Downloaded 183 times







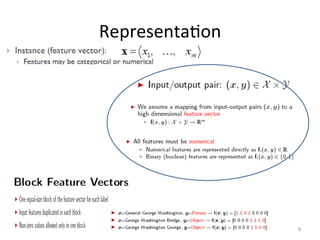






























This document discusses the perceptron algorithm for linear classification. It begins by introducing feature representations and linear classifiers. It then describes the perceptron algorithm, which attempts to learn a weight vector that separates the training data into classes with some margin. The document proves that for any separable training set, the perceptron will converge after a finite number of mistakes, where the number depends on the margin size and properties of the data. However, it notes that while the perceptron finds weights perfectly classifying the training data, these weights may not generalize well to new examples.























































































