Downloaded 487 times








![Gabriele Monfardini - Corso di Basi di Dati Multimediali a.a. 2005-20068
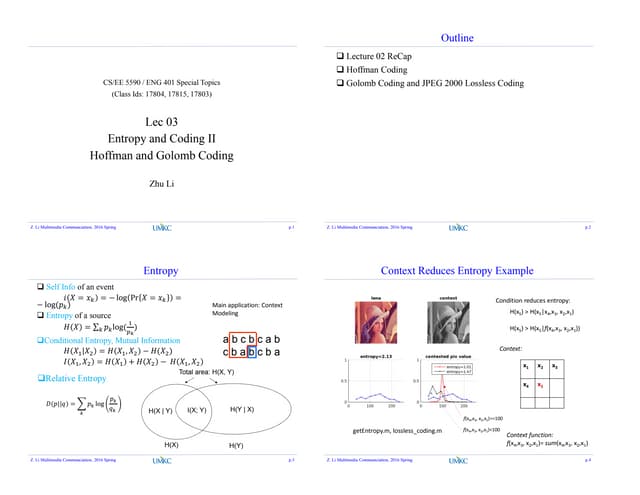
An example - II
The range between low and high is divided
between the symbols of the alphabet,
according to their probabilities
low
high
0
1
0.333
3
0.666
7
a
b
c(P[c]=1/3)
(P[b]=1/3)
(P[a]=1/3)](https://image.slidesharecdn.com/arithmeticcoding-140313090905-phpapp02/85/Arithmetic-coding-8-320.jpg)
![9
An example - III
low
high
0
1
0.333
3
0.666
7
a
b
c
b
low = 0.3333
high = 0.6667
P[a]=1/4
P[b]=2/4
P[c]=1/4
new probabilities](https://image.slidesharecdn.com/arithmeticcoding-140313090905-phpapp02/85/Arithmetic-coding-9-320.jpg)
![Gabriele Monfardini - Corso di Basi di Dati Multimediali a.a. 2005-200610
An example - IV
new probabilities
P[a]=1/5
P[b]=2/5
P[c]=2/5
low
high
0.333
3
0.666
7
0.416
7
0.583
4
a
b
c
c
low = 0.5834
high = 0.6667
(P[c]=1/4)
(P[b]=2/4)
(P[a]=1/4)](https://image.slidesharecdn.com/arithmeticcoding-140313090905-phpapp02/85/Arithmetic-coding-10-320.jpg)
![Gabriele Monfardini - Corso di Basi di Dati Multimediali a.a. 2005-200611
An example - V
new probabilities
P[a]=1/6
P[b]=2/6
P[c]=3/6
low
high
0.583
4
0.666
7
0.600
1
0.633
4
a
b
c
c
low = 0.6334
high = 0.6667
(P[c]=2/5)
(P[b]=2/5)
(P[a]=1/5)](https://image.slidesharecdn.com/arithmeticcoding-140313090905-phpapp02/85/Arithmetic-coding-11-320.jpg)
![Gabriele Monfardini - Corso di Basi di Dati Multimediali a.a. 2005-200612
An example - VI
Final interval
[0.6390,0.6501)
we can send 0.64
low
high
0.633
4
0.666
7
0.639
0
0.650
1
a
b
c
low = 0.6390
high = 0.6501
b
(P[c]=3/6)
(P[b]=2/6)
(P[a]=1/6)](https://image.slidesharecdn.com/arithmeticcoding-140313090905-phpapp02/85/Arithmetic-coding-12-320.jpg)



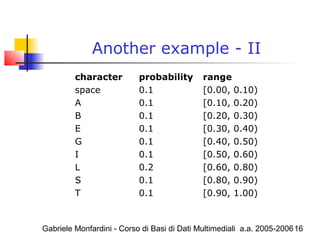





![Gabriele Monfardini - Corso di Basi di Dati Multimediali a.a. 2005-200622
Why does it works?
The size of the final interval is the product of
the probabilities of the symbols coded, so the
logarithm of this product is the sum of the
logarithm of each term
So a symbol s with probability Pr[s]
contributes
bits to the output, that is equal to symbol
probability content (uncertainty)!!
log Pr[ ]s−](https://image.slidesharecdn.com/arithmeticcoding-140313090905-phpapp02/85/Arithmetic-coding-22-320.jpg)



![Gabriele Monfardini - Corso di Basi di Dati Multimediali a.a. 2005-200626
The encoding step
To code symbol s, where symbols are
numbered from 1 to n and symbol i has
probability Pr[i]
low_bound =
high_bound =
range = high - low
low = low + range * low_bound
high = low + range * high_bound
1
1
Pr[ ]
s
i
i
−
=∑
1
Pr[ ]
s
i
i=∑](https://image.slidesharecdn.com/arithmeticcoding-140313090905-phpapp02/85/Arithmetic-coding-26-320.jpg)
![Gabriele Monfardini - Corso di Basi di Dati Multimediali a.a. 2005-200627
The decoding step
The symbols are numbered from 1 to n and
value is the arithmetic code to be processed
Find s such that
Return symbol s
Perform the same range-narrowing step of the encoding step
1
1 1
( )
Pr[ ] Pr[ ]
( )
s s
i i
value low
i i
high low
−
= =
−
≤ ≤
−
∑ ∑](https://image.slidesharecdn.com/arithmeticcoding-140313090905-phpapp02/85/Arithmetic-coding-27-320.jpg)




Arithmetic coding is a lossless data compression technique that encodes data as a single real number between 0 and 1. It maps a string of symbols to a fractional number, with more probable symbols represented by larger fractional ranges. Encoding involves repeatedly dividing the interval based on symbol probabilities, and the final encoded number represents the entire string. Decoding reconstructs the string by comparing the number to symbol probability ranges. Arithmetic coding achieves compression closer to the entropy limit than Huffman coding by spreading coding inefficiencies across all symbols of the data.