Download as PDF, PPTX











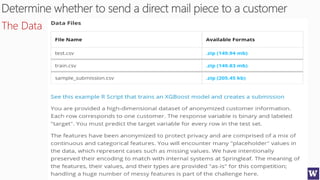
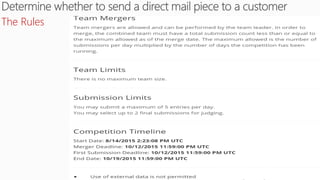
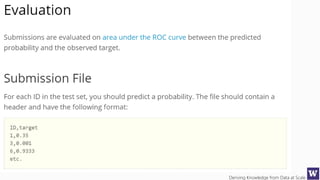



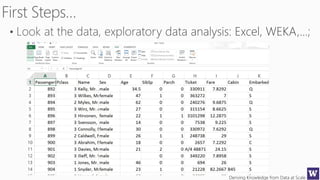



























































![Deriving Knowledge from Data at Scale
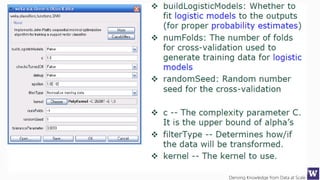
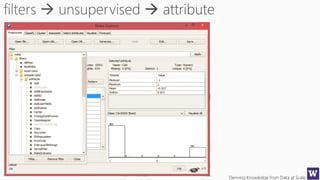
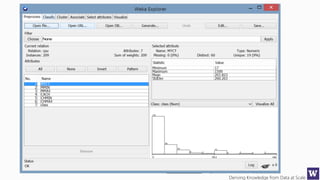
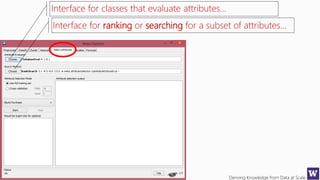
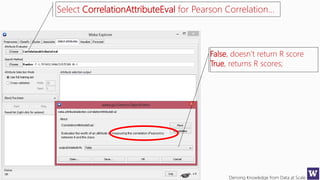
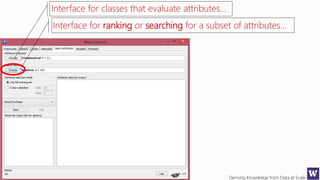
Ranks attributes by their individual evaluations, used in
conjunction with GainRatio, Entropy, Pearson, etc…
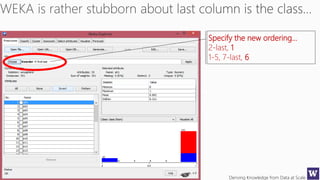
Number of attributes to return,
-1 returns all ranked attributes;
Attributes to ignore (skip) in the
evaluation forma: [1, 3-5, 10];
Cutoff at which attributes can
be discarded, -1 no cutoff;](https://image.slidesharecdn.com/bargauwdatasciencelecture7-160424211637/85/Barga-Data-Science-lecture-7-119-320.jpg)




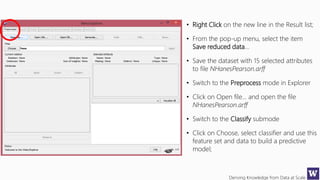
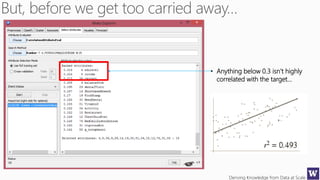





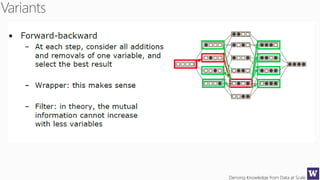
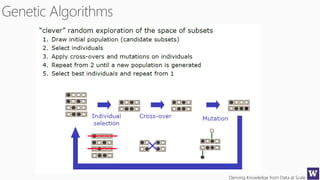
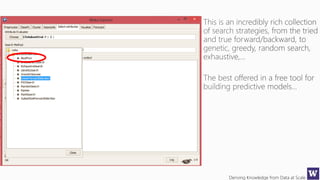
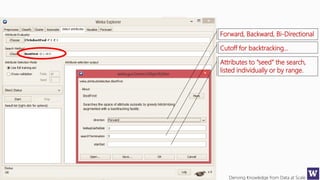
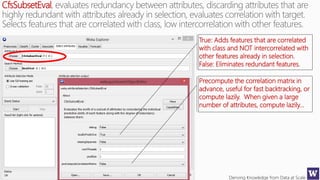





