Downloaded 82 times









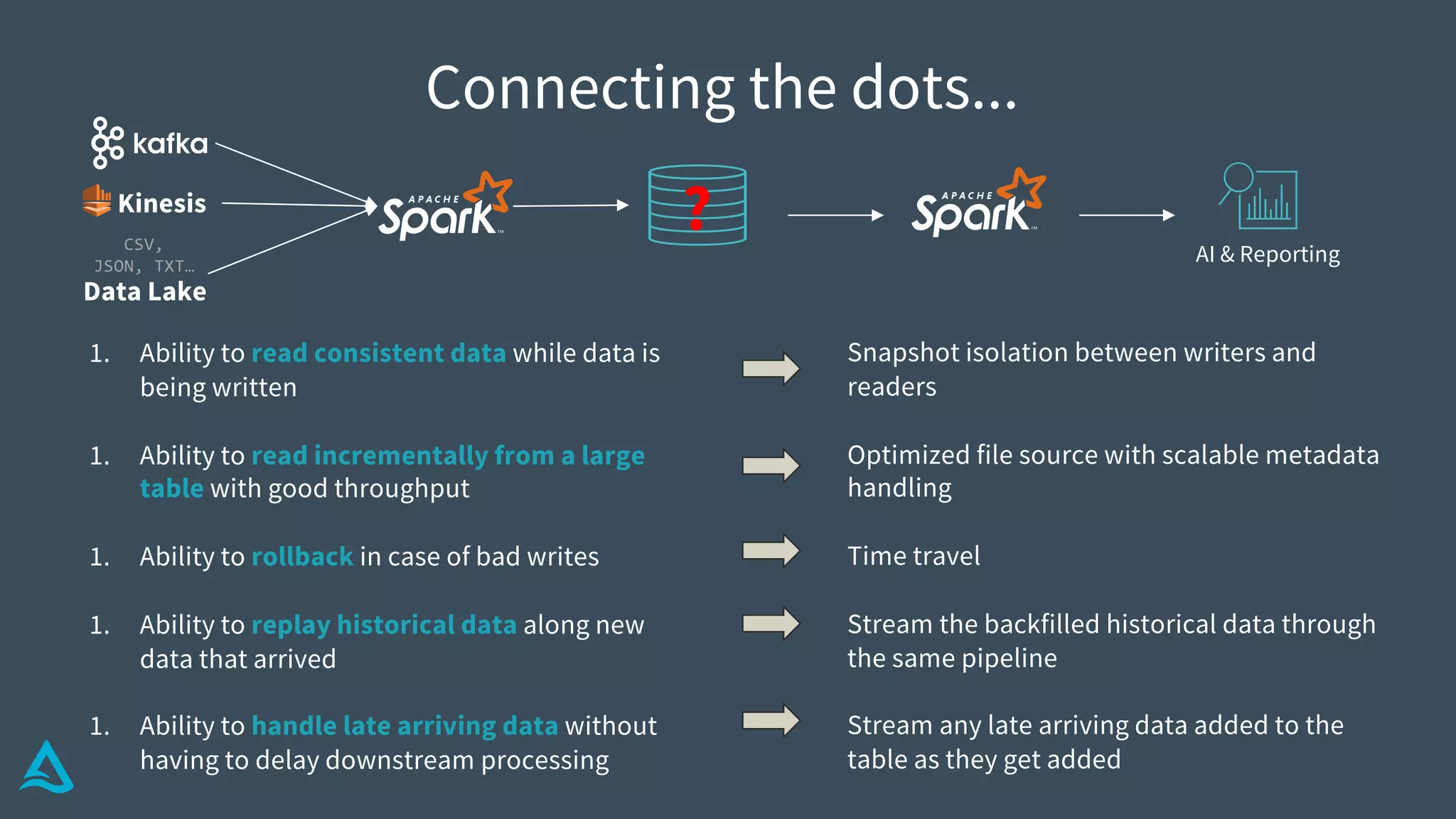


This document describes the Delta architecture, which unifies batch and streaming data processing. Delta achieves