Download as PDF, PPTX



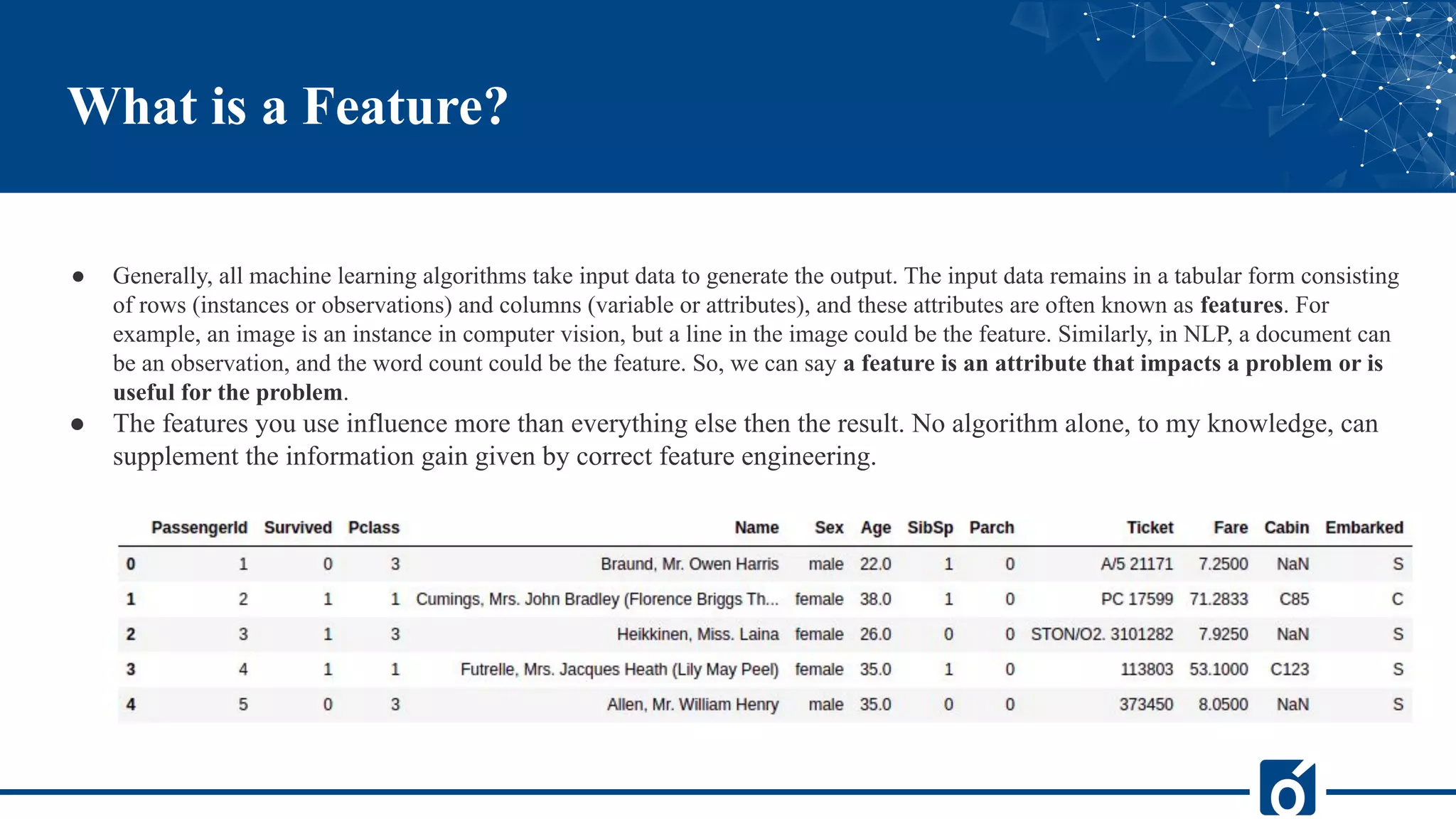
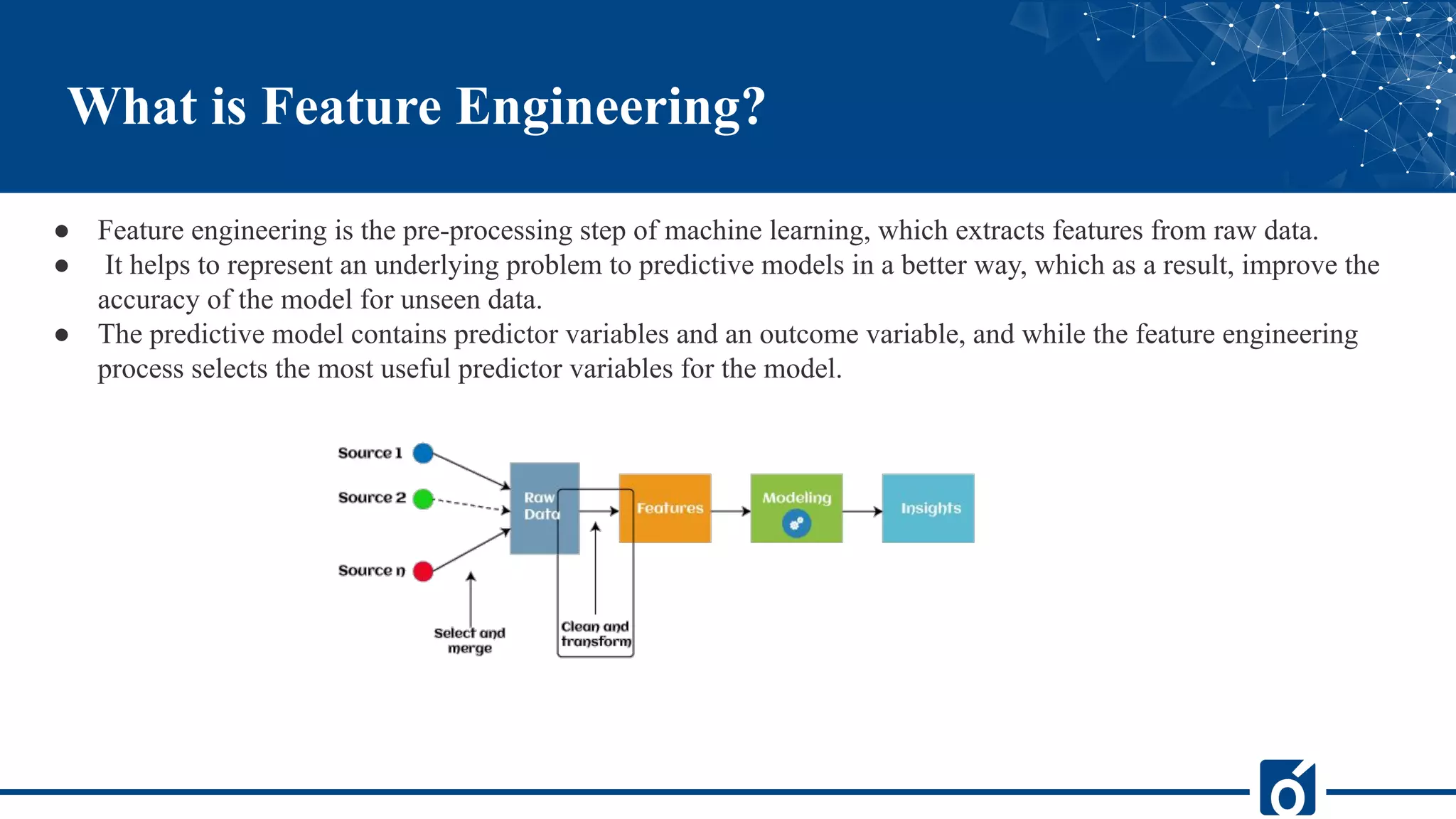










The document covers the concept of feature engineering in machine learning, explaining its definition, importance, and techniques. It outlines the main processes involved in feature engineering, such as data preparation and exploratory analysis, and highlights various techniques like imputation, handling outliers, and encoding. Overall, effective feature engineering is presented as crucial for enhancing model performance and accuracy.





































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

















