Download as PDF, PPTX


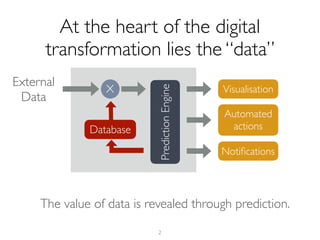












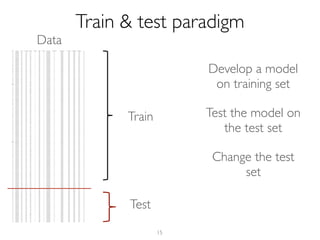
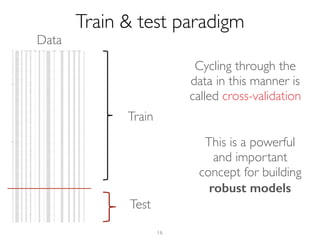


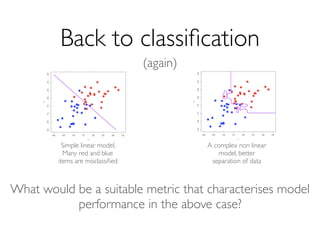
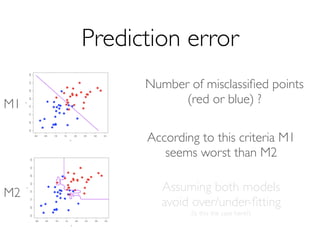








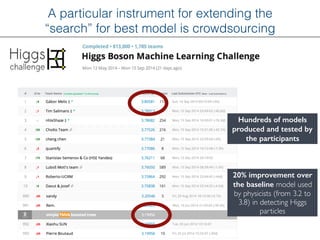

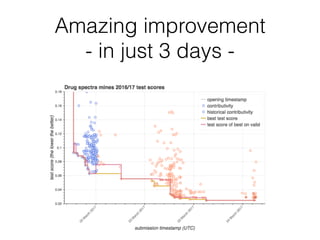

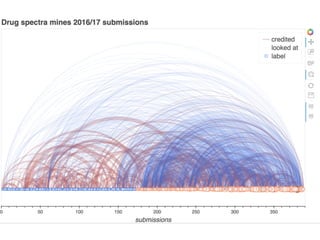
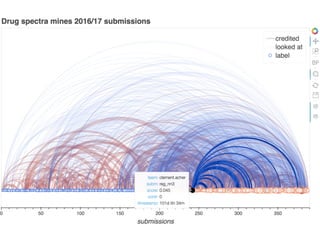



The document outlines methods for leveraging data science to drive digital transformation in business, emphasizing the importance of predictive analytics and the need for robust data management. Key aspects include identifying relevant data sources, evaluating predictive model performance, and addressing challenges in developing and deploying data-driven models. The document also discusses the role of collaboration, experimentation, and iterative processes in enhancing predictive accuracy and achieving business goals.



































































