This document summarizes a presentation on deep neural networks and computational graphs. It discusses how neural networks work using an example of a network with inputs, hidden layers, and an output. It also explains key concepts like activation functions, backpropagation for updating weights, and how the chain rule is applied in backpropagation. Computational graphs are introduced as a way to represent mathematical expressions and evaluate gradients to train neural networks.





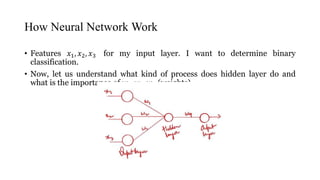



![Neural Network with Back Propagation
• Let us consider a dataset
• Forward propagation: Let Inputs are 𝑥1, 𝑥2, 𝑥3. These inputs will pass to
neuron. Then 2 important operations will take place
y= [𝑤1 𝑥1 + 𝑤2 𝑥2 + 𝑤3 𝑥3]+𝑏𝑖
z= Act (y) * Sigmoid Activation function
𝒙 𝟏 𝒙 𝟐 𝒙 𝟑 O/P
Play Study Sleep y
2h 4h 8h 1
*Only one hidden neuron is considered for training example](https://image.slidesharecdn.com/deepneuralnetworkscomputationalgraphs-201110032059/85/Deep-neural-networks-computational-graphs-10-320.jpg)




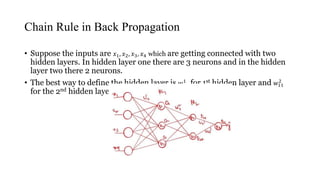

![• Suppose, to find the derivative of w21
3
𝜕L
𝜕𝑤21
3 =
𝜕𝐿
𝜕𝑂31
×
𝜕𝑂31
𝜕𝑤21
3
• To find the derivative of w11
2
•
𝜕L
𝜕𝑤11
2 =
𝜕𝐿
𝜕𝑂31
×
𝜕𝑂31
𝜕𝑂21
×
𝜕𝑂21
𝜕𝑤11
2
• To find 𝑤12
2
because there are 2 output layers are impacting 𝑓21, 𝑓22.
• After finding the derivative adding one more derivative [
𝜕𝐿
𝜕𝑂31
×
𝜕𝑂31
𝜕𝑂21
×
𝜕𝑂21
𝜕𝑤11
2 ] +
[
𝜕𝐿
𝜕𝑂31
×
𝜕𝑂31
𝜕𝑂22
×
𝜕𝑂22
𝜕𝑤12
2 ]
• When this derivative is updated basically weights are getting updated then
𝑦 going to change until we reach global minima.](https://image.slidesharecdn.com/deepneuralnetworkscomputationalgraphs-201110032059/85/Deep-neural-networks-computational-graphs-17-320.jpg)













![[DSC 2016] 系列活動:李宏毅 / 一天搞懂深度學習](https://cdn.slidesharecdn.com/ss_thumbnails/1-160521014039-thumbnail.jpg?width=640&height=640&fit=bounds)
































































