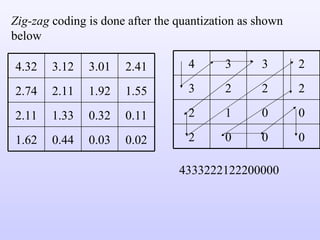
The document discusses various techniques for image compression including:
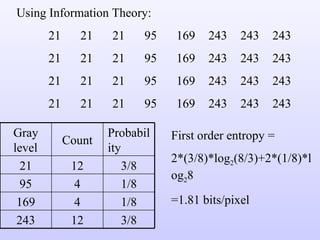
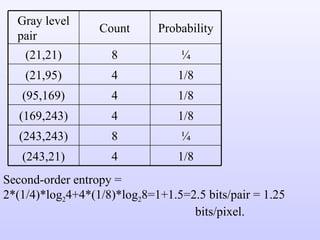
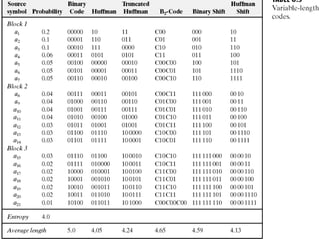
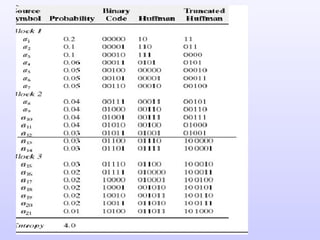
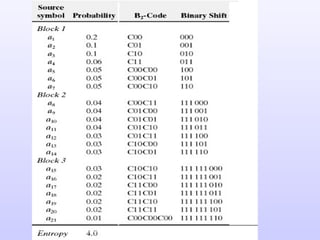
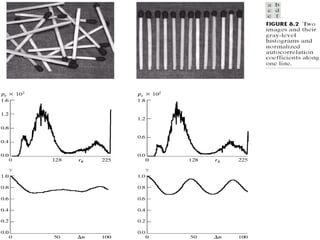
1) Variable length coding which reduces the first order entropy but not the second order entropy due to inter-pixel redundancy.
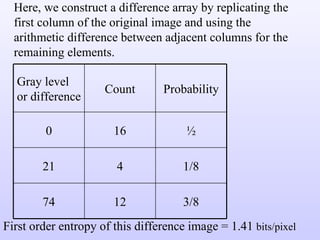
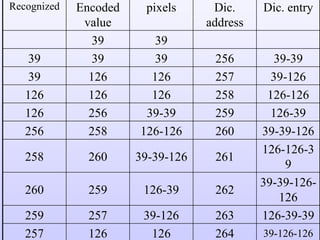
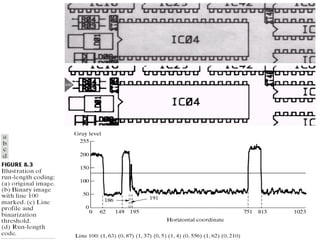
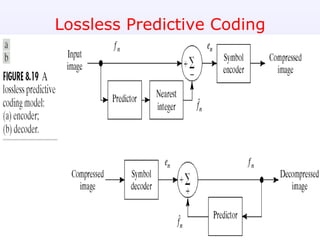
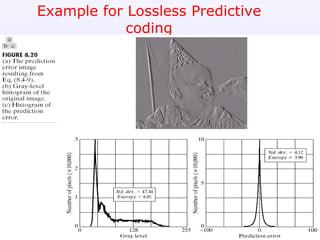
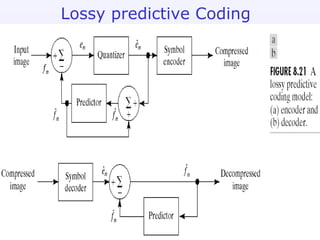
2) Predictive coding which codes only the difference between actual and predicted pixel values to remove inter-pixel redundancy.
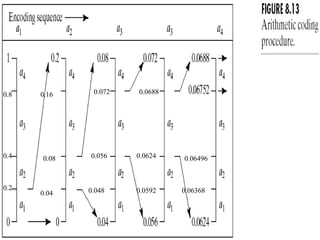
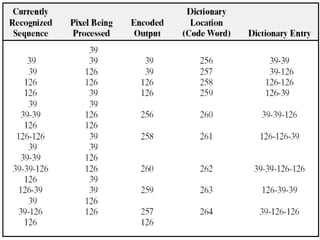
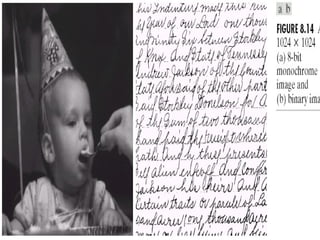
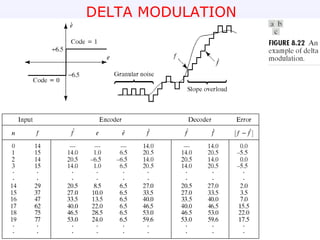
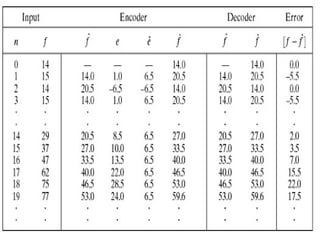
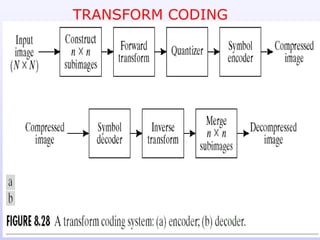
3) Lossy compression techniques like transform coding and delta modulation which allow for higher compression ratios than lossless techniques by introducing some loss of information.