this through a continuous data flow model using structured streaming. It allows data engineers to read consistent data while being written, incrementally read large tables at scale, rollback in case of errors, replay and process historical data along with new data, and handle late arriving data without delays. Delta uses transaction logging, optimistic concurrency, and Spark to scale metadata handling for large tables. This provides a simplified solution to common challenges data engineers face.
Presentation by Palla Lentz and Jake Therianos introduces Delta by example.
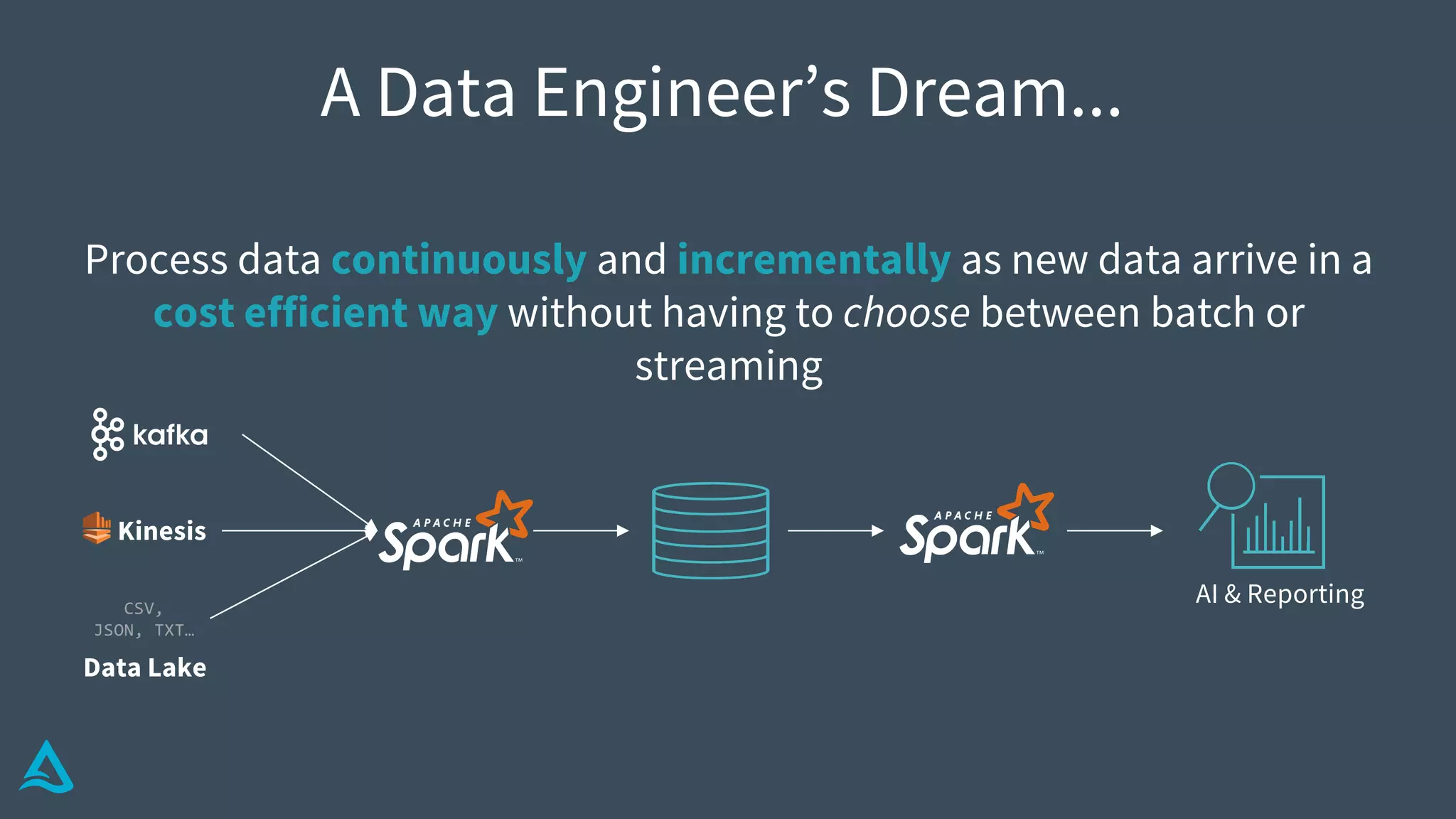
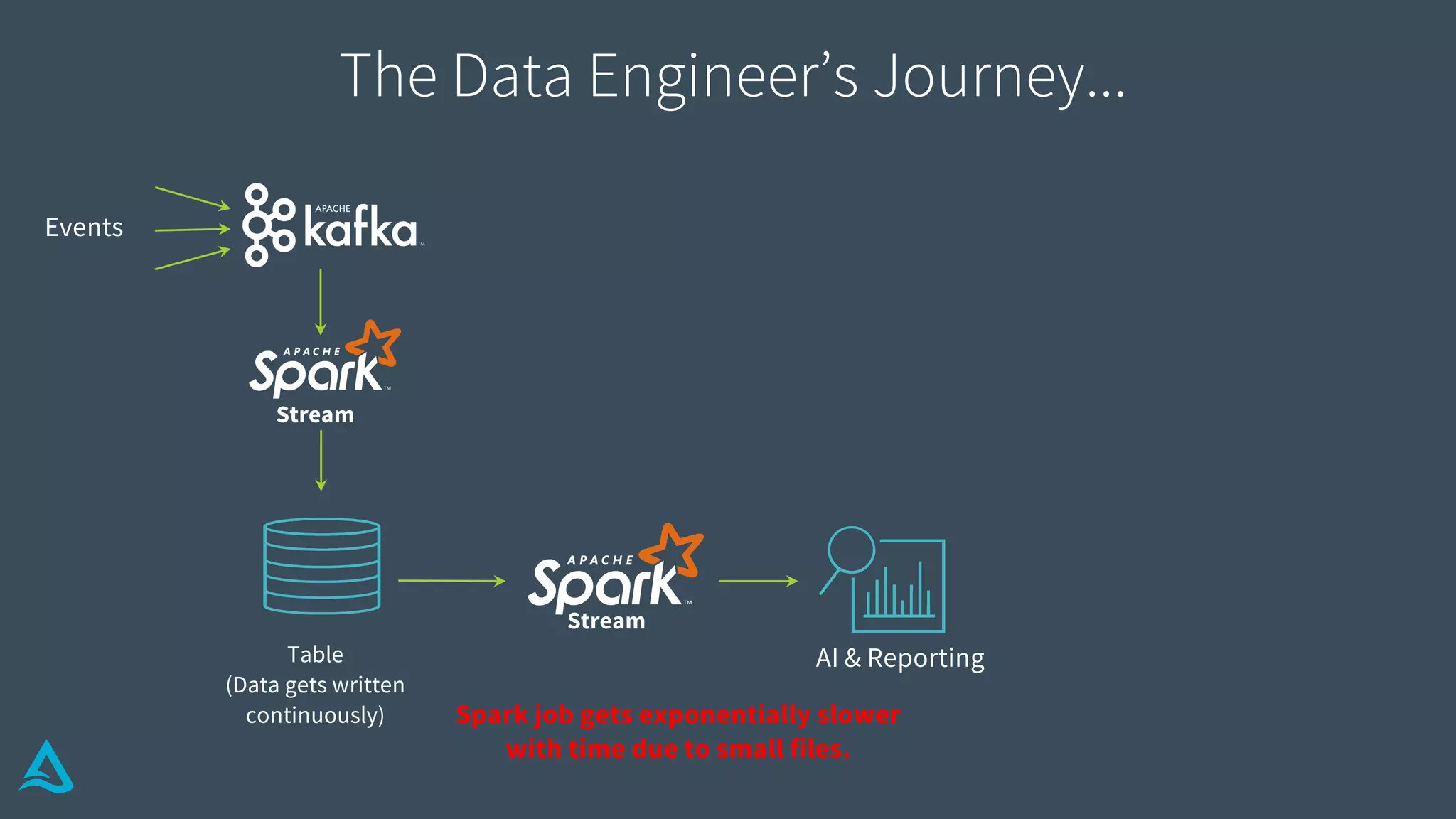
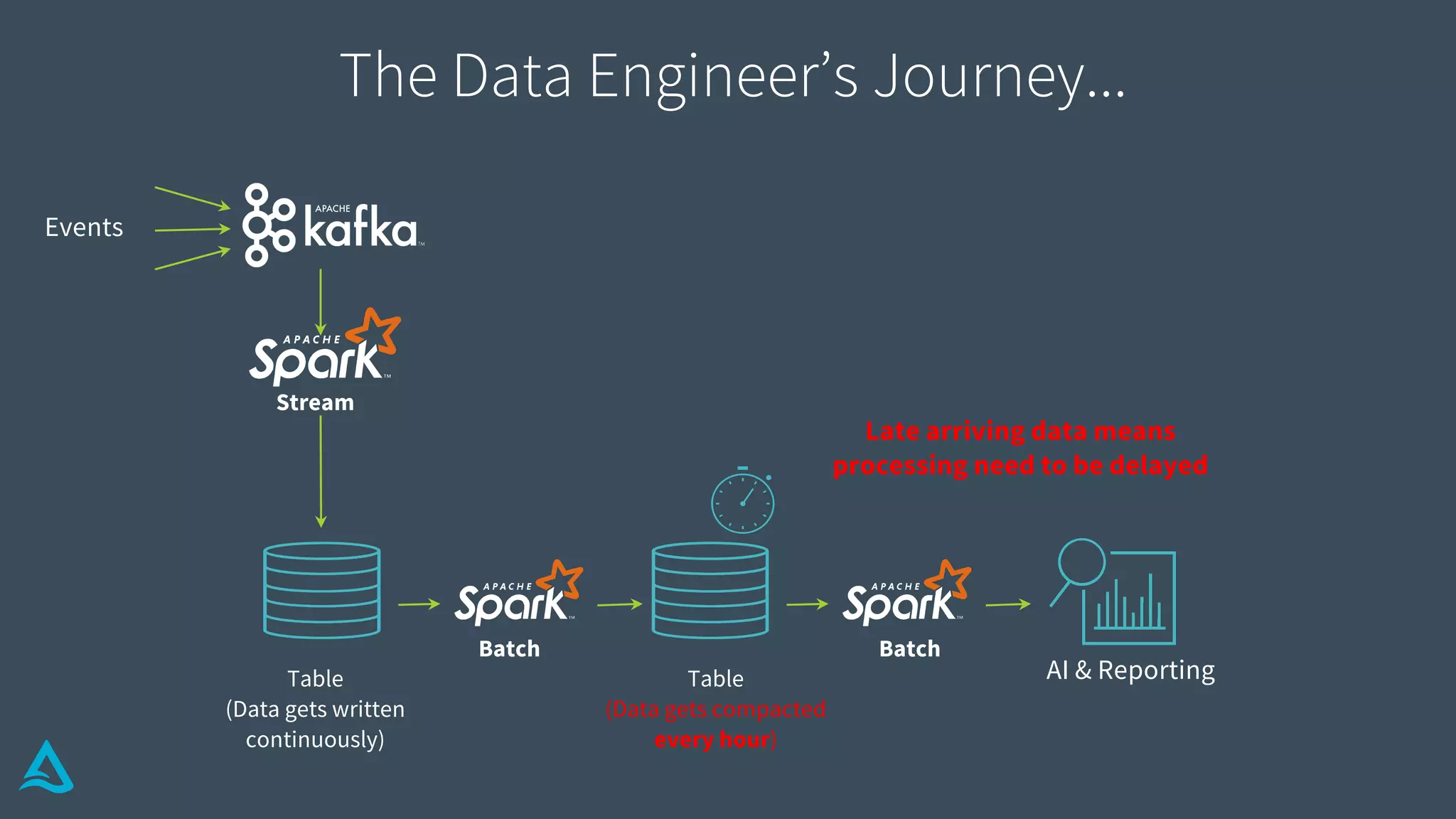
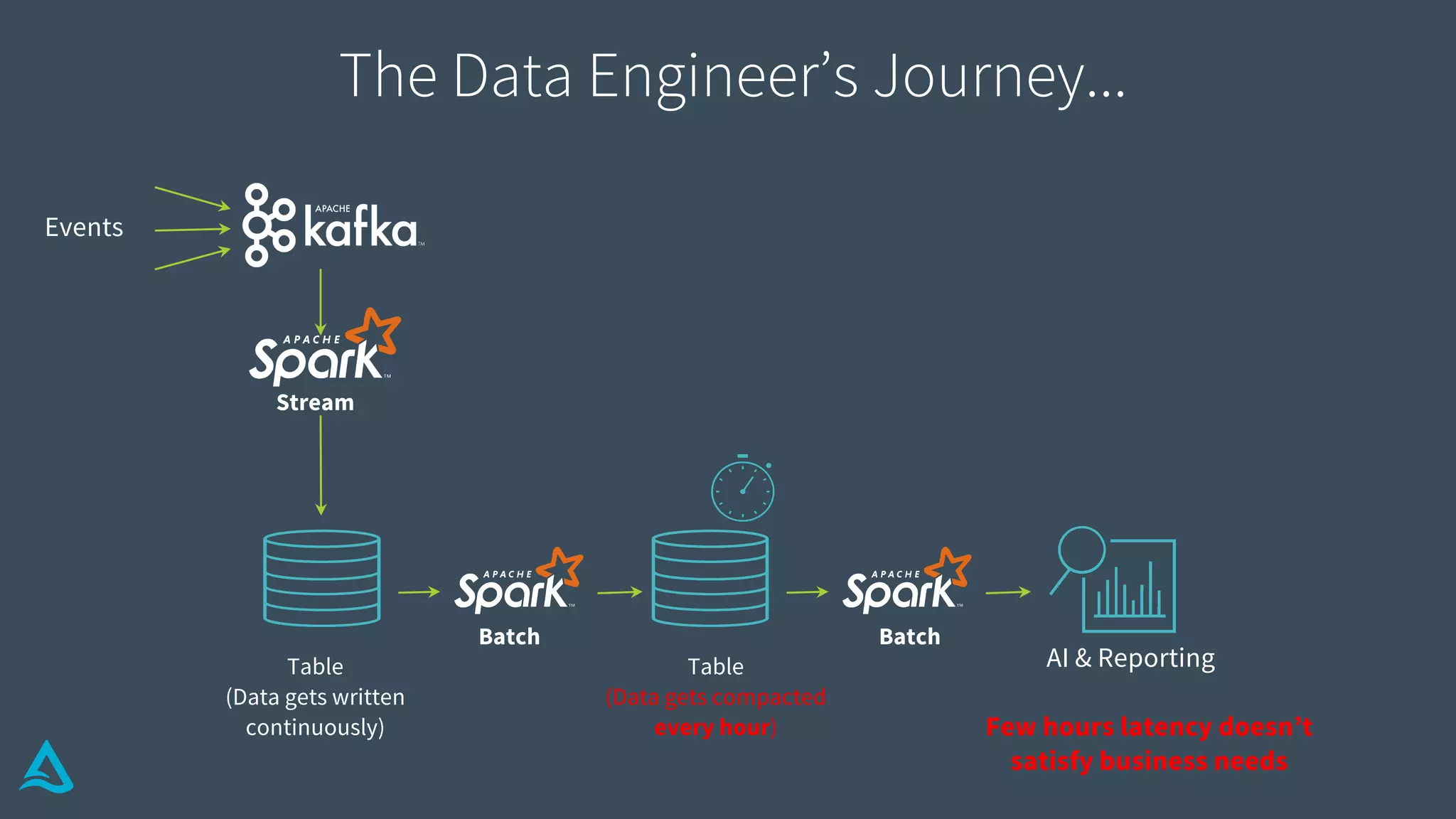
