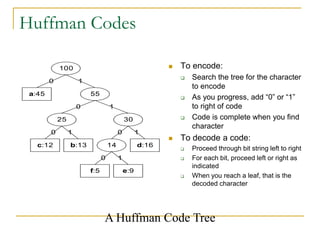
Huffman codes are a technique for lossless data compression that assigns variable-length binary codes to characters, with more frequent characters having shorter codes. The algorithm builds a frequency table of characters then constructs a binary tree to determine optimal codes. Characters are assigned codes based on their path from the root, with left branches representing 0 and right 1. Both encoder and decoder use this tree to translate between binary codes and characters. The tree guarantees unique decoding and optimal compression.