Download as PDF, PPTX










































































![Machine learning can’t
really be called “intelligent”
unless you allow for
exploration
Direct Feedback Loops. A model may directly influence the
selection of its own future training data. It is common practice to
use standard supervised algorithms, although the theoretically
correct solution would be to use bandit algorithms. The problem
here is that bandit algorithms (such as contextual bandits [9]) do
not necessarily scale well to the size of action spaces typically
required for real-world problems. It is possible to mitigate these
effects by using some amount of randomization [3], or by isolating
certain parts of data from being influenced by a given model.
Hidden Technical Debt in Machine Learning (D. Sculley, Gary Holt, Daniel Golovin et al),
http://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf](https://image.slidesharecdn.com/inconvenienttruthsaboutappliedmachinelearning-190515170259/85/In-convenient-truths-about-applied-machine-learning-82-320.jpg)














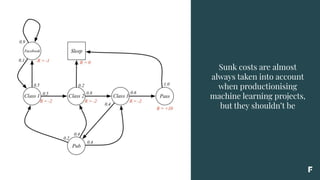
![Sunk costs are almost
always taken into account
when productionising
machine learning projects,
but they shouldn’t be
In 1968 Knox and Inkster,[2] in what is perhaps the classic sunk
cost experiment, approached 141 horse bettors: 72 of the people
had just finished placing a $2.00 bet within the past 30 seconds, and
69 people were about to place a $2.00 bet in the next 30 seconds.
Their hypothesis was that people who had just committed
themselves to a course of action (betting $2.00) would reduce
post-decision dissonance by believing more strongly than ever that
they had picked a winner. Knox and Inkster asked the bettors to
rate their horse's chances of winning on a 7-point scale. What they
found was that people who were about to place a bet rated the
chance that their horse would win at an average of 3.48 which
corresponded to a "fair chance of winning" whereas people who
had just finished betting gave an average rating of 4.81 which
corresponded to a "good chance of winning".](https://image.slidesharecdn.com/inconvenienttruthsaboutappliedmachinelearning-190515170259/85/In-convenient-truths-about-applied-machine-learning-97-320.jpg)







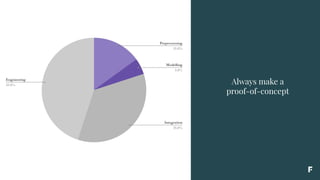
This document provides observations and recommendations for reconciling machine learning with business needs. Some key points made include: - In many cases, machine learning is not needed to solve a problem and simpler solutions like collecting missing data can work better. - The data companies already have is sometimes useless for machine learning problems. Domain expertise alone also often means less than expected. - Not understanding technical constraints can cause machine learning projects to fail. Always create a proof-of-concept first before full development. - It is important to establish causality through proper testing like A/B testing, as this validates models and addresses financial risks of implementations. - Framing learning problems is challenging due to issues like lous

































































