Download as PDF, PPTX
















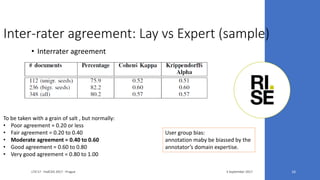



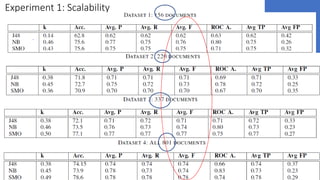
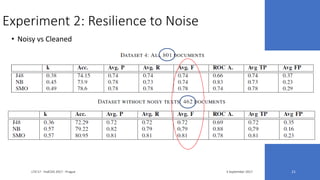





The document discusses the ecare@home project which aims to create a web corpus for ehealth applications by collecting lay-specialized annotations. It presents the methodology for constructing the ecare Swedish web corpus, including challenges related to scalability and noise in the data. Two experiments are detailed that validate the project’s claims about the corpus's extensibility and performance resilience despite data noise.





















