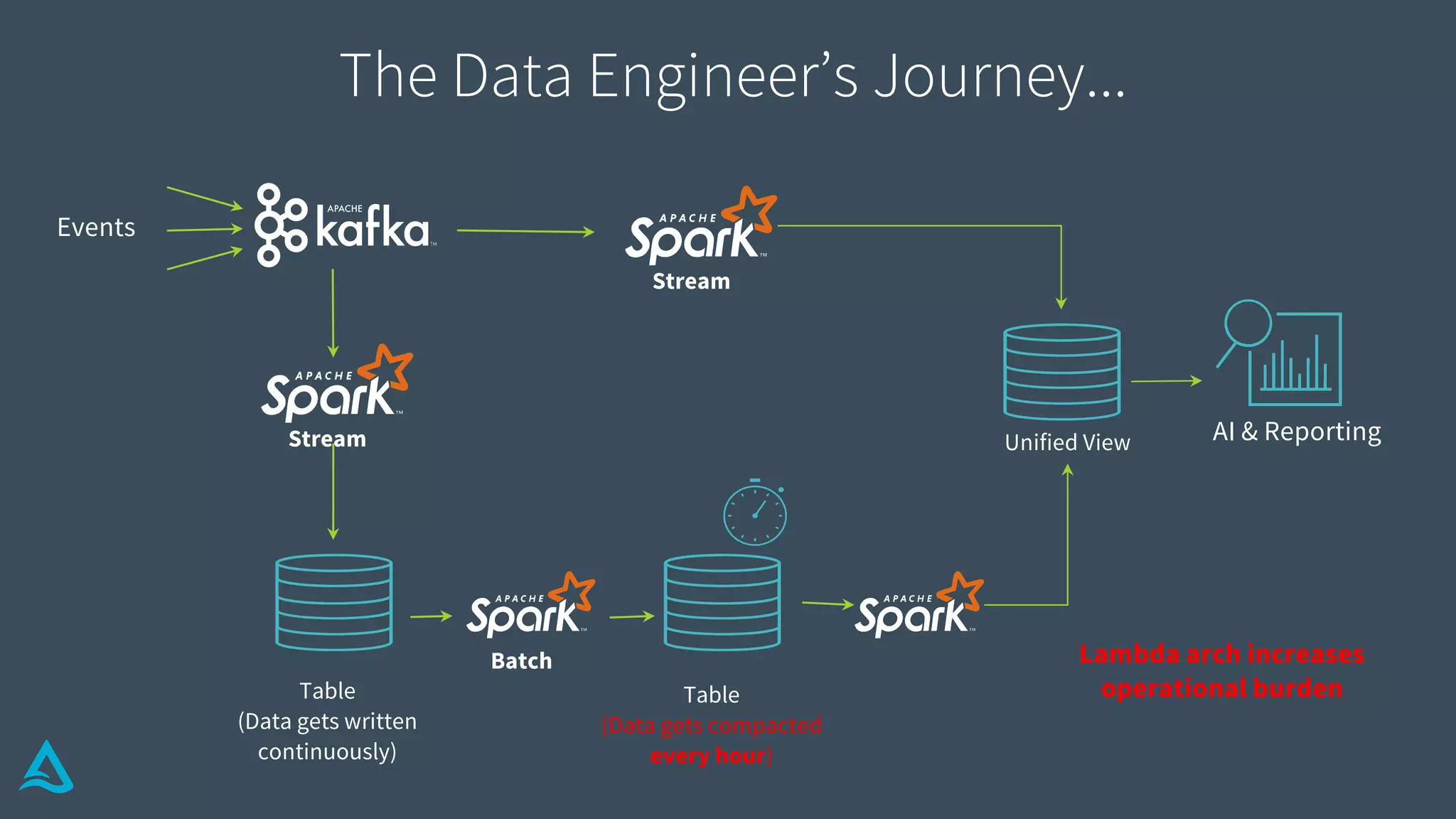
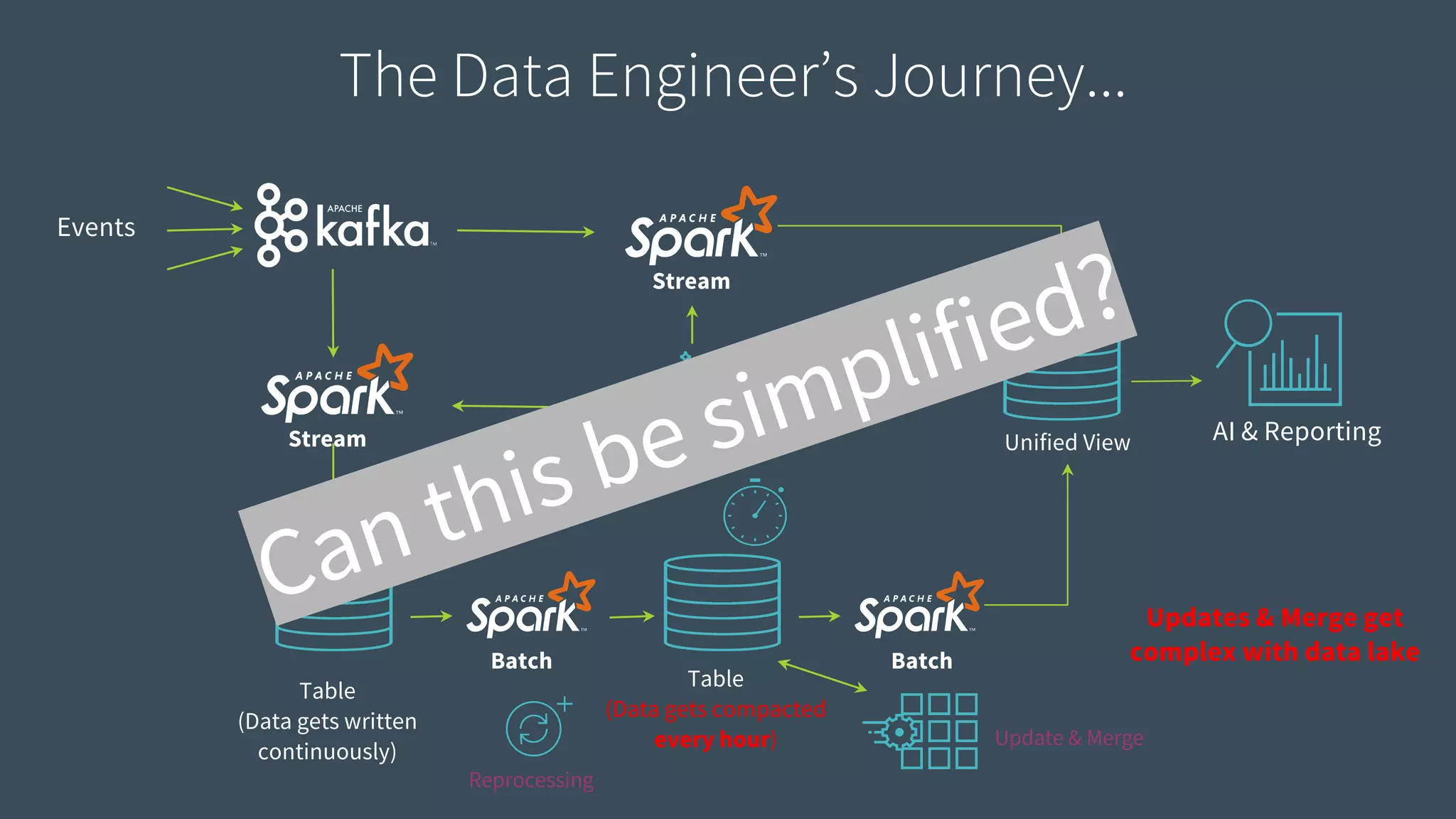
Discusses the complexities of data engineering, focusing on continuous data processing and issues with batch vs stream.
