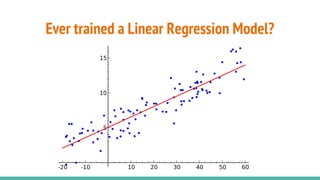
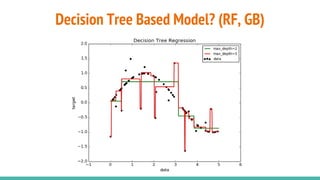
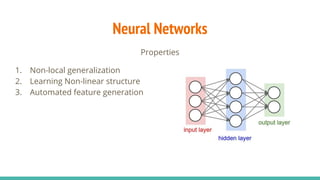
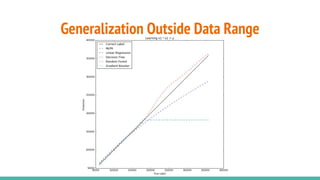
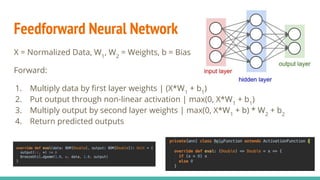
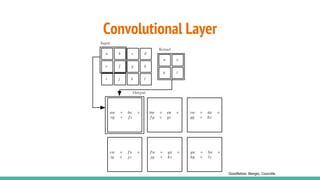
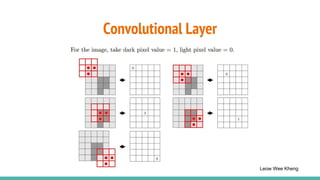
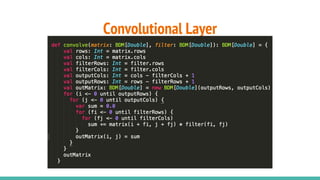
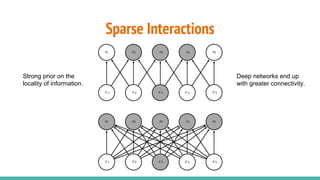
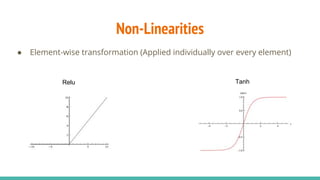
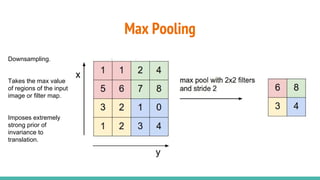
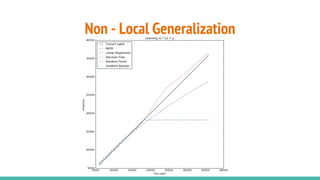
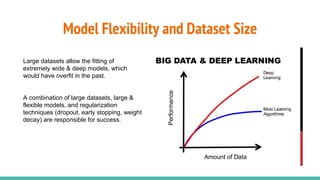
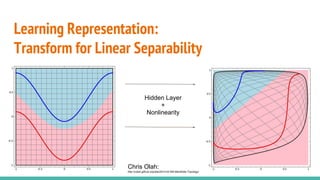
The document provides a comprehensive overview of convolutional neural networks (CNNs), detailing their structure, functionality, and applications in various fields such as computer vision and natural language processing. It discusses key concepts including automated feature engineering, non-local generalization, model optimization, and the advantages of deep learning over traditional algorithms. Additionally, it highlights CNN's state-of-the-art performance in tasks like object recognition, speech recognition, and image segmentation.