Downloaded 80 times







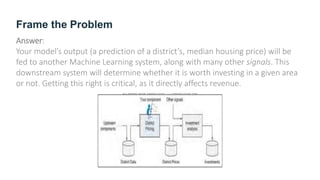








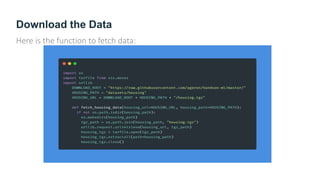
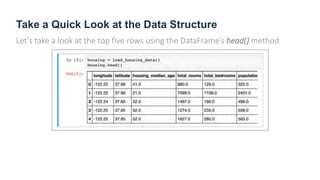
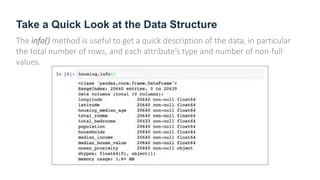


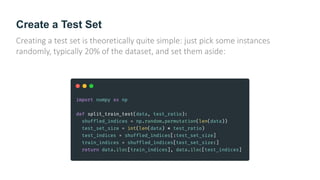
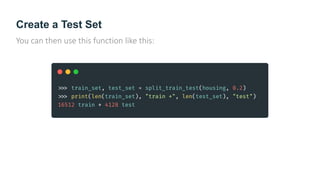

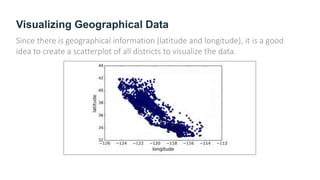
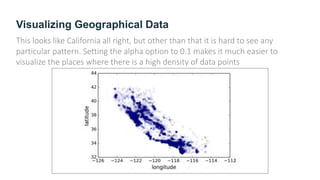

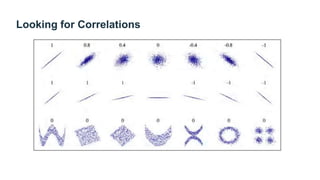

















The document provides guidance on building an end-to-end machine learning project to predict California housing prices using census data. It discusses getting real data from open data repositories, framing the problem as a supervised regression task, preparing the data through cleaning, feature engineering, and scaling, selecting and training models, and evaluating on a held-out test set. The project emphasizes best practices like setting aside test data, exploring the data for insights, using pipelines for preprocessing, and techniques like grid search, randomized search, and ensembles to fine-tune models.






















































































