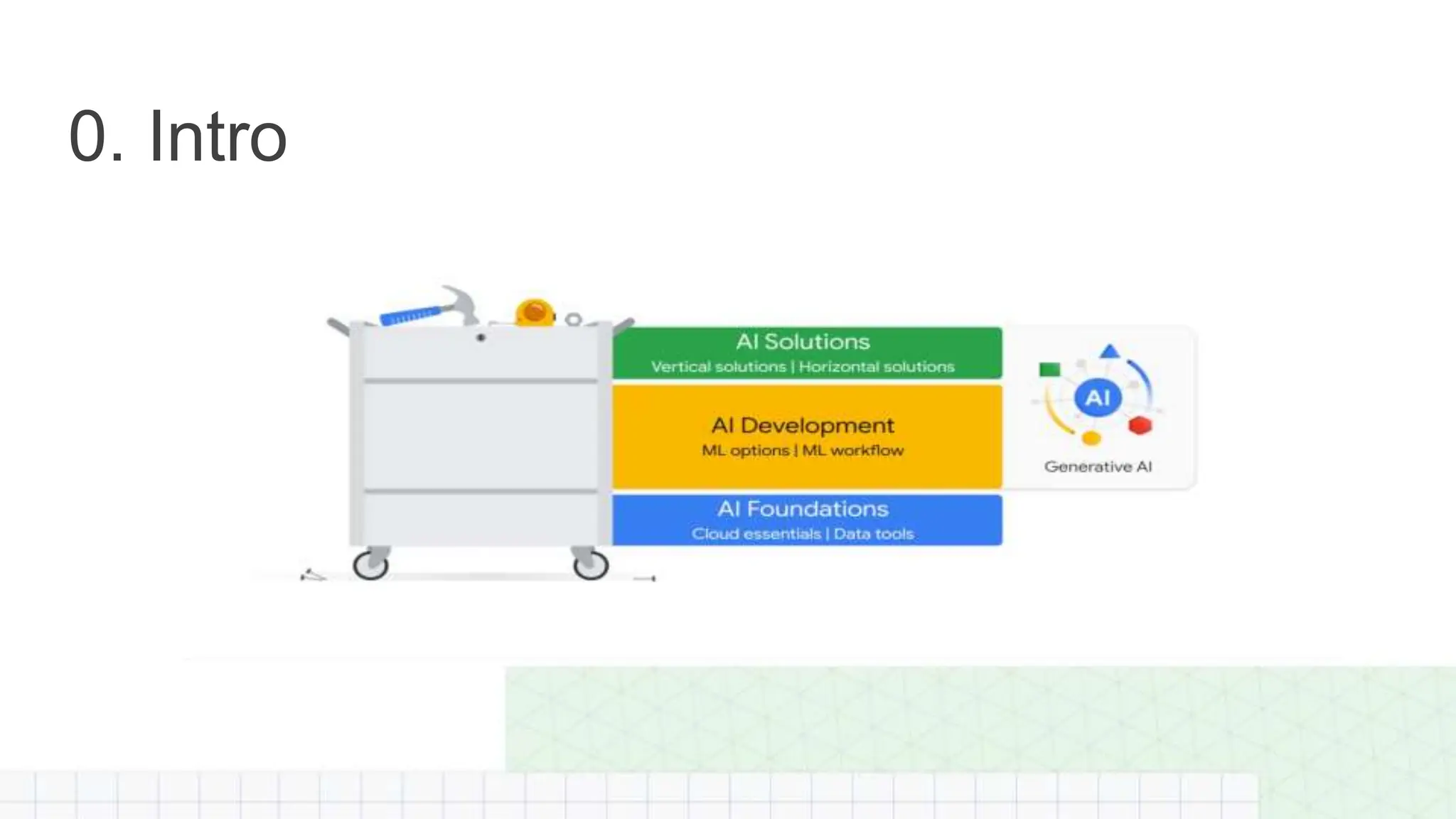
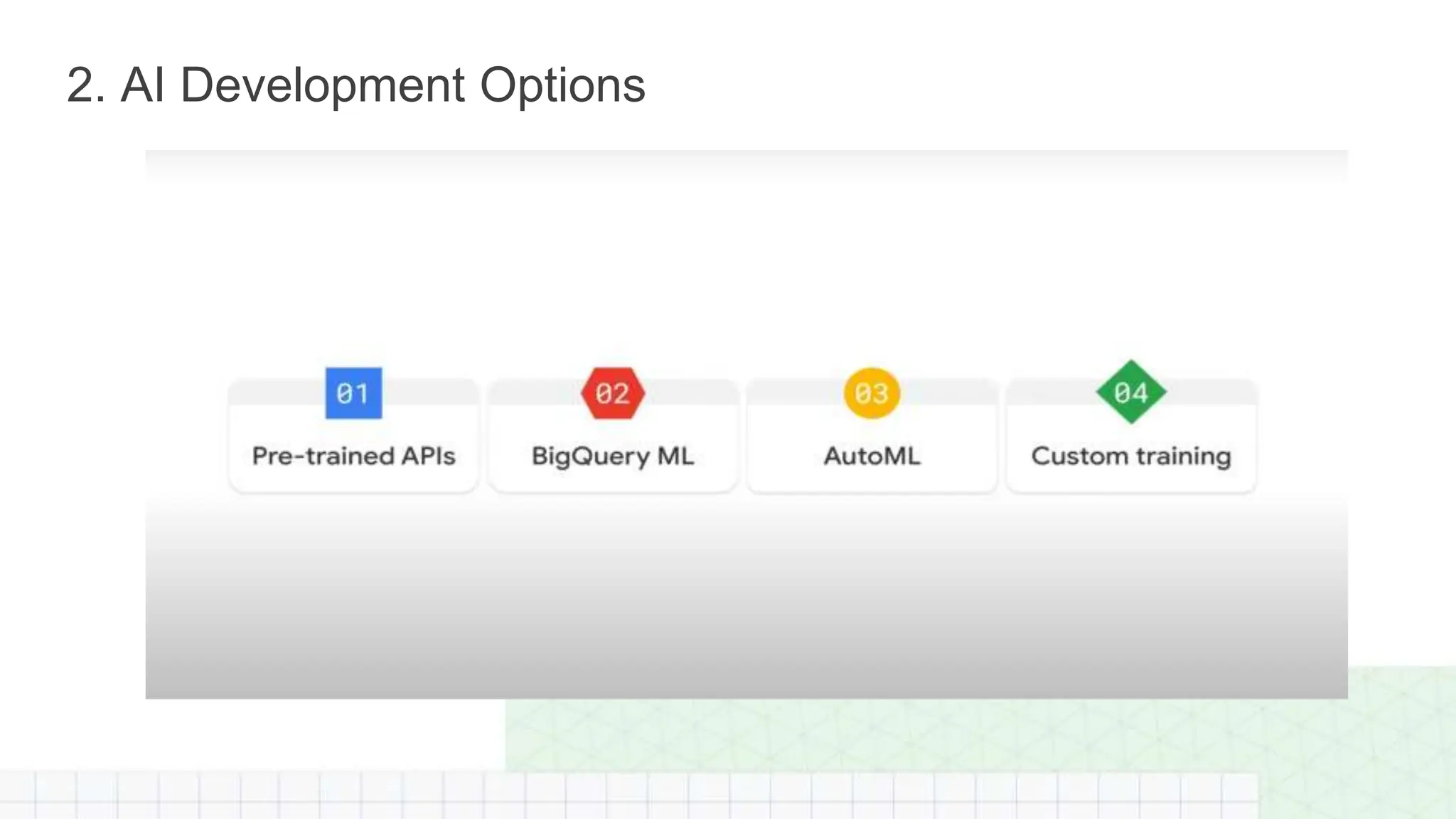
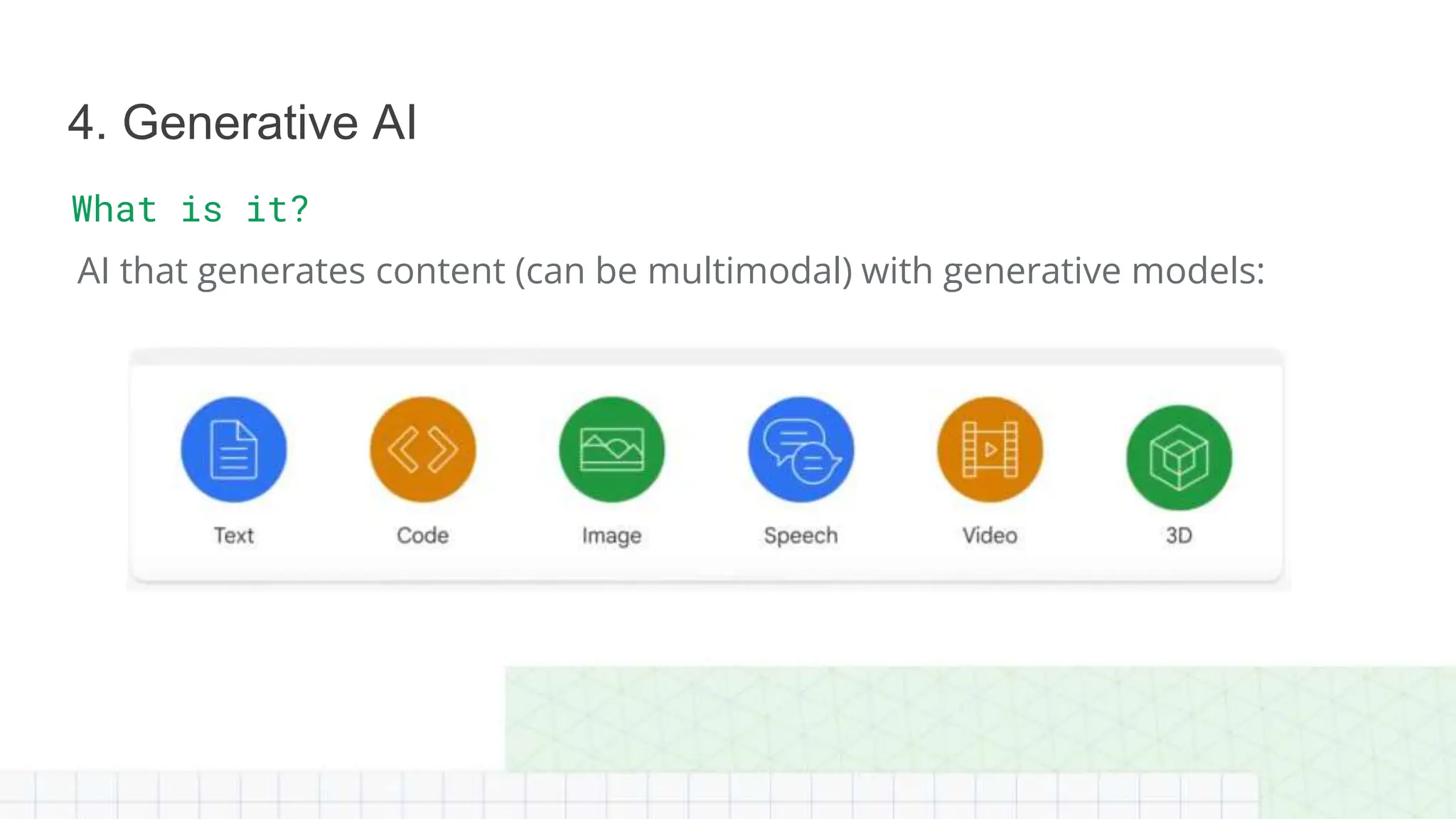
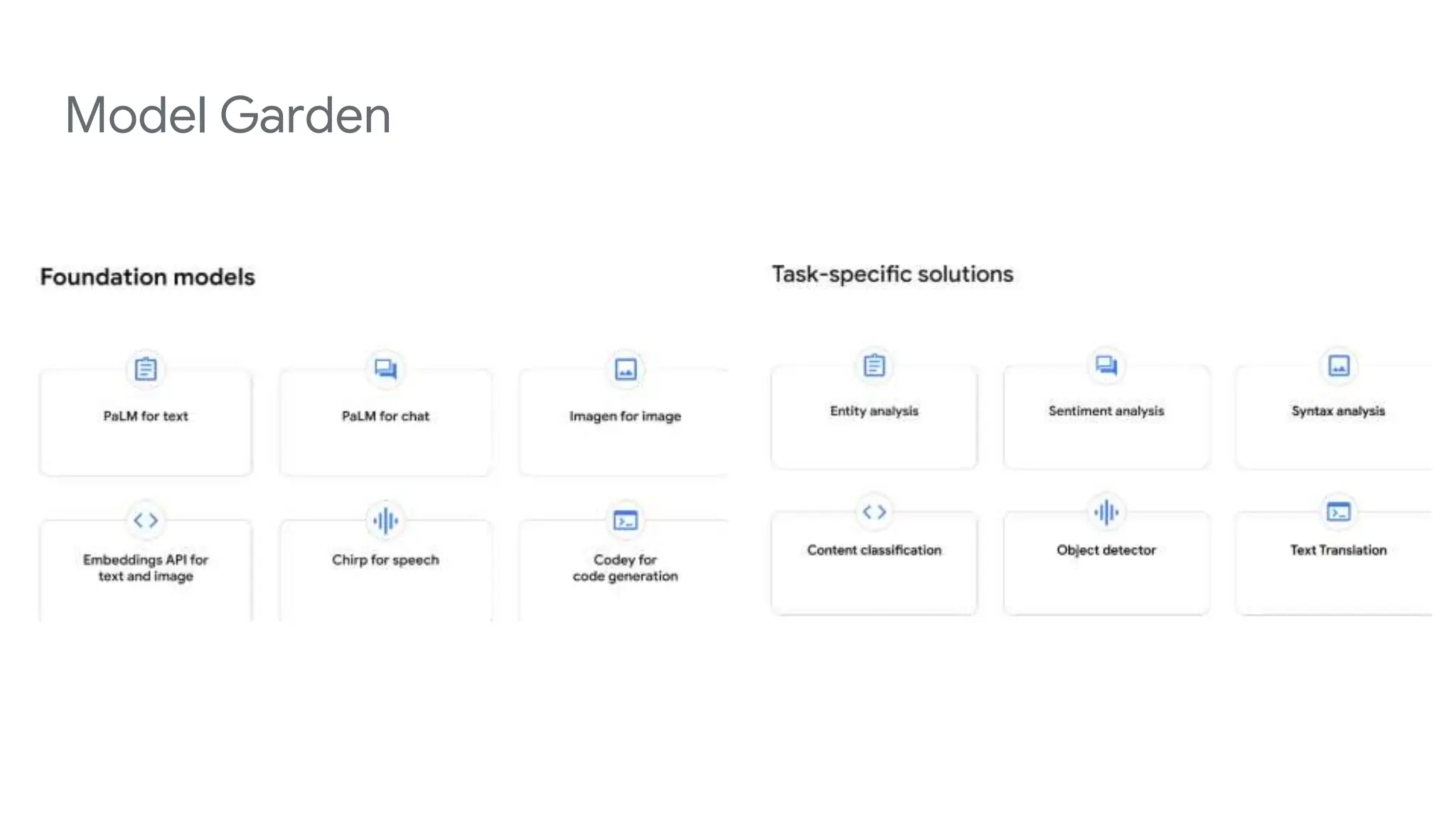