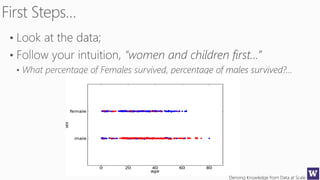
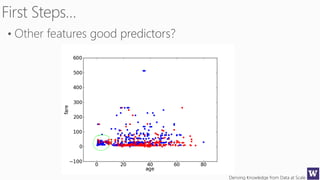
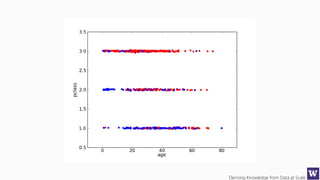
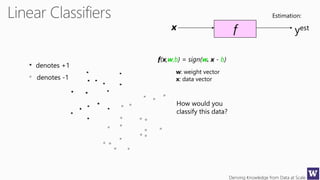
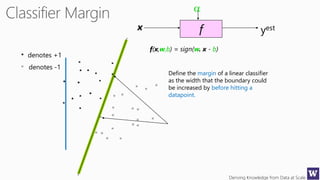
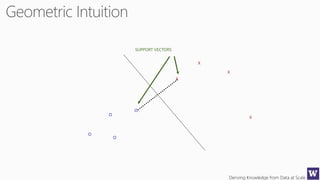
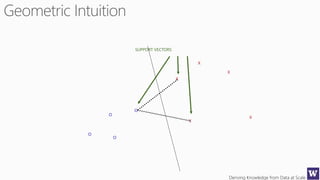
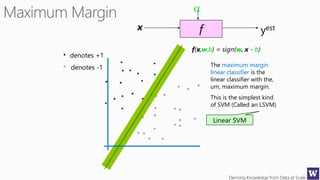
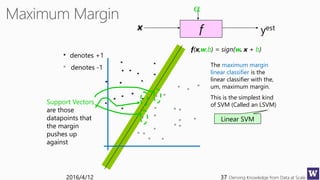
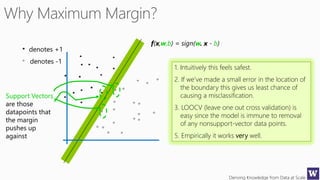
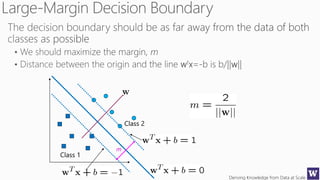
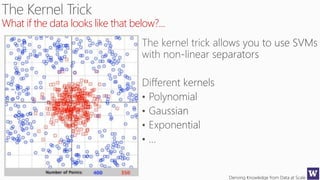
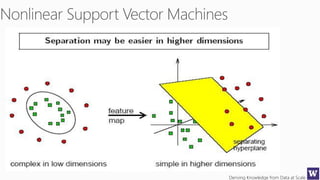
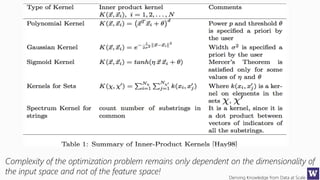
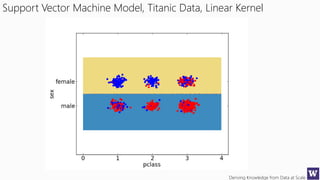
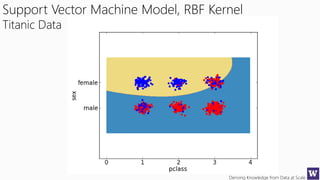
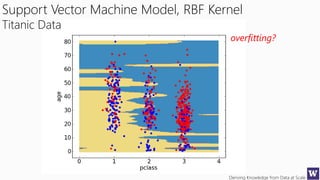
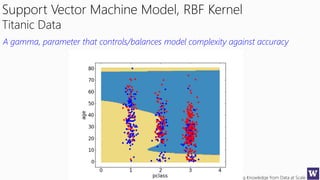
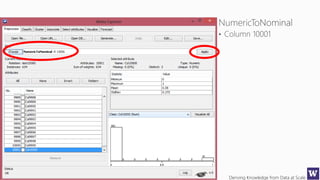
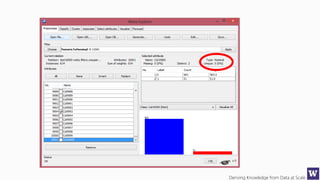
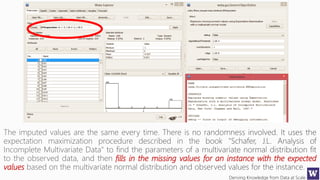
This document appears to be lecture slides for a course on deriving knowledge from data at scale. It covers many topics related to building machine learning models including data preparation, feature selection, classification algorithms like decision trees and support vector machines, and model evaluation. It provides examples applying these techniques to a Titanic passenger dataset to predict survival. It emphasizes the importance of data wrangling and discusses various feature selection methods.
































![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=640&height=640&fit=bounds)


























![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)








![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)



