Downloaded 19 times










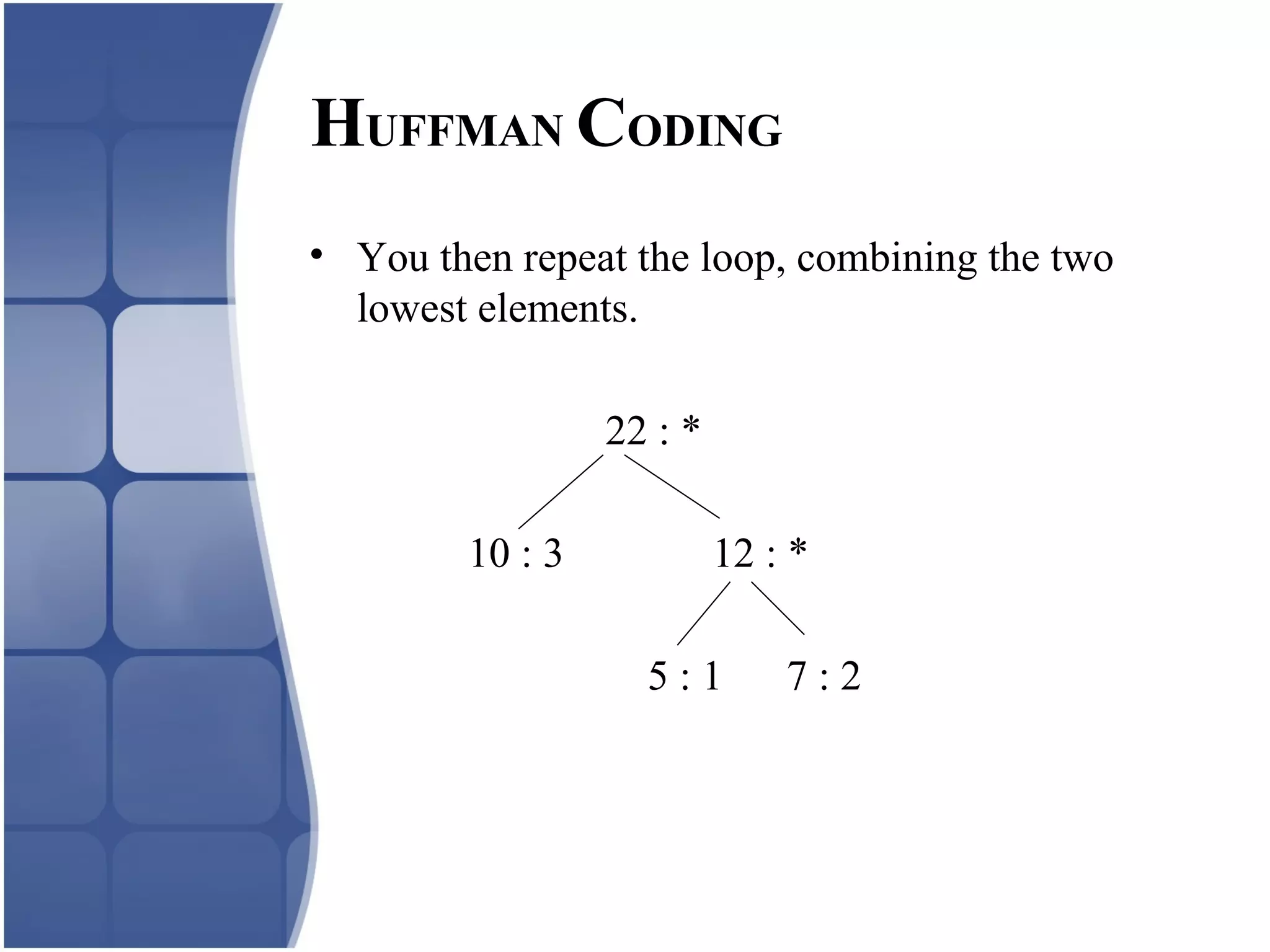

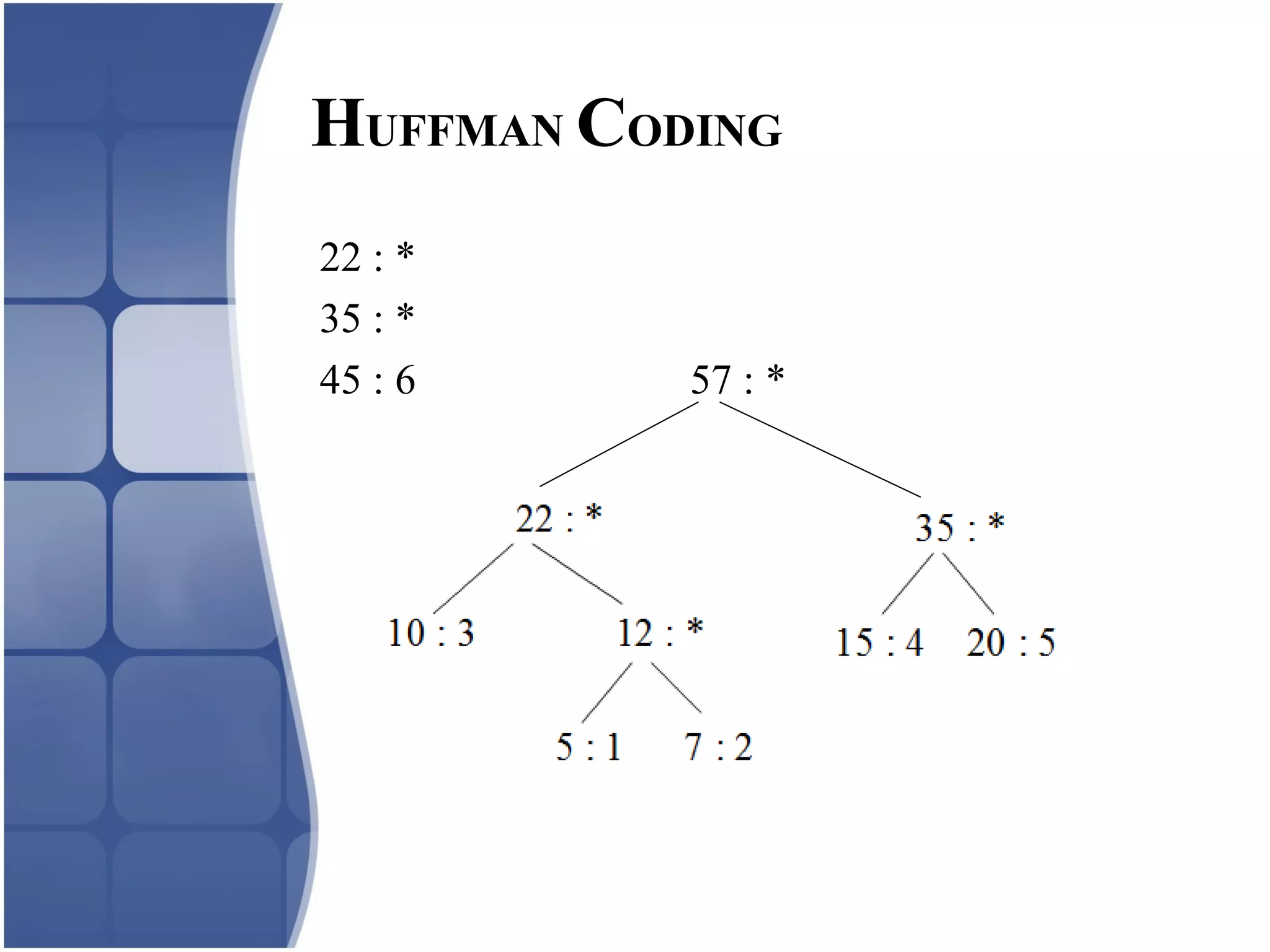
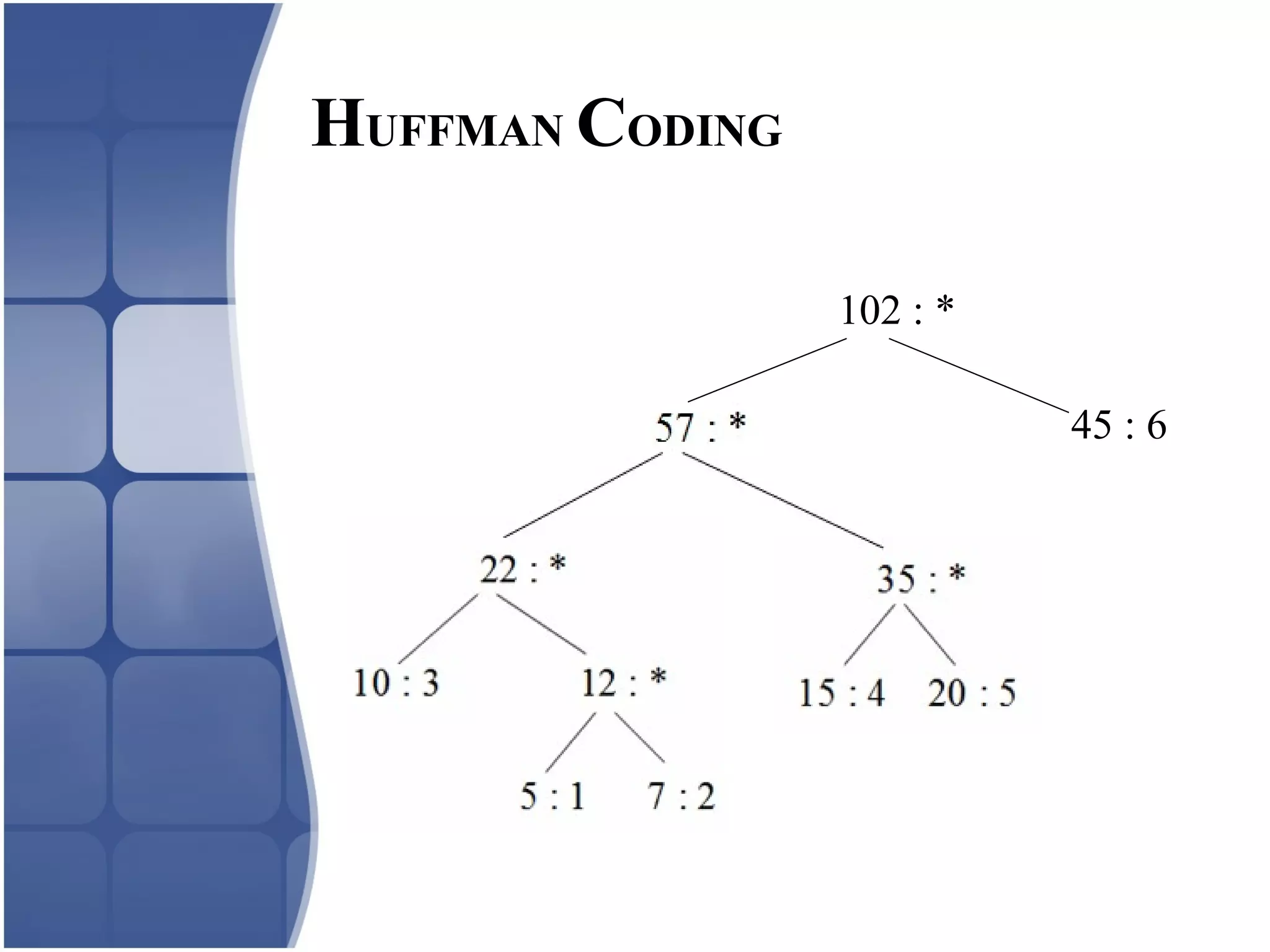