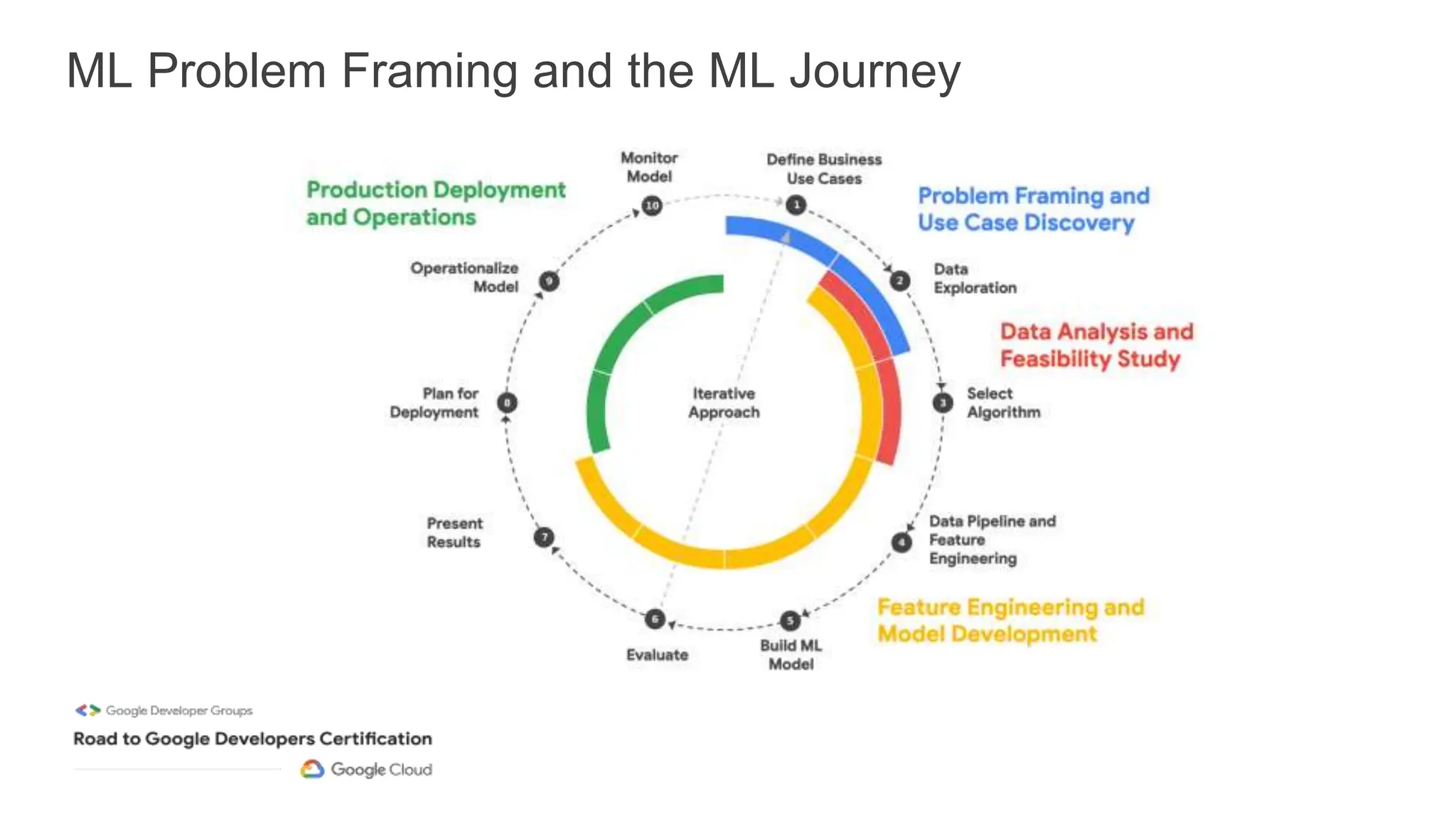
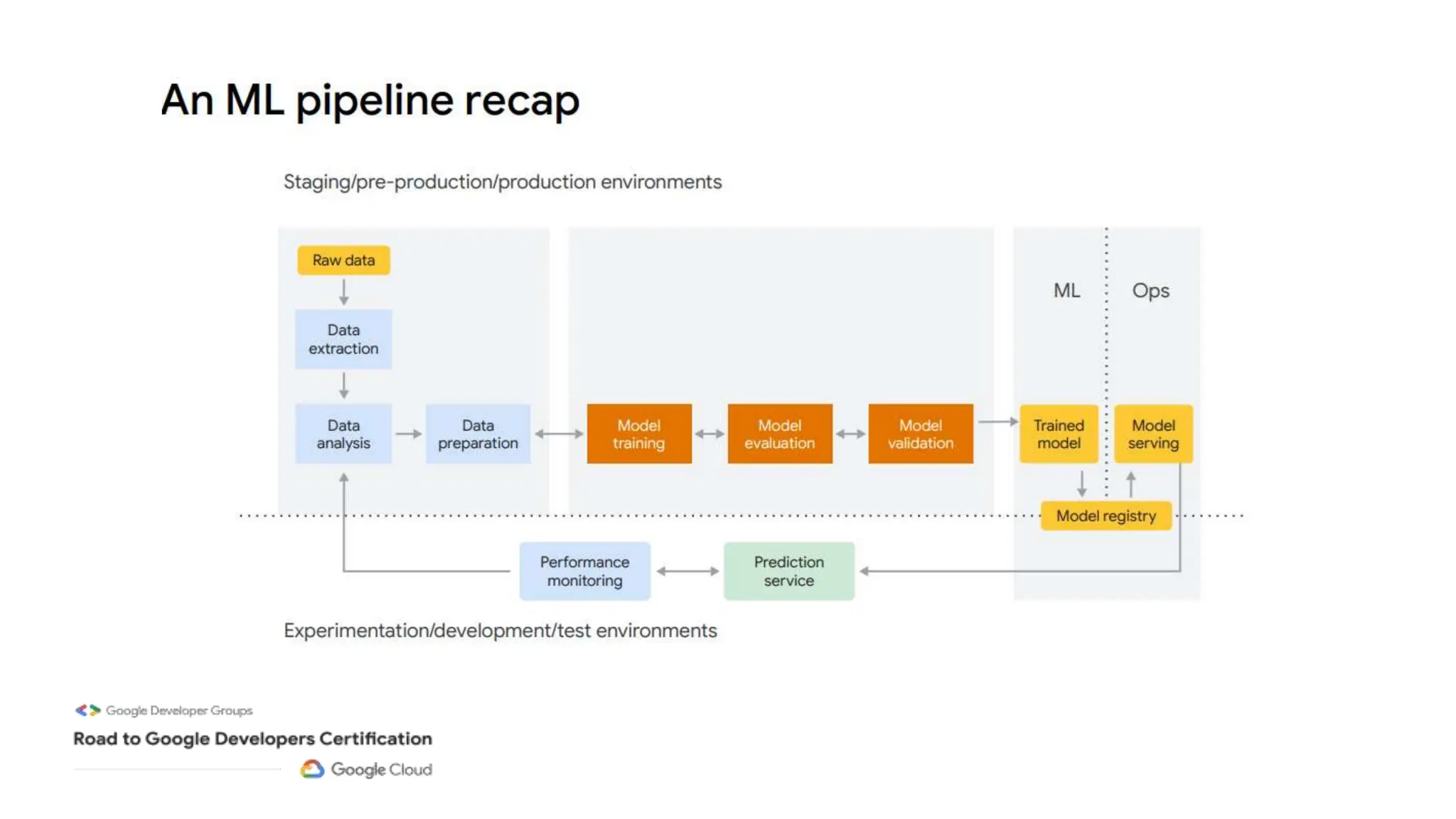
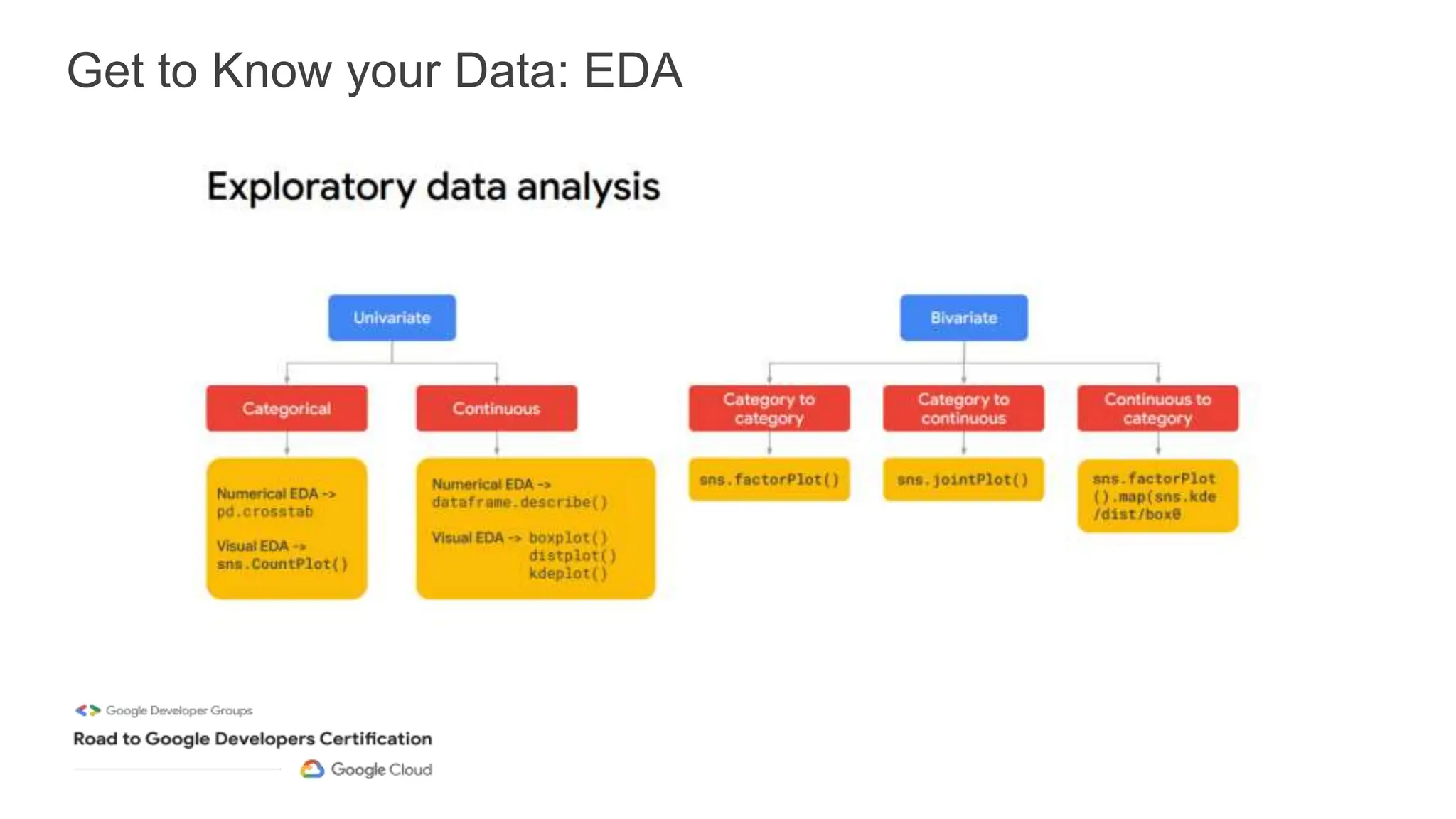
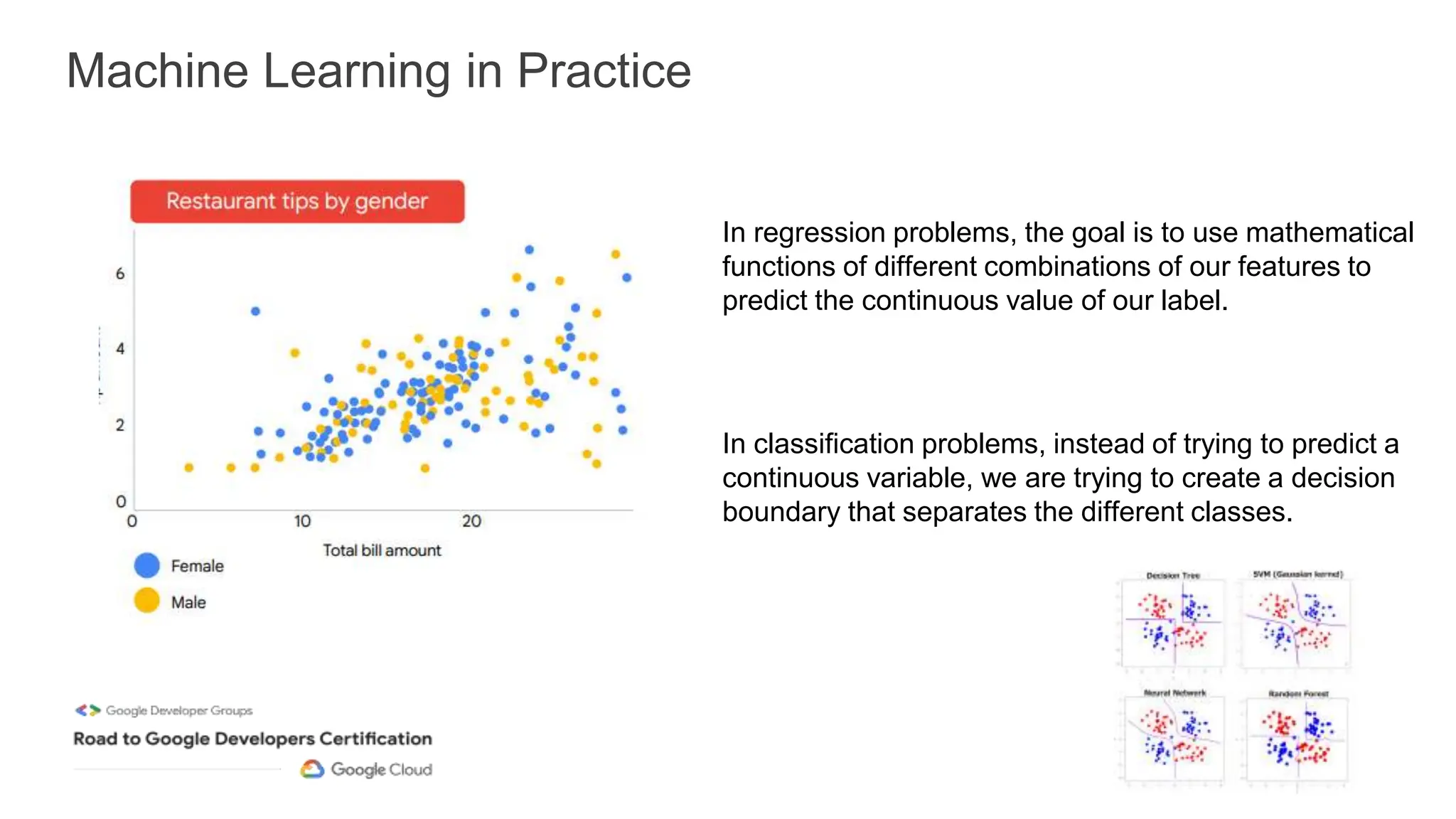
