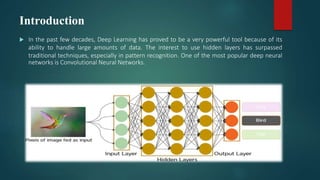
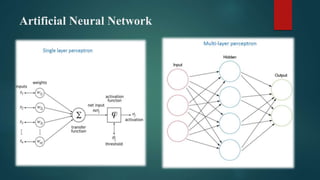
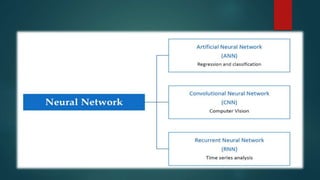
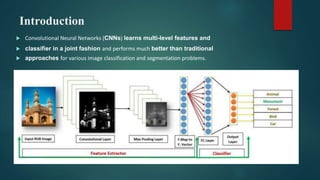
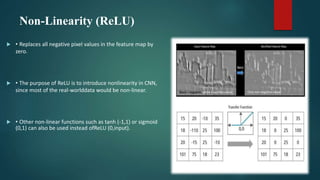
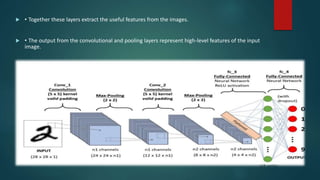
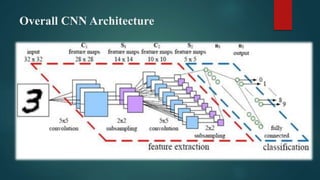
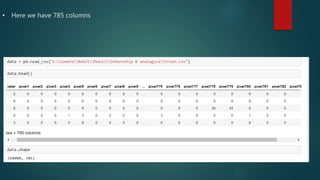
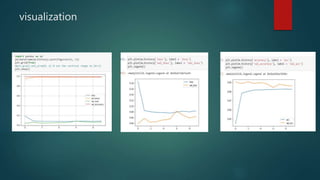
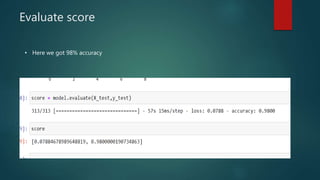
Convolutional neural networks (CNNs) are a type of deep neural network commonly used for analyzing visual imagery. CNNs use various techniques like convolution, ReLU activation, and pooling to extract features from images and reduce dimensionality while retaining important information. CNNs are trained end-to-end using backpropagation to update filter weights and minimize output error. Overall CNN architecture involves an input layer, multiple convolutional and pooling layers to extract features, fully connected layers to classify features, and an output layer. CNNs can be implemented using sequential models in Keras by adding layers, compiling with an optimizer and loss function, fitting on training data over epochs with validation monitoring, and evaluating performance on test data.








![Putting it all together – Training using Backpropagation
• Step 1: We initialize all filters and parameters / weights with random values.
• Step 2: The network takes a training image as input, goes through the forward propagation
step (convolution, ReLU and pooling operations along with forward propagation in the Fully
Connected layer) and finds the output probabilities for each class.
• Let’s say the output probabilities for the boat image above are [0.2, 0.4, 0.1, 0.3].
• Since weights are randomly assigned for the first training example, output probabilities are
also random.
• Step 3: Calculate the total error at the output layer (summation over all 4 classes).](https://image.slidesharecdn.com/cnnppt-220807043225-18ea4c3c/85/cnn-ppt-pptx-16-320.jpg)
![ Step 4: Use Backpropagation to calculate the gradients of the error with respect to all weights
in the network and use gradient descent to update all filter values/ weights and parameter
values to minimize the output error.
• The weights are adjusted in proportion to their contribution to the total error.
• When the same image is input again, output probabilities might now be [0.1, 0.1, 0.7, 0.1],
which is closer to the target vector [0, 0, 1, 0].
• This means that the network has learnt to classify this particular image correctly by adjusting its
weights / filters such that the output error is reduced.
• Parameters like number of filters, filter sizes, architecture of the network etc. have all been fixed
before Step 1 and do not change during training process – only the values of the filter matrix and
connection weights get updated.
• Step 5: Repeat steps 2-4 with all images in the training set](https://image.slidesharecdn.com/cnnppt-220807043225-18ea4c3c/85/cnn-ppt-pptx-17-320.jpg)


















































![[Revised] Intro to CNN](https://cdn.slidesharecdn.com/ss_thumbnails/googletechsprinttalkcnnintro-200730141604-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Dubravko Culibrk - Deep Learning for Mammography.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/yiscimuktacgqoiu4dkp-deep-learning-for-mammography-260119121559-aad59182-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Gordana Milutinovic Dumbelovic - From Insight to Oversight: A...](https://cdn.slidesharecdn.com/ss_thumbnails/t7dkjsfxqwwzceropjv4-gordana-milutinovicdumbelovic-from-insight-to-oversight-ai-driven-power-bi-moni-260119121559-9e0bf11b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Harshvardhan Jain - From Pre-Trained to Purpose-Built: Fine-T...](https://cdn.slidesharecdn.com/ss_thumbnails/zru4zmiseku5tgvu2dgw-harshvardhan-jain-from-pre-trained-to-purpose-built-fine-tuning-llms-for-high-i-260119101520-8335585f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marcos Heidemann - Beyond the Hype: Making AI Coding Assistan...](https://cdn.slidesharecdn.com/ss_thumbnails/eexkhvldrjsopspdjbur-marcos-heidemann-beyond-the-hype-getting-real-value-out-of-ai-assisted-coding-260121115910-7e9d41ec-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Egor Krasheninnikov - The Control Stack: Building Guardrails ...](https://cdn.slidesharecdn.com/ss_thumbnails/3lzcz7hxqmo51mtalv4u-the-control-stack-260119101520-ea90841a-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Tamas Srancsik - How To Teach Your AI Football? An Argument f...](https://cdn.slidesharecdn.com/ss_thumbnails/bcjh1m9xtbosv20ucftb-tamas-srancsik-how-to-teach-your-ai-football-260121115910-08b53e9e-thumbnail.jpg?width=640&height=640&fit=bounds)