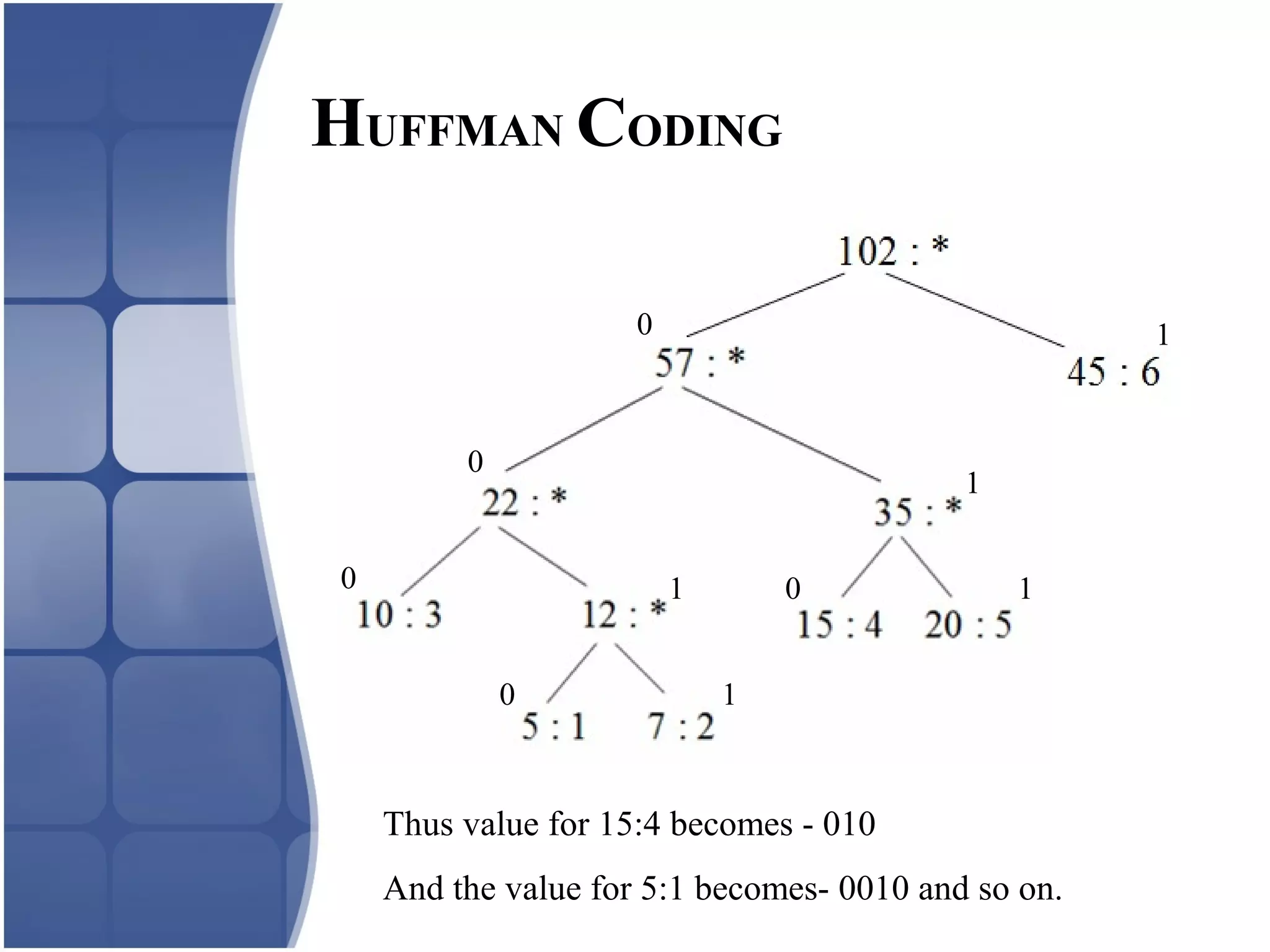


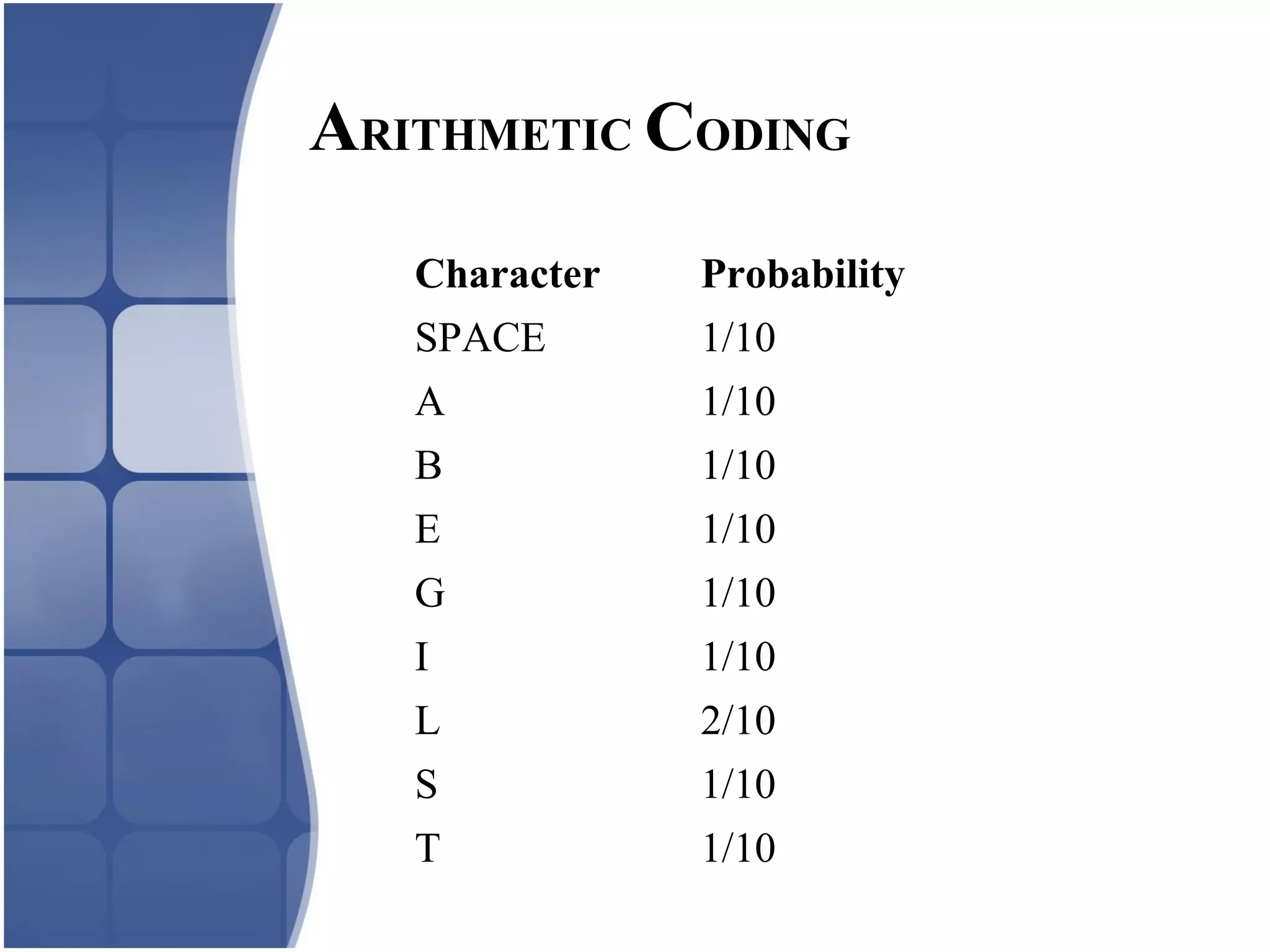

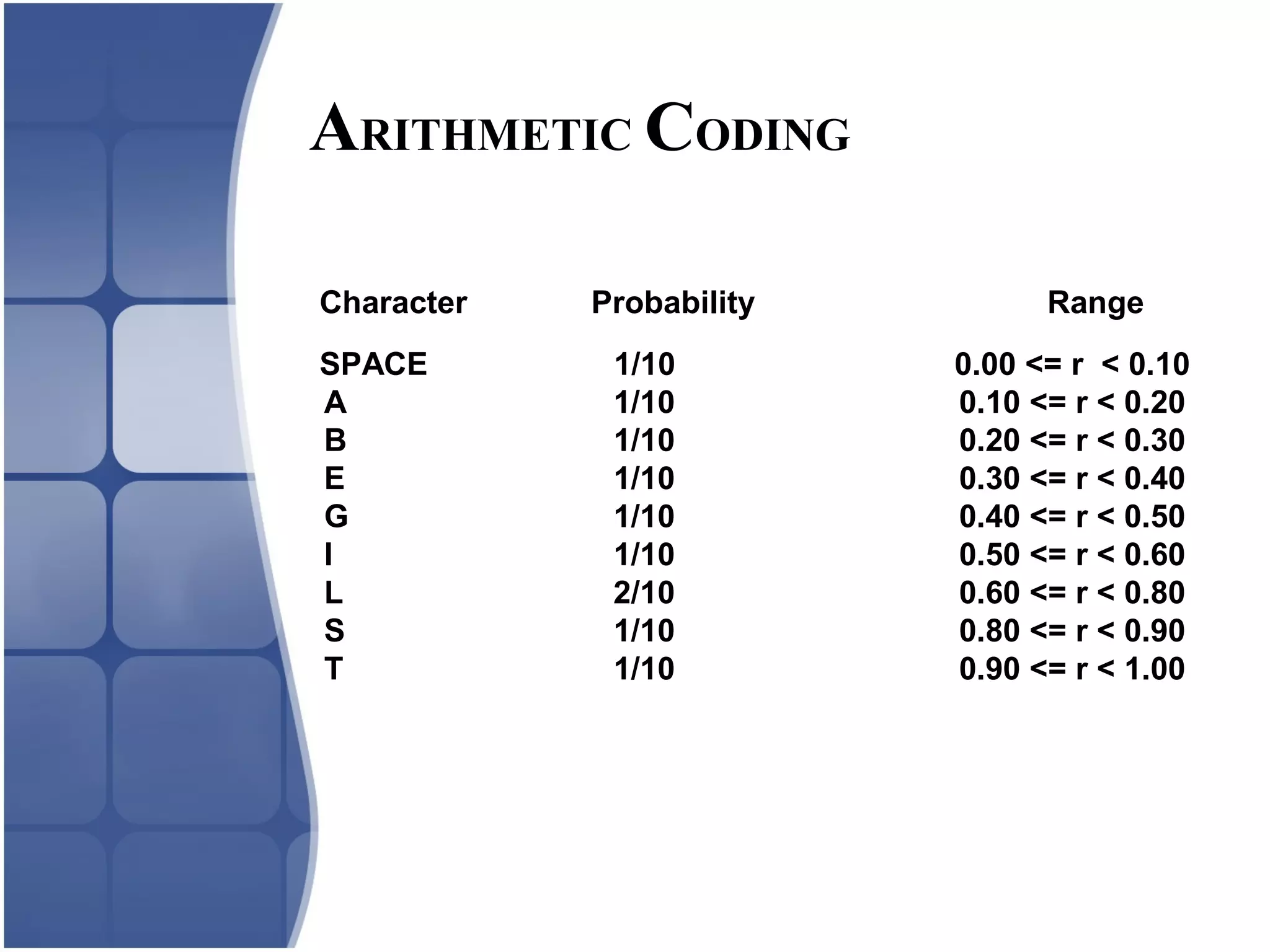




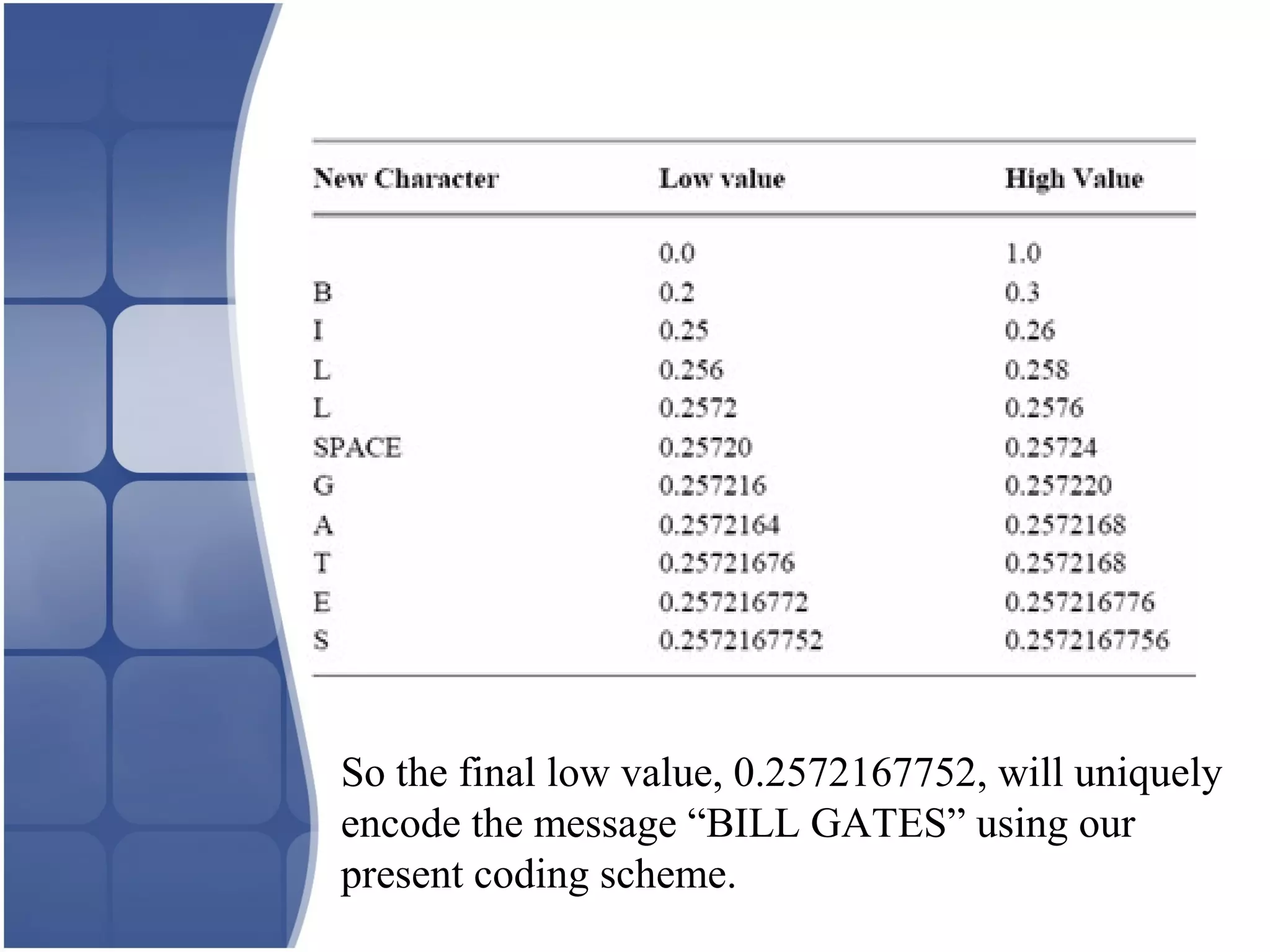





Run length encoding is a data compression technique that works by reducing the size of repeating strings of characters. It encodes repeating strings, called runs, into two bytes - the first for the run count and the second for the run value. While it achieves low compression ratios, it is easy to implement and execute quickly. Run length encoding works best on data with many repeating runs, like icons and line drawings. Huffman coding creates an optimal variable length code by building a binary tree from the frequency of symbols in the data. It assigns shorter codes to more frequent symbols. The tree is constructed by combining the two lowest frequency nodes until only one node remains. Arithmetic coding encodes a stream of symbols into a single number between 0 and