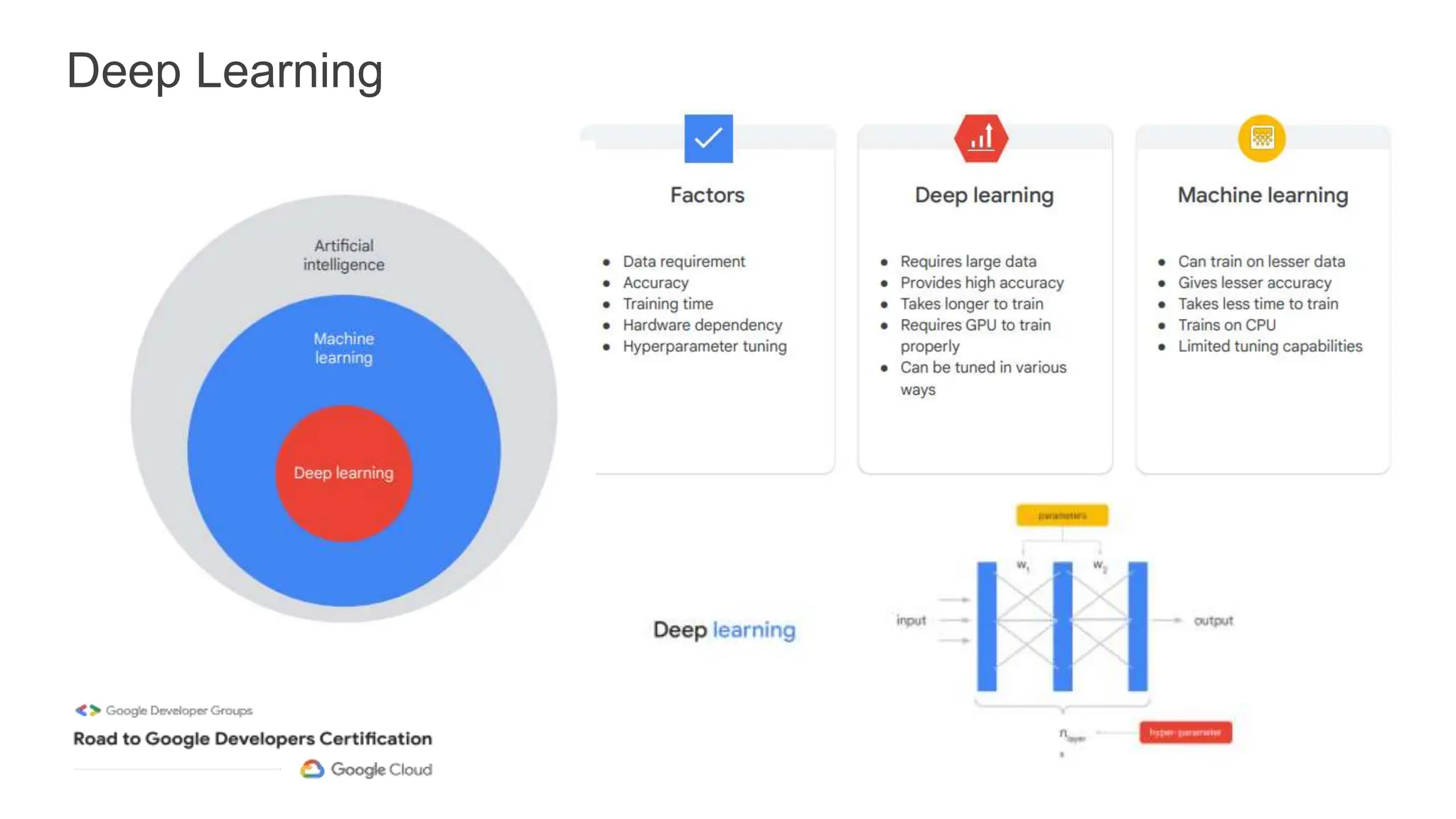
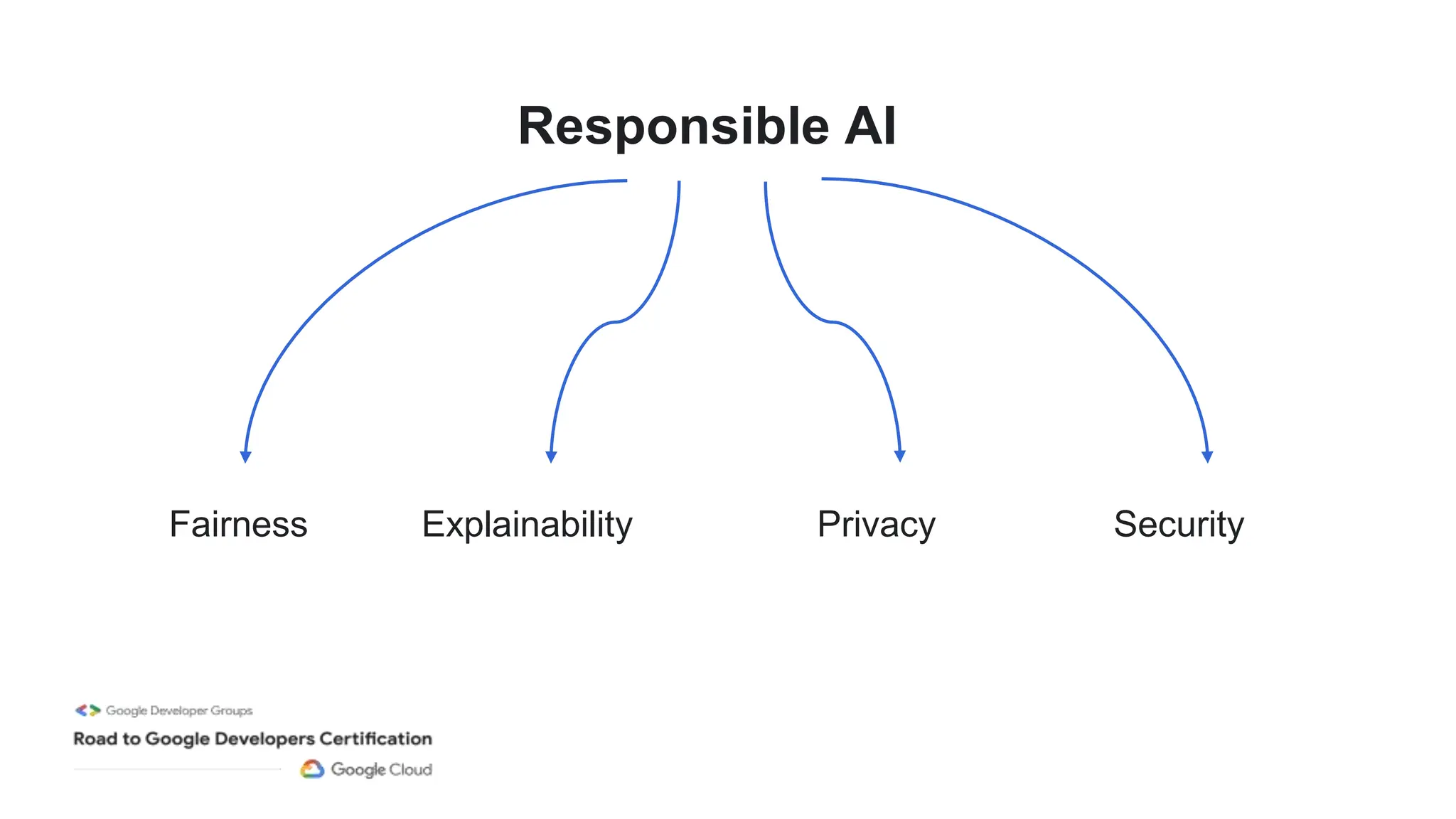
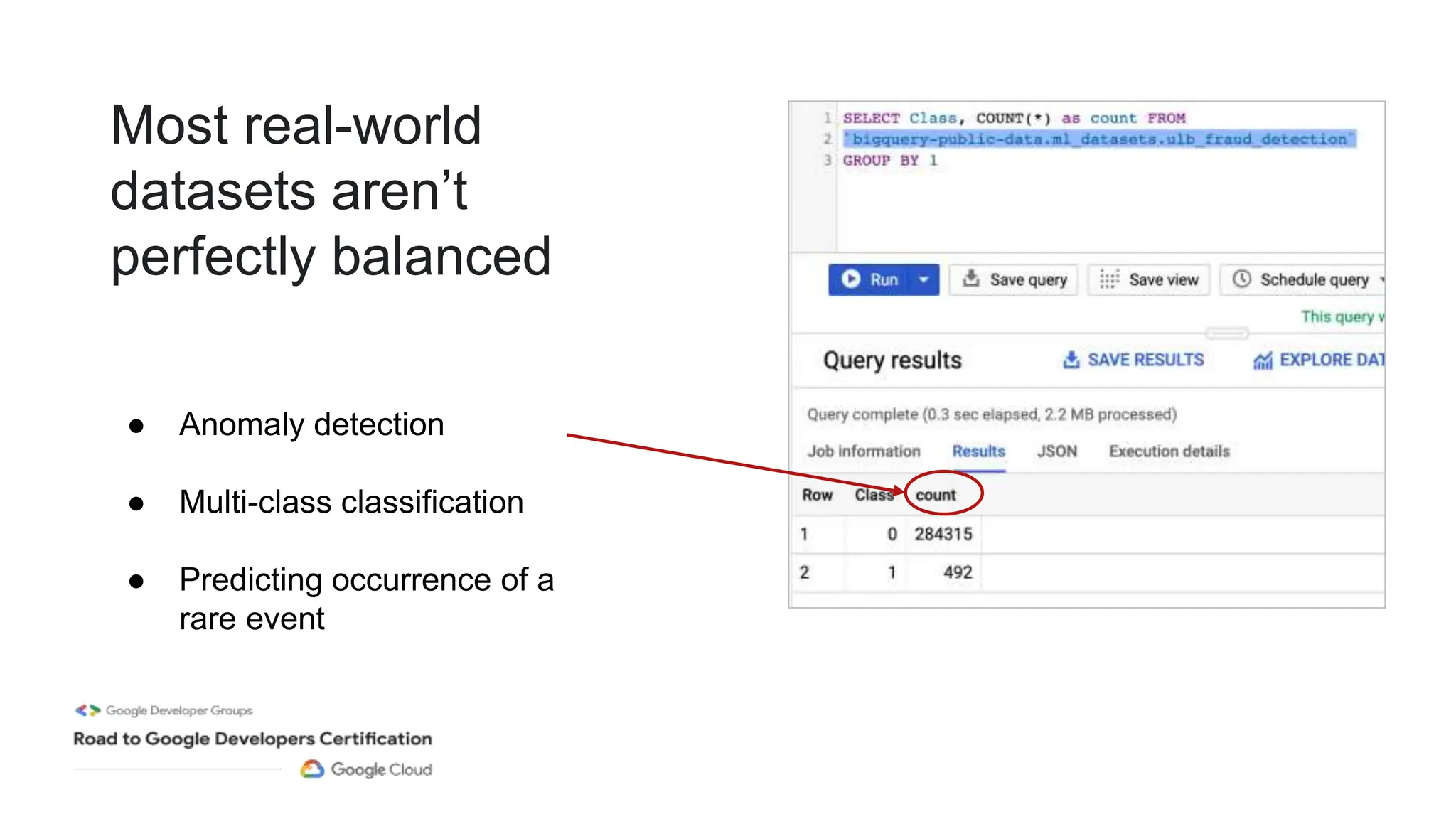
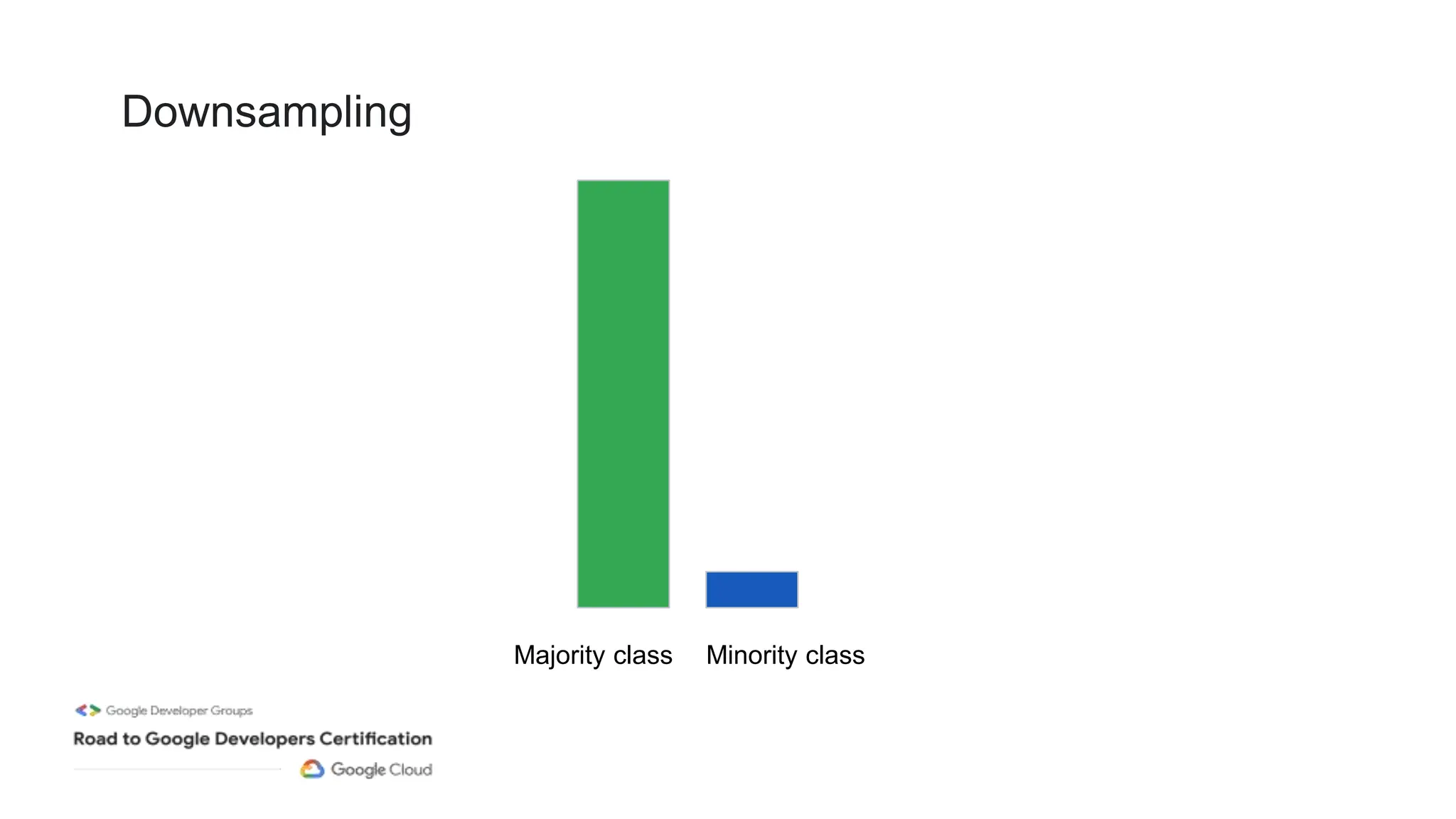
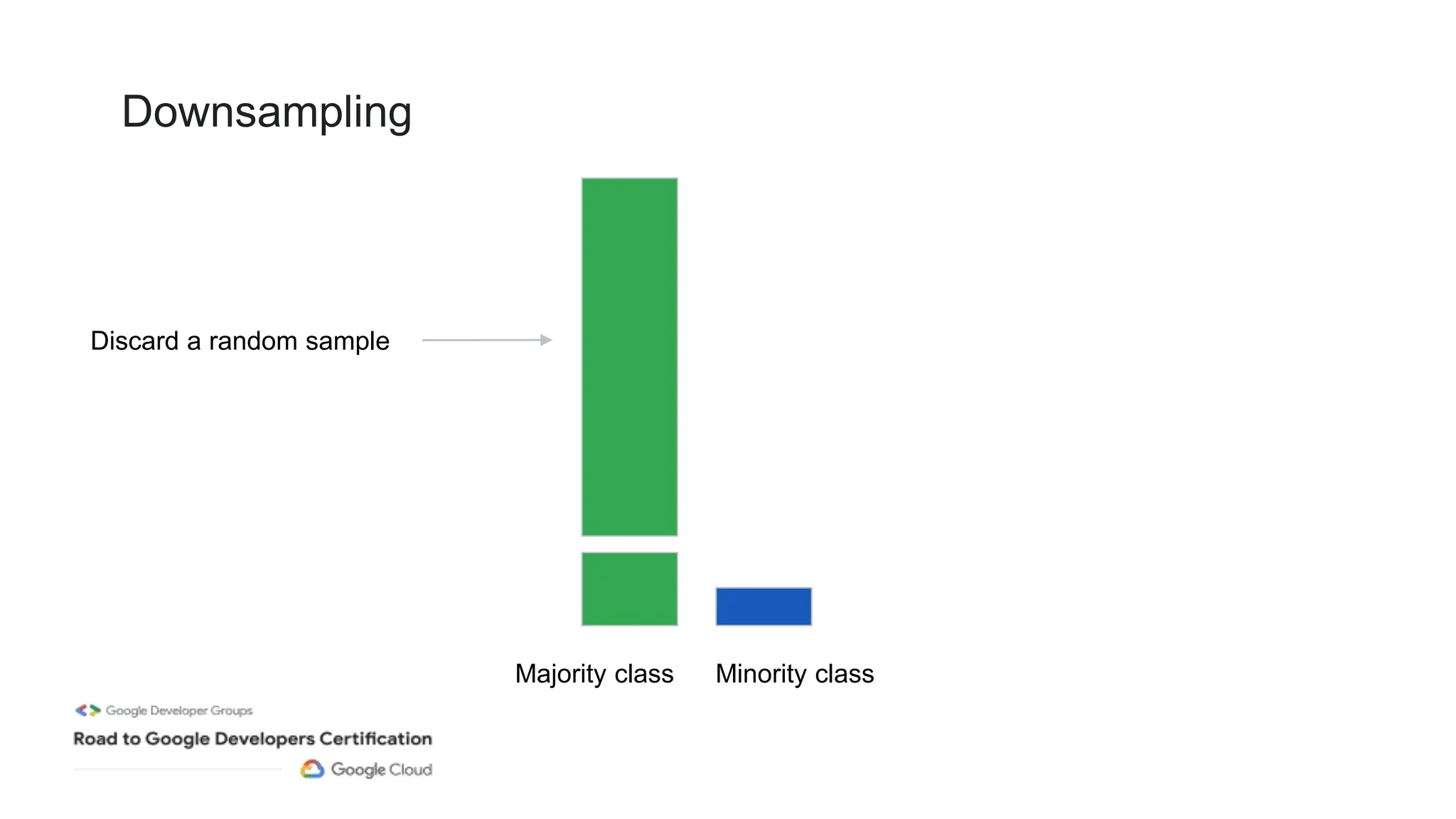
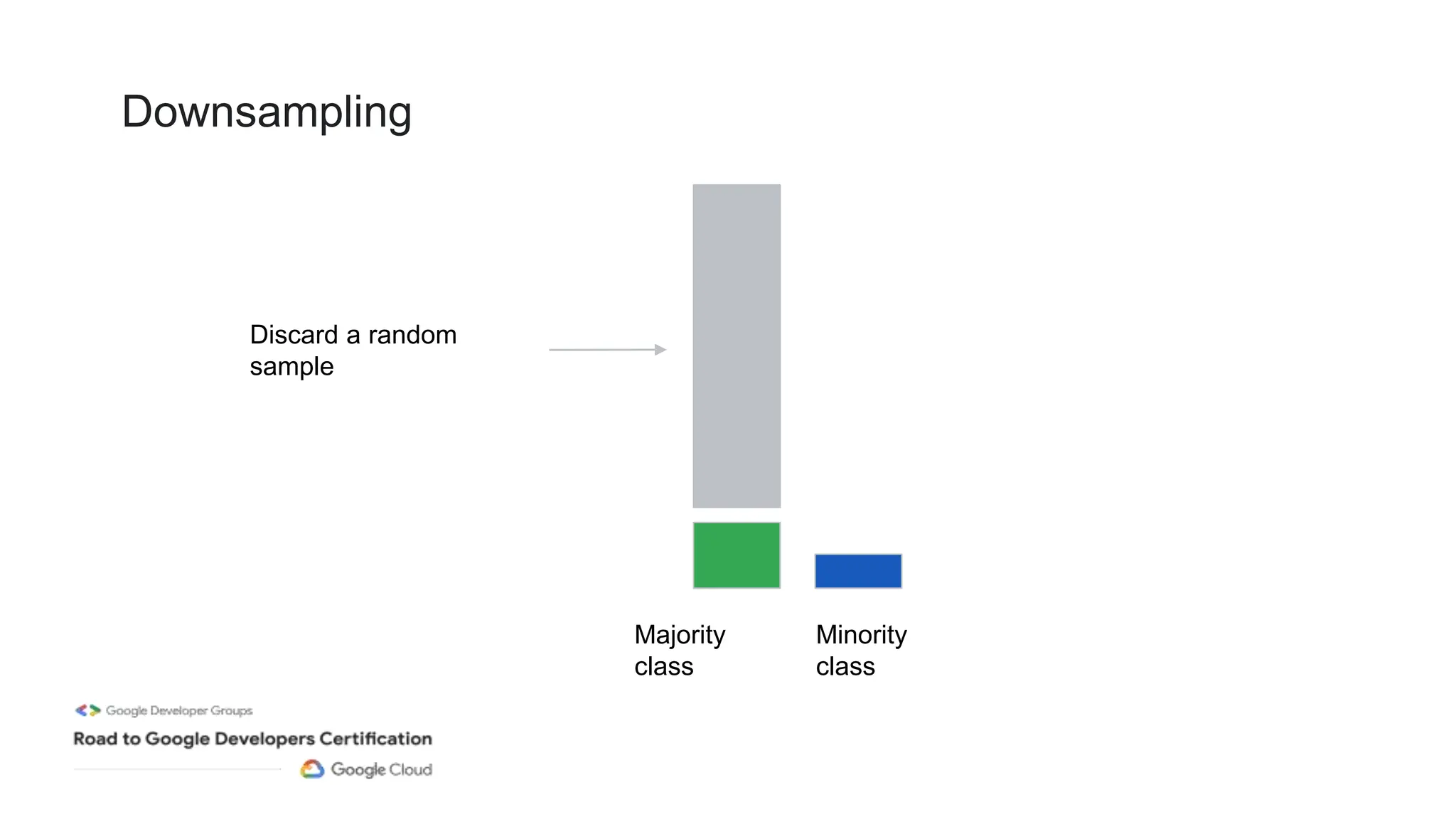
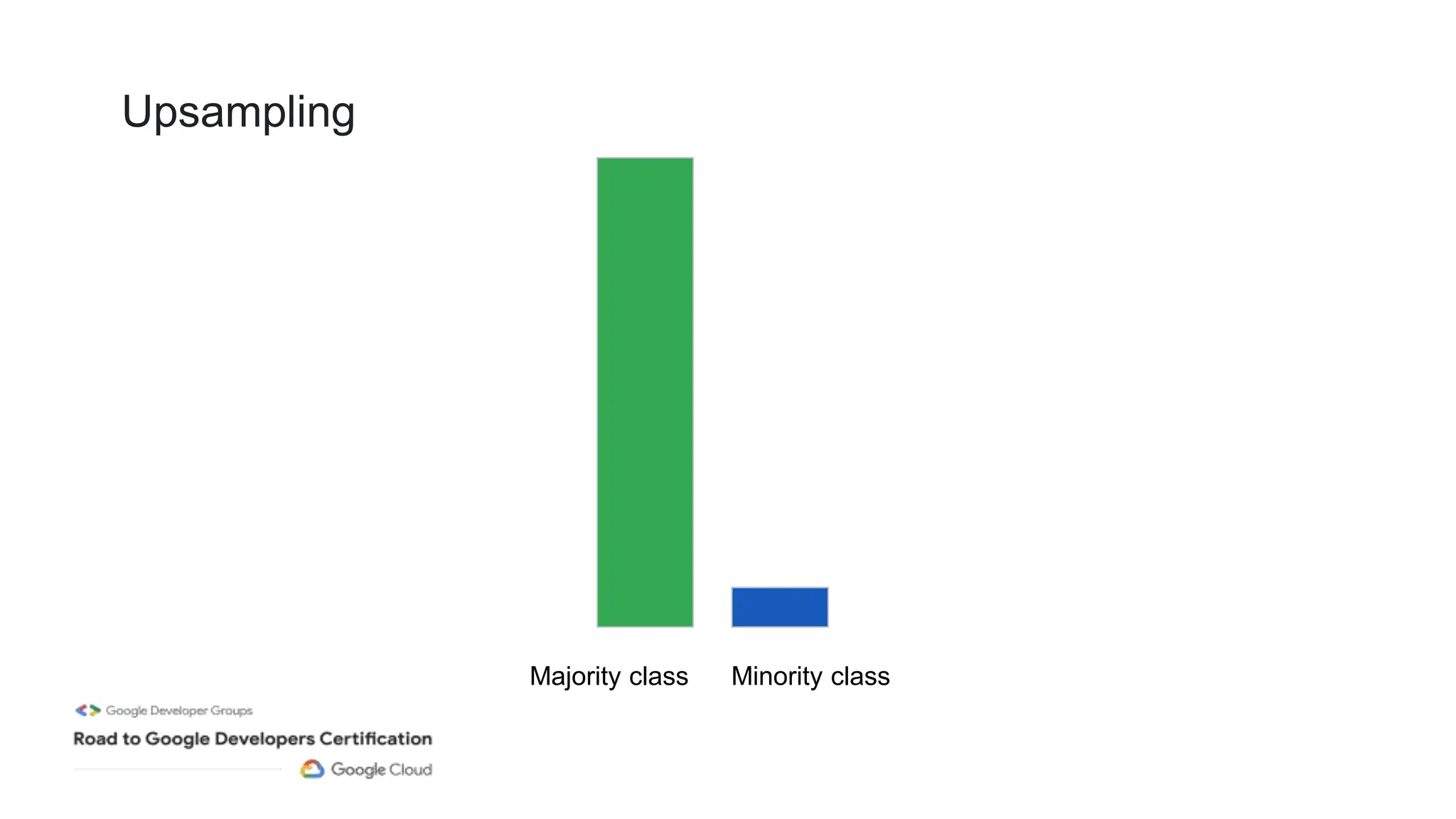
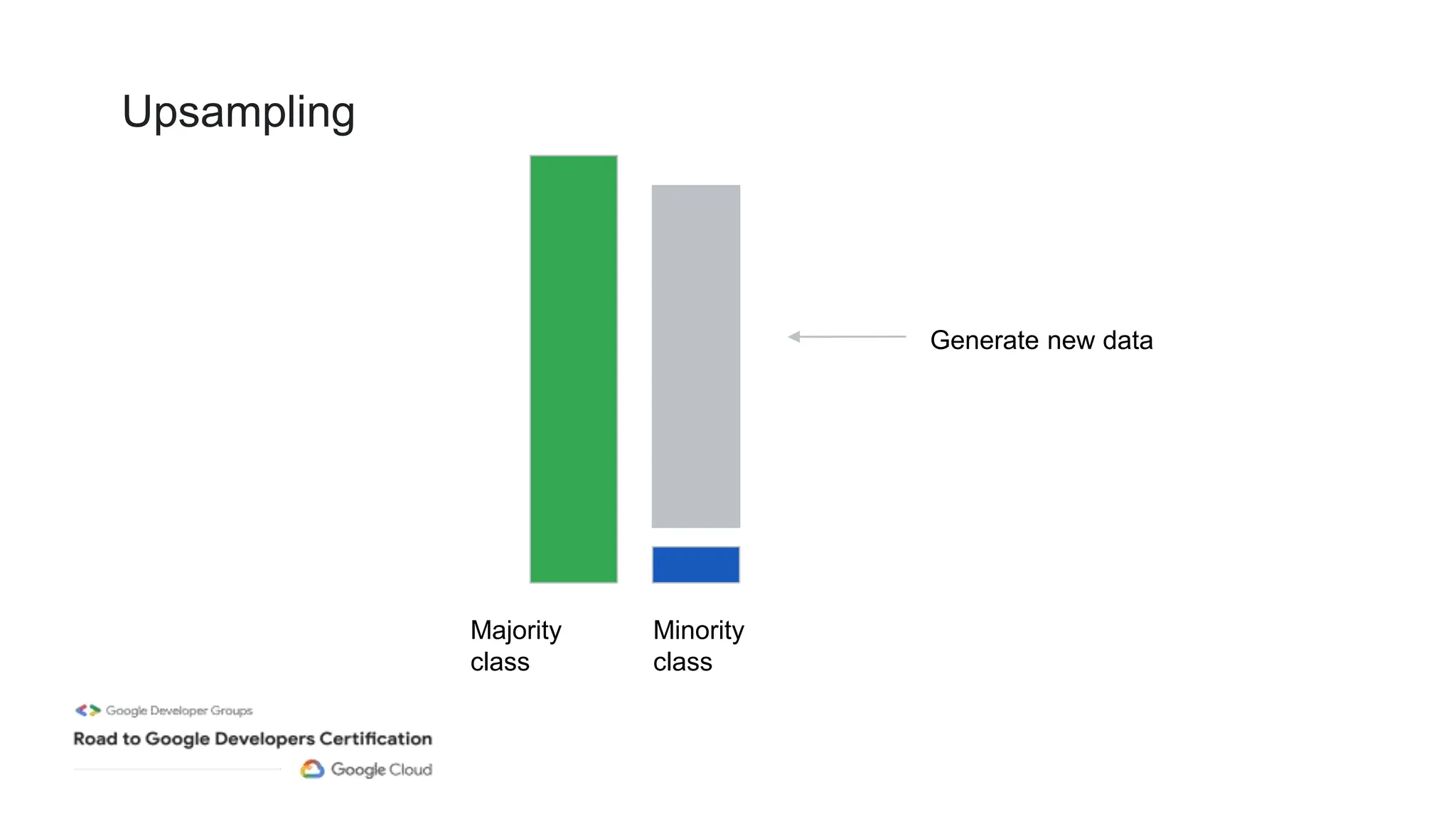
