Downloaded 50 times


























Dustin Vannoy presented on using Delta Lake with Azure Databricks. He began with an introduction to Spark and Databricks, demonstrating how to set up a workspace. He then discussed limitations of Spark including lack of ACID compliance and small file problems. Delta Lake addresses these issues with transaction logs for ACID transactions, schema enforcement, automatic file compaction, and performance optimizations like time travel. The presentation included demos of Delta Lake capabilities like schema validation, merging, and querying past versions of data.
Overview of Dustin Vannoy's roles and expertise in Data Engineering with technologies like Azure, Spark, and Kafka.
An outline of the topics covered in the presentation, including Spark, Delta Lake features, and practical demonstrations.
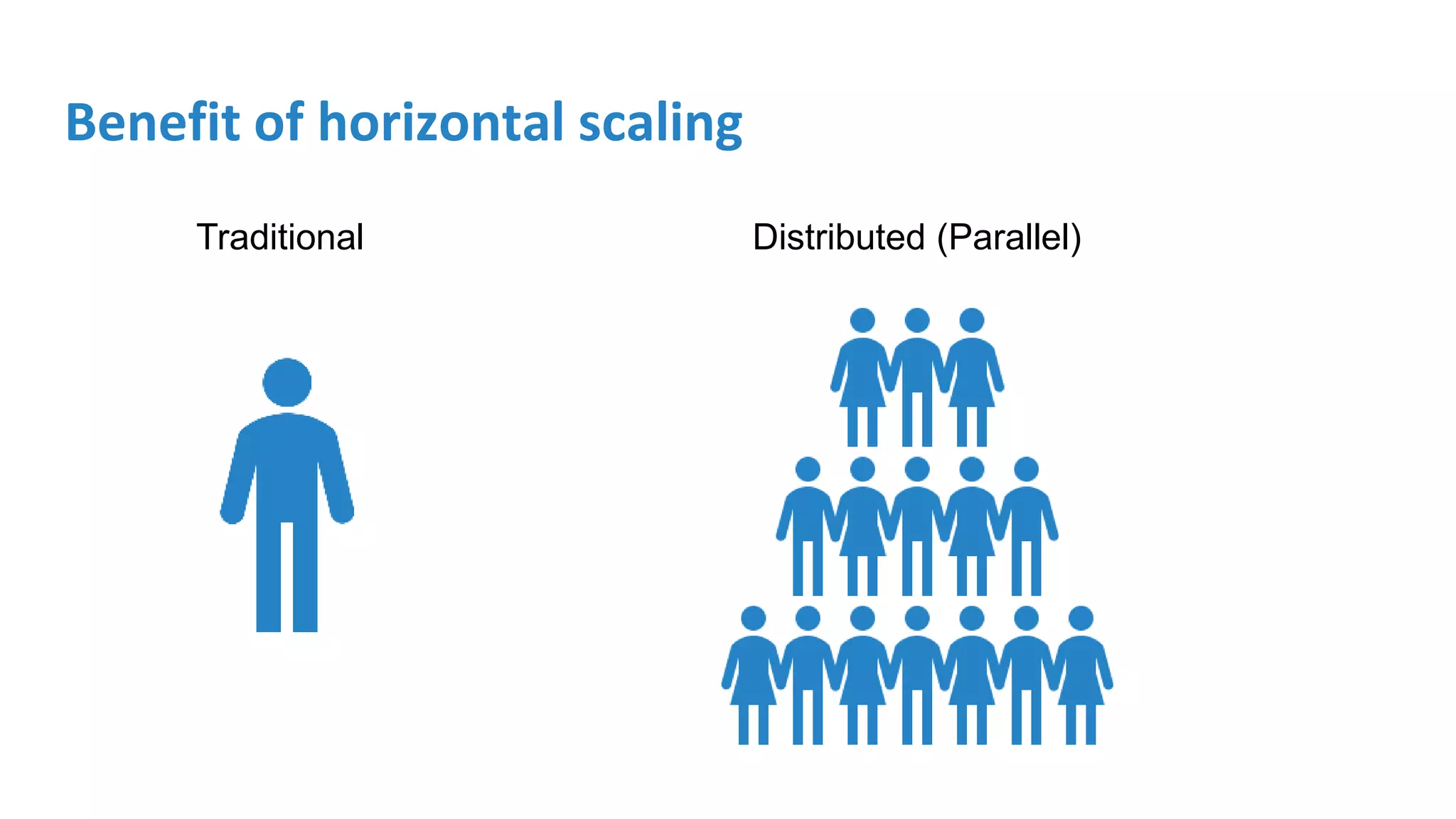
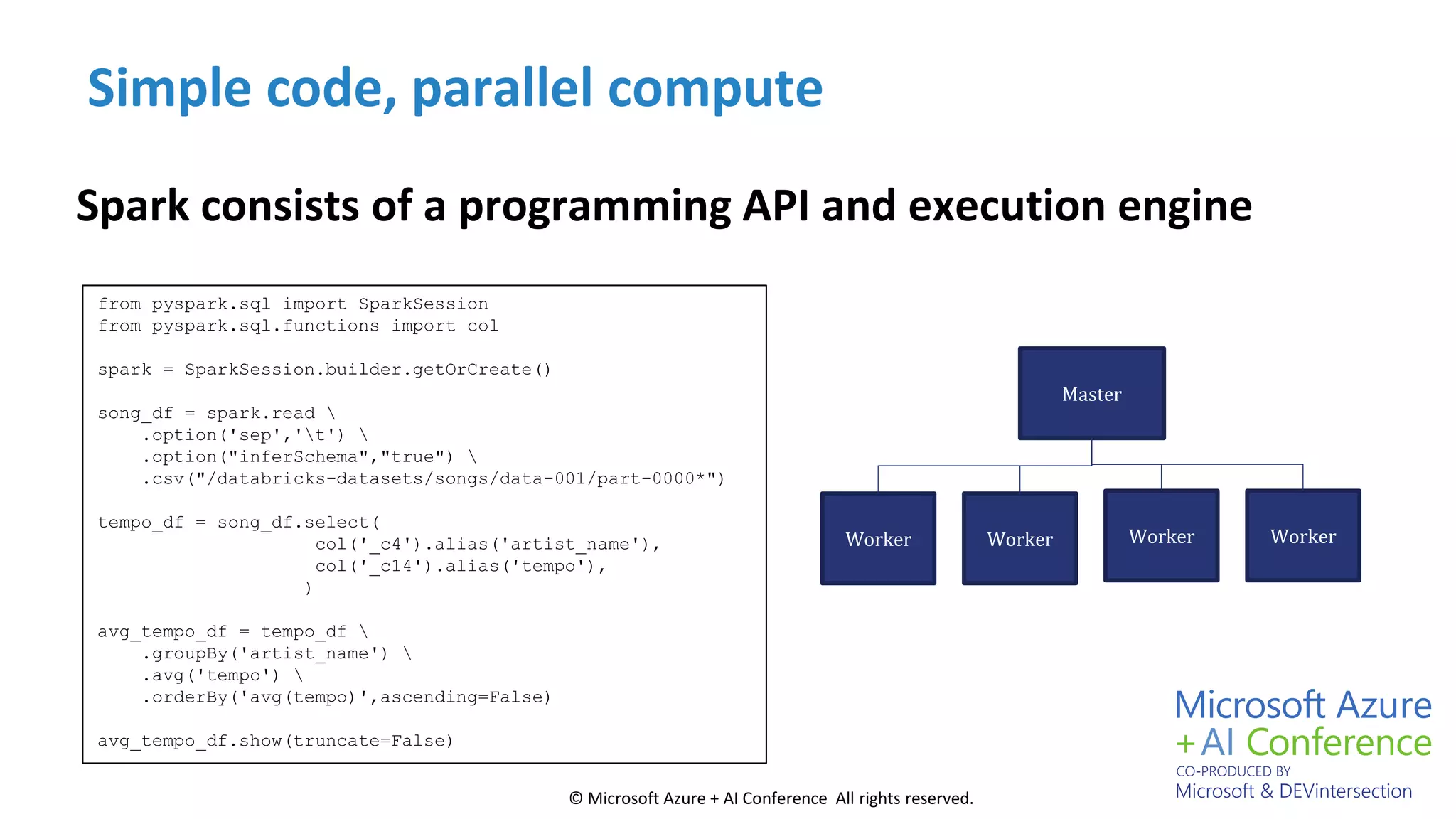
Discusses Spark's scalable data processing capabilities and its advantages over traditional MapReduce.
Details on Spark’s strengths, its programming options, advantages in data analytics, and simple coding within Spark.