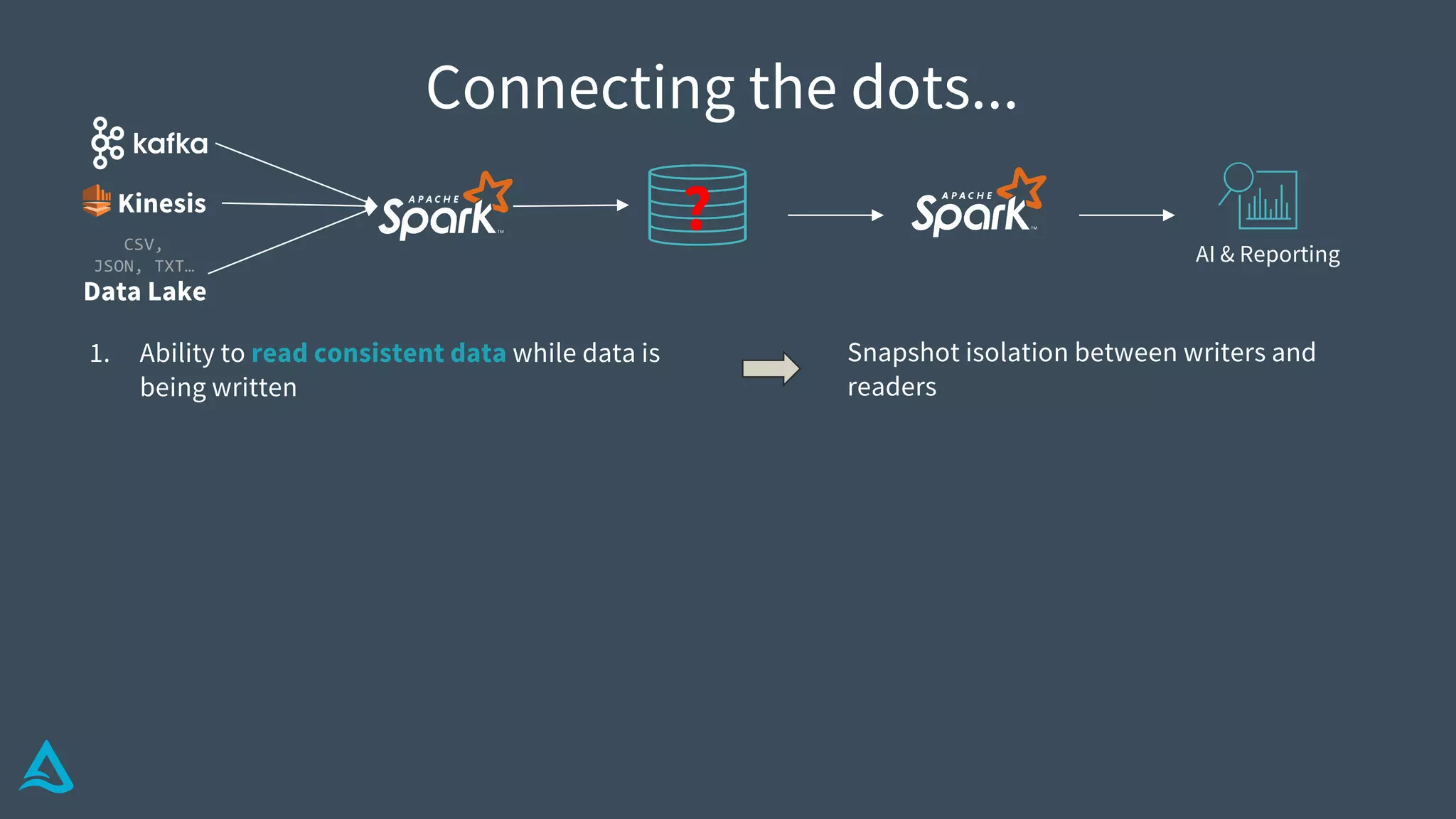
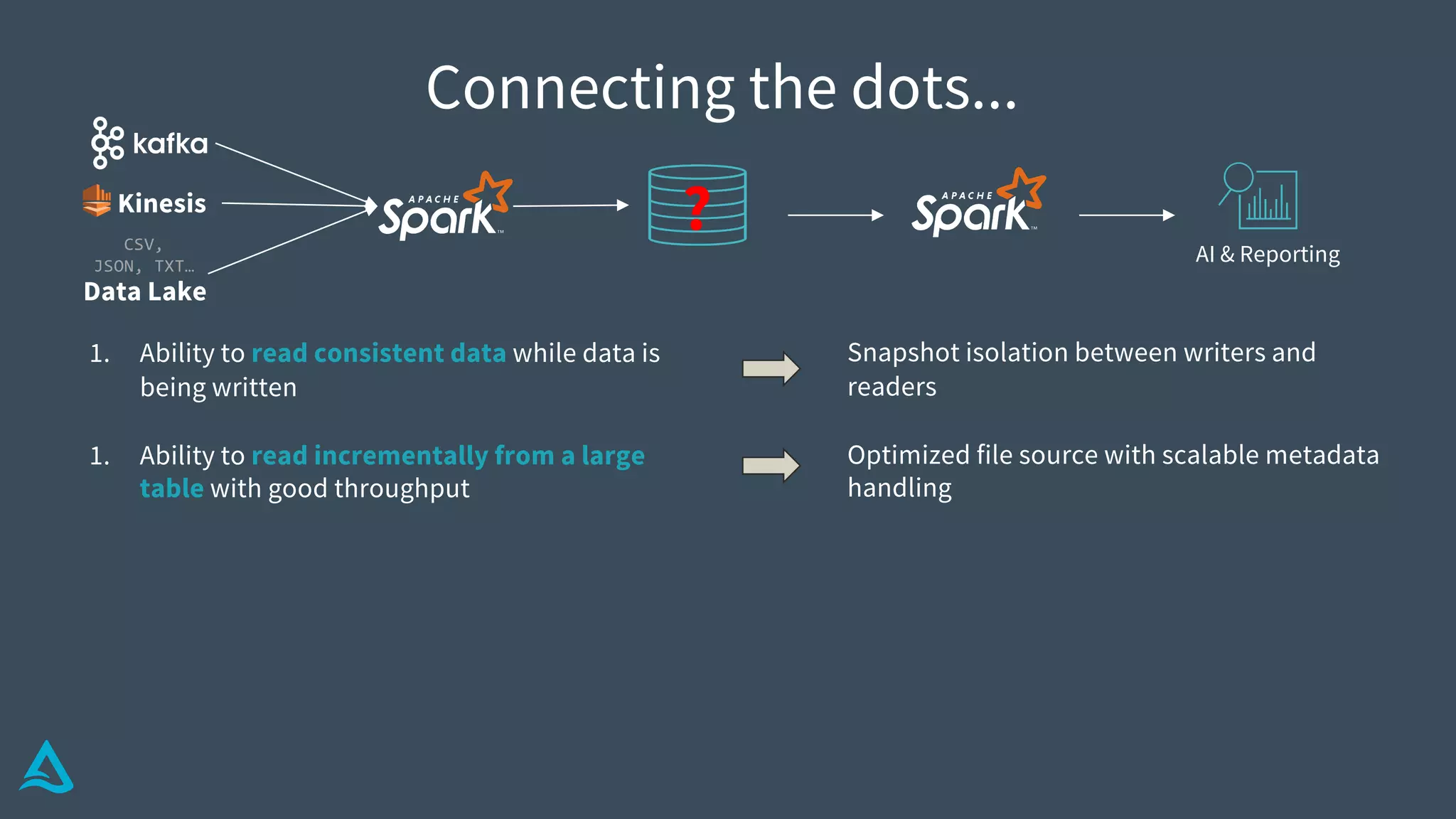
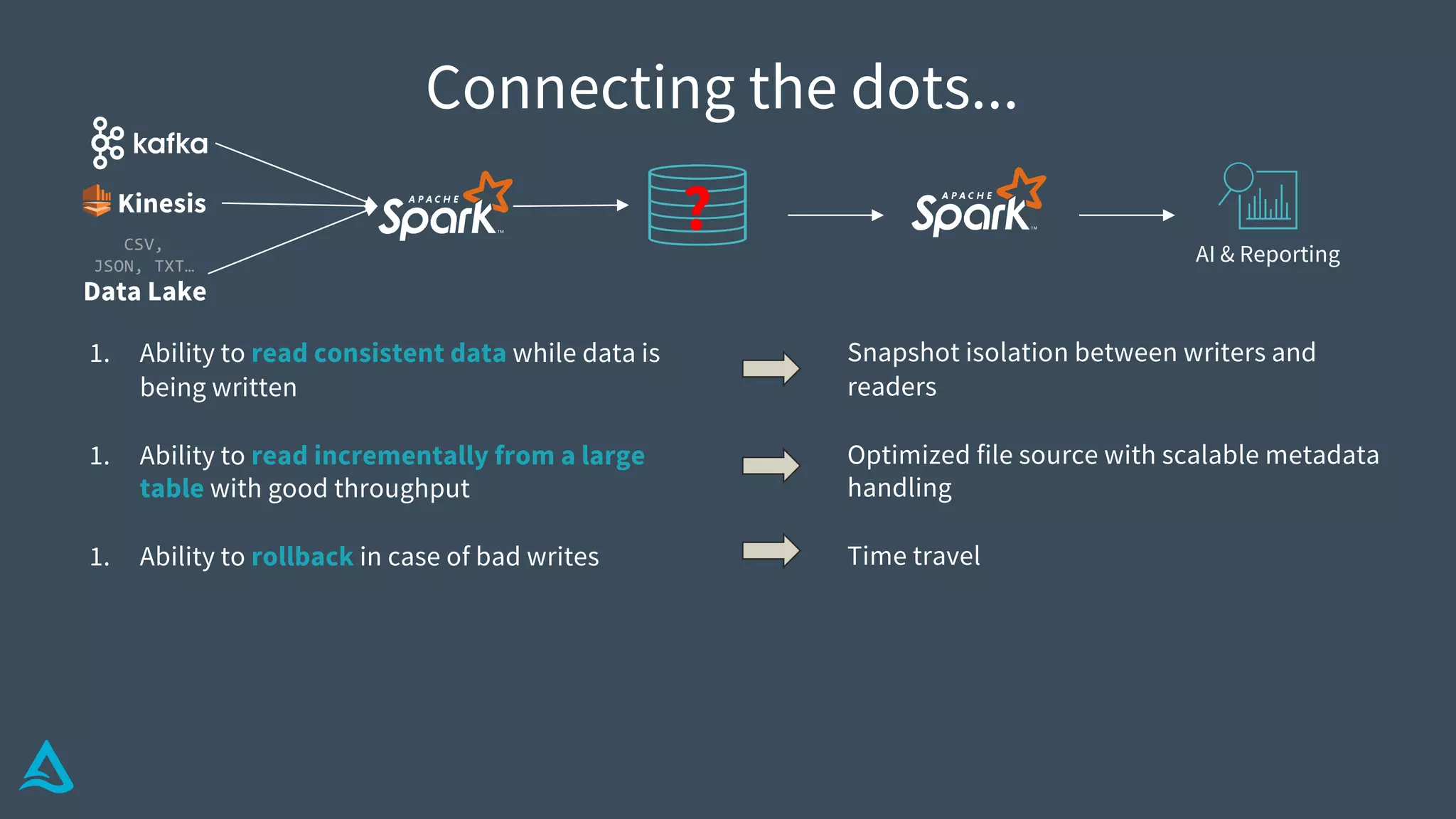
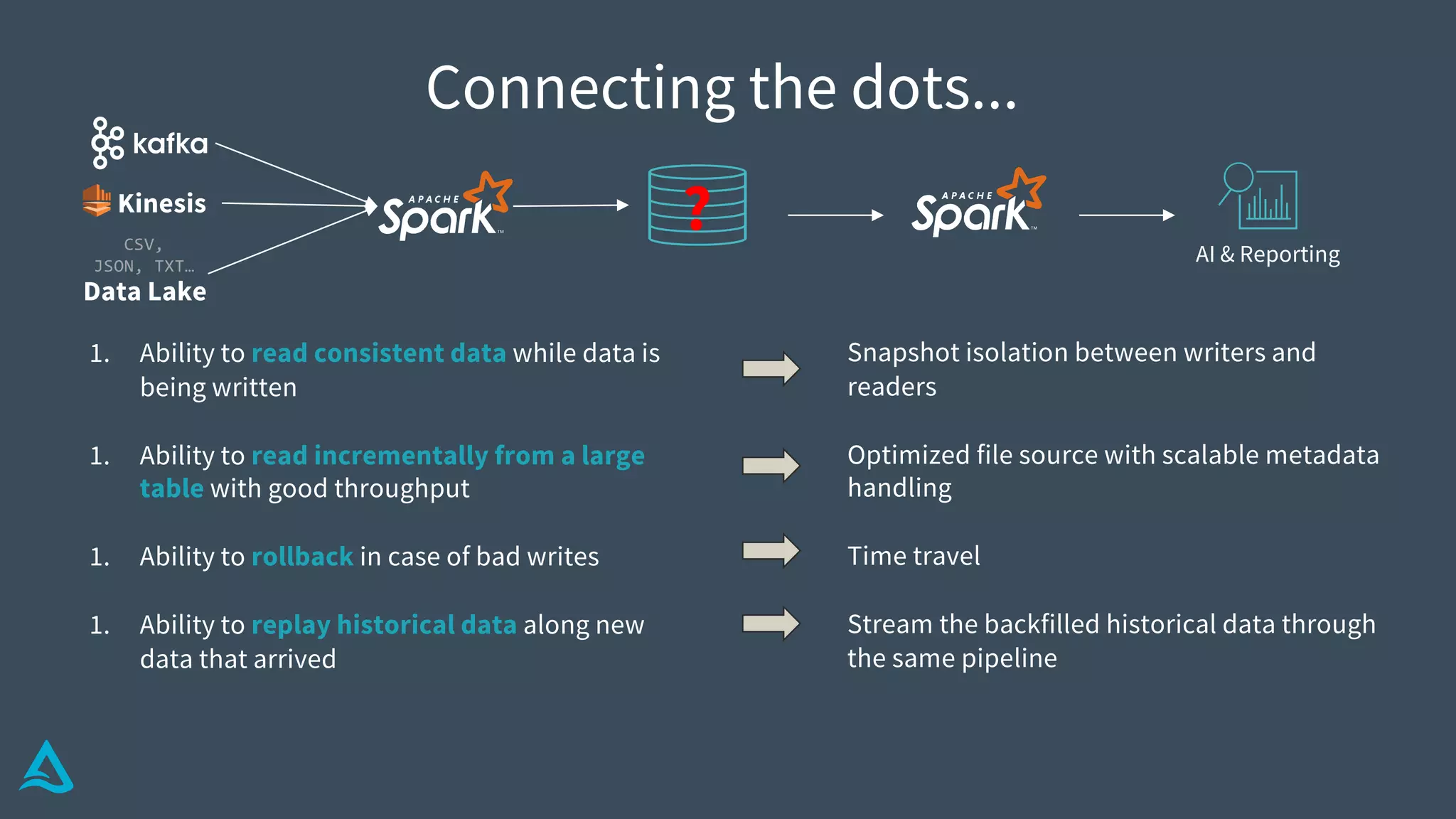
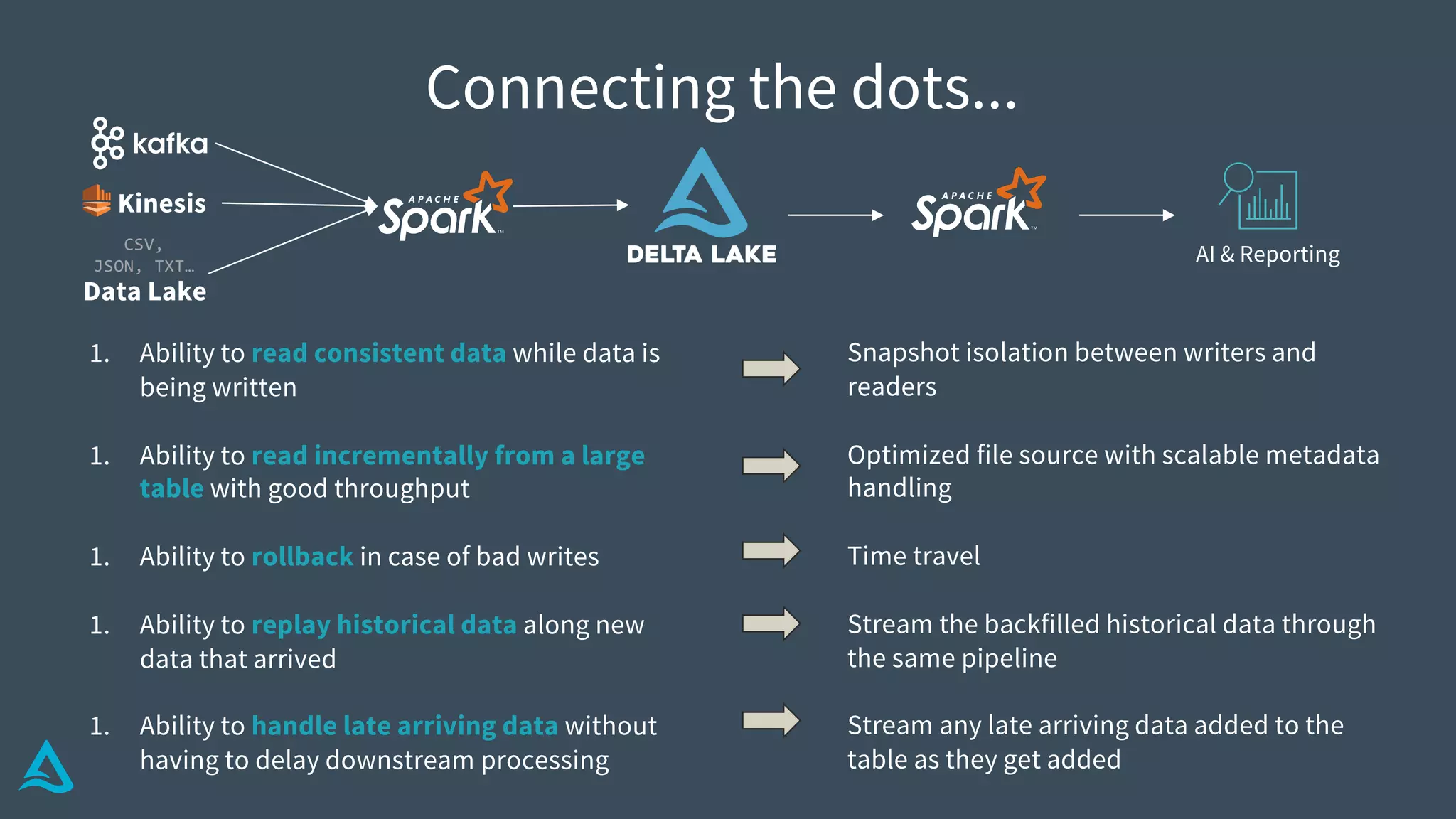
Identifies key requirements such as consistent data reads, incremental processing, and managing late data.
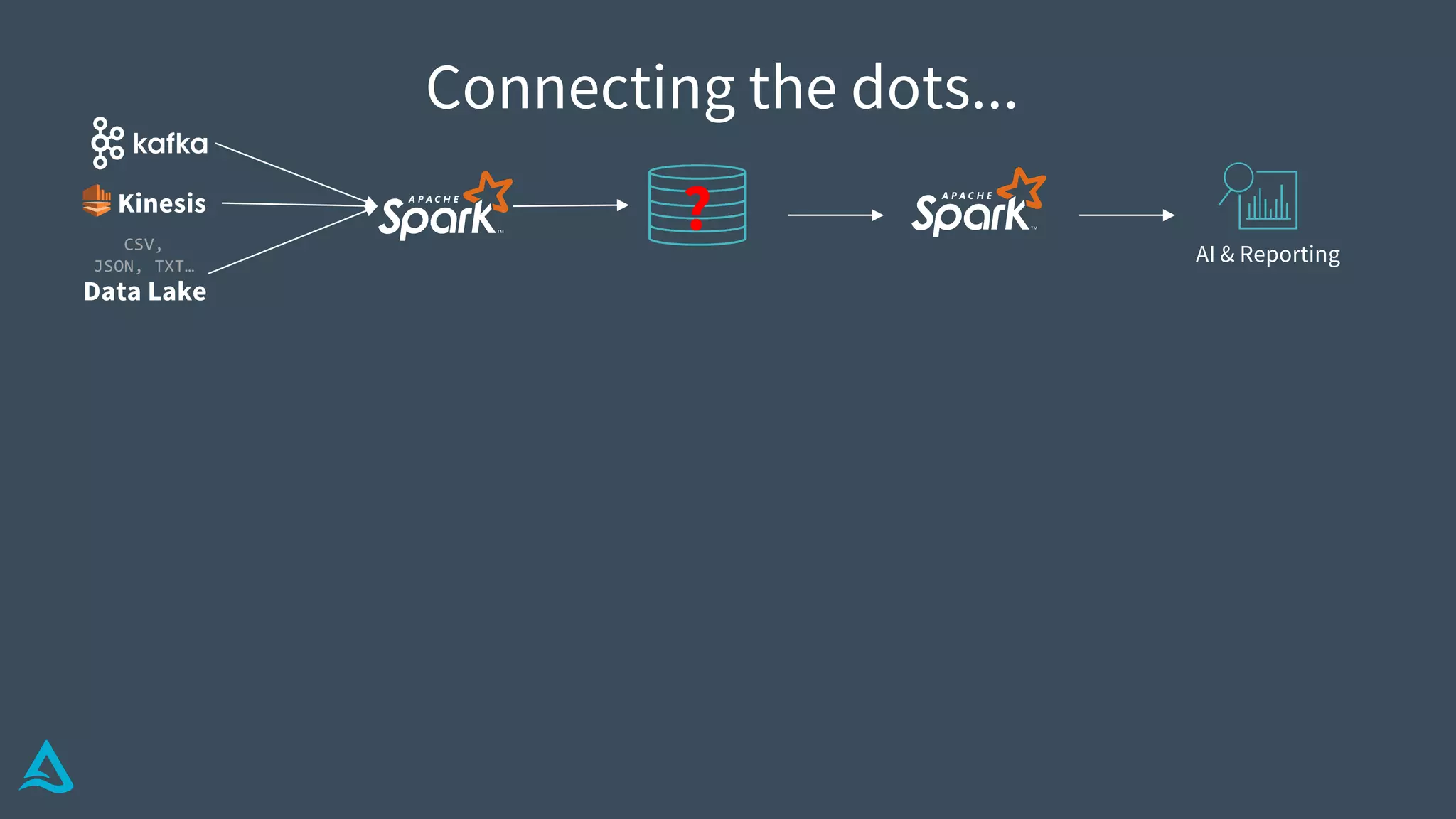