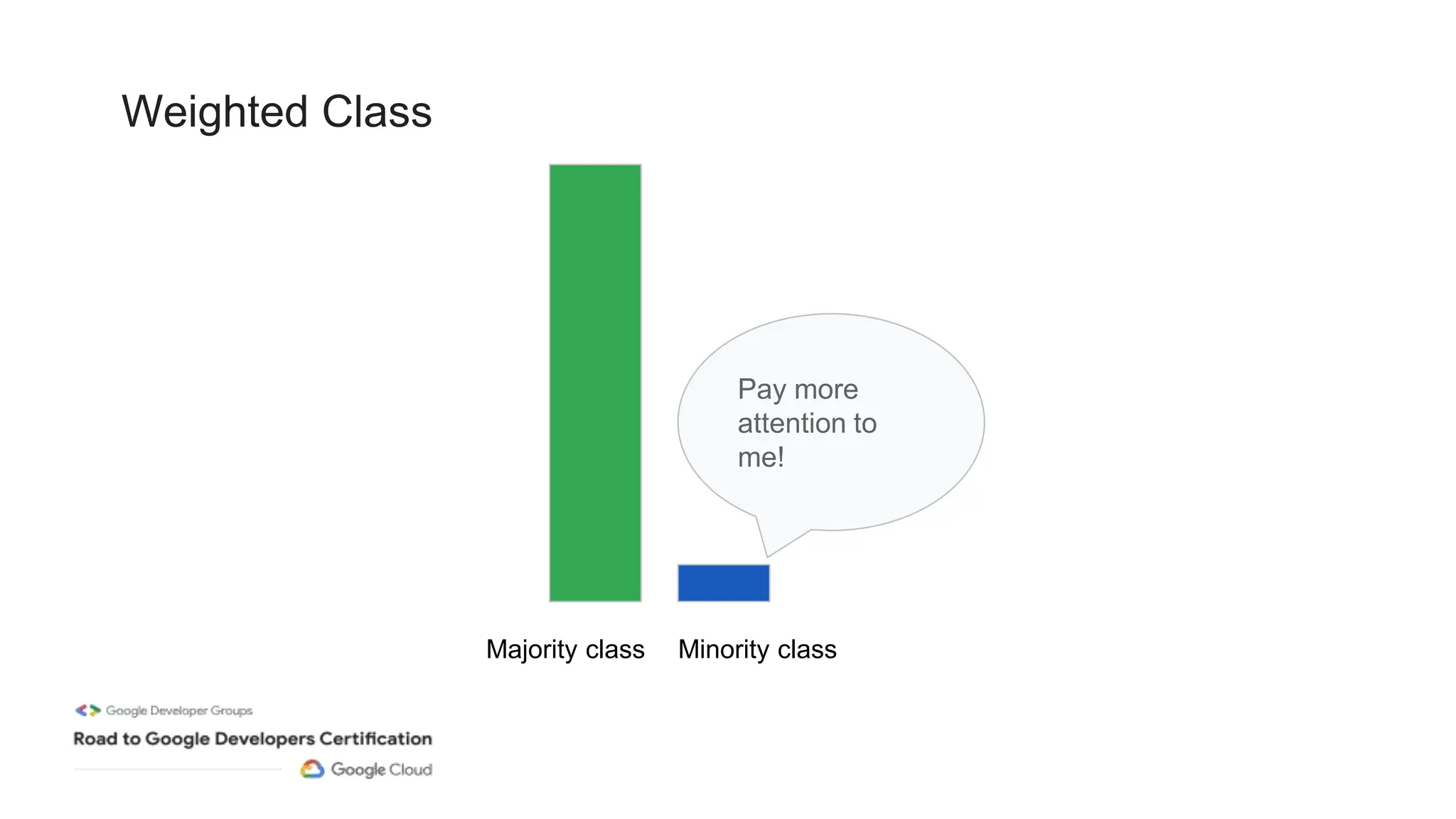
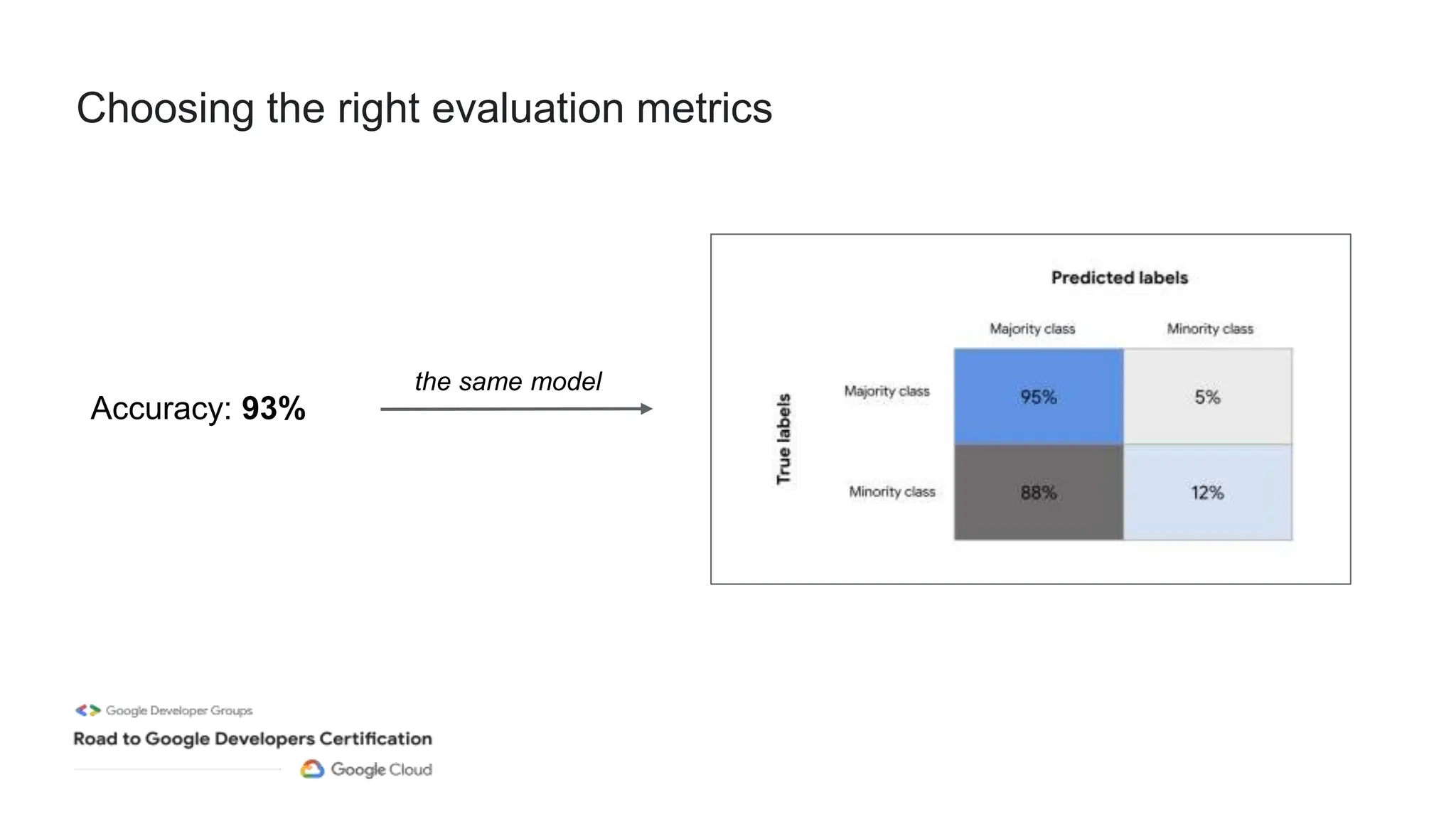
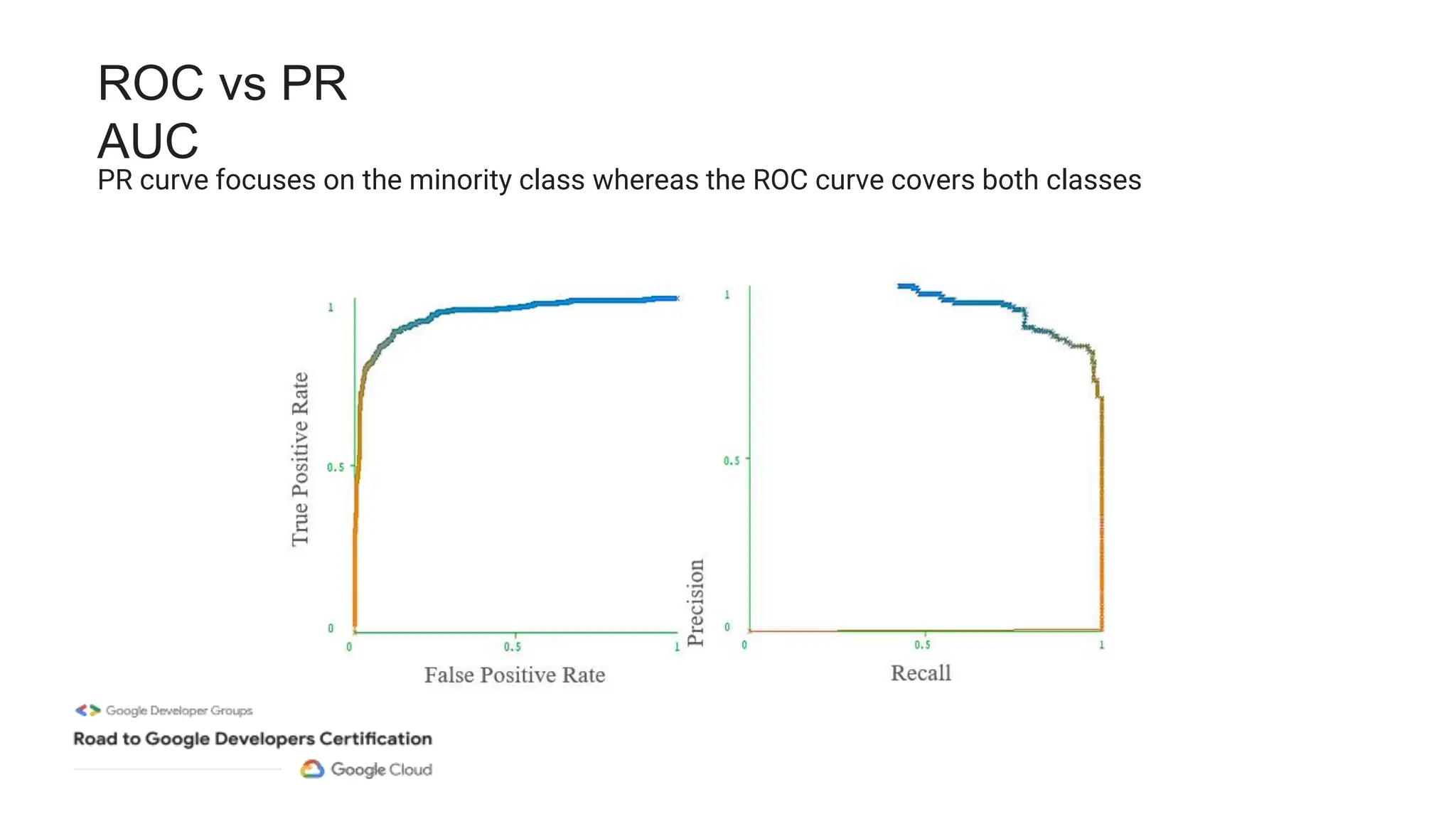
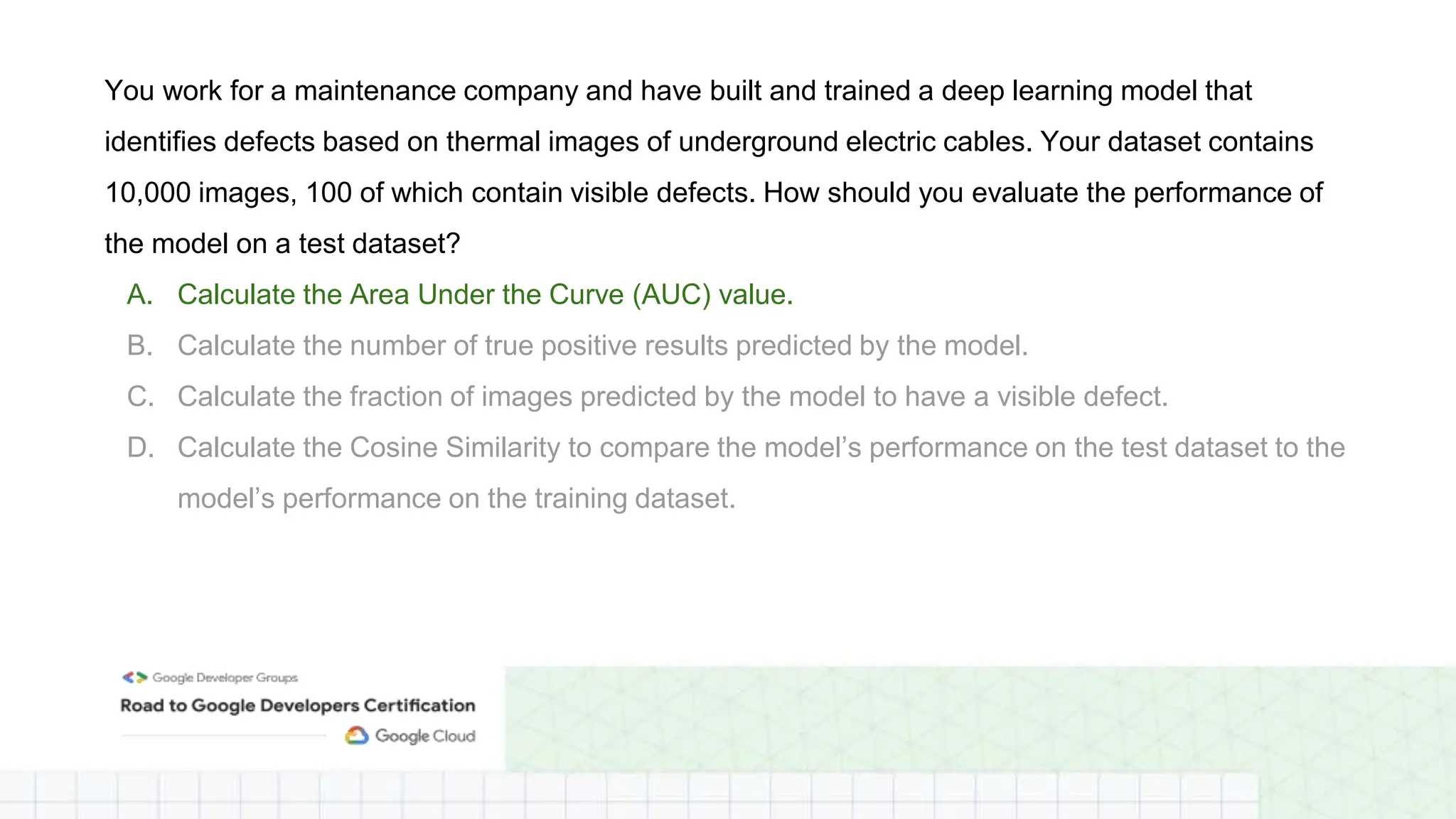
The document outlines a professional machine learning certification learning journey organized by Google Developer Groups, detailing a series of virtual sessions scheduled from February to April 2024. Key topics include AI and ML development on Google Cloud, foundational courses, hands-on lab practices, and how to prepare for the professional ML engineer exam. It also emphasizes the importance of defining ML problems, evaluation metrics, and addressing data biases in machine learning projects.