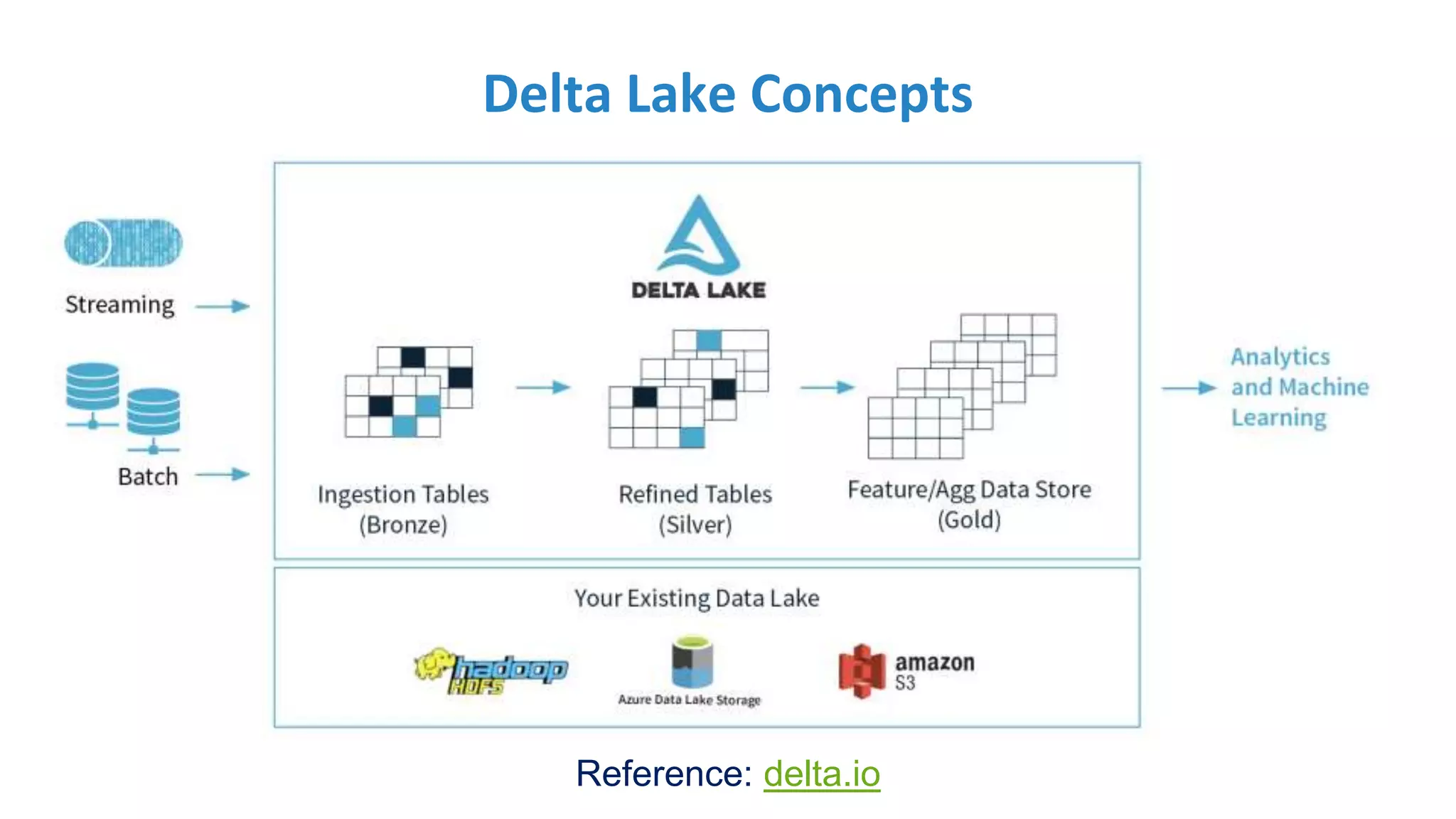
Introduction to Delta Lake, discussing its advantages in improving data integrity and addressing Spark limitations.
Explains ACID properties crucial for data handling and how Delta Lake ensures these properties during operations.
Insights into schema enforcement, time travel, and other Delta Lake features that enhance data management and performance.
Final reflections on Delta Lake capabilities and resources for further learning.

![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)





















































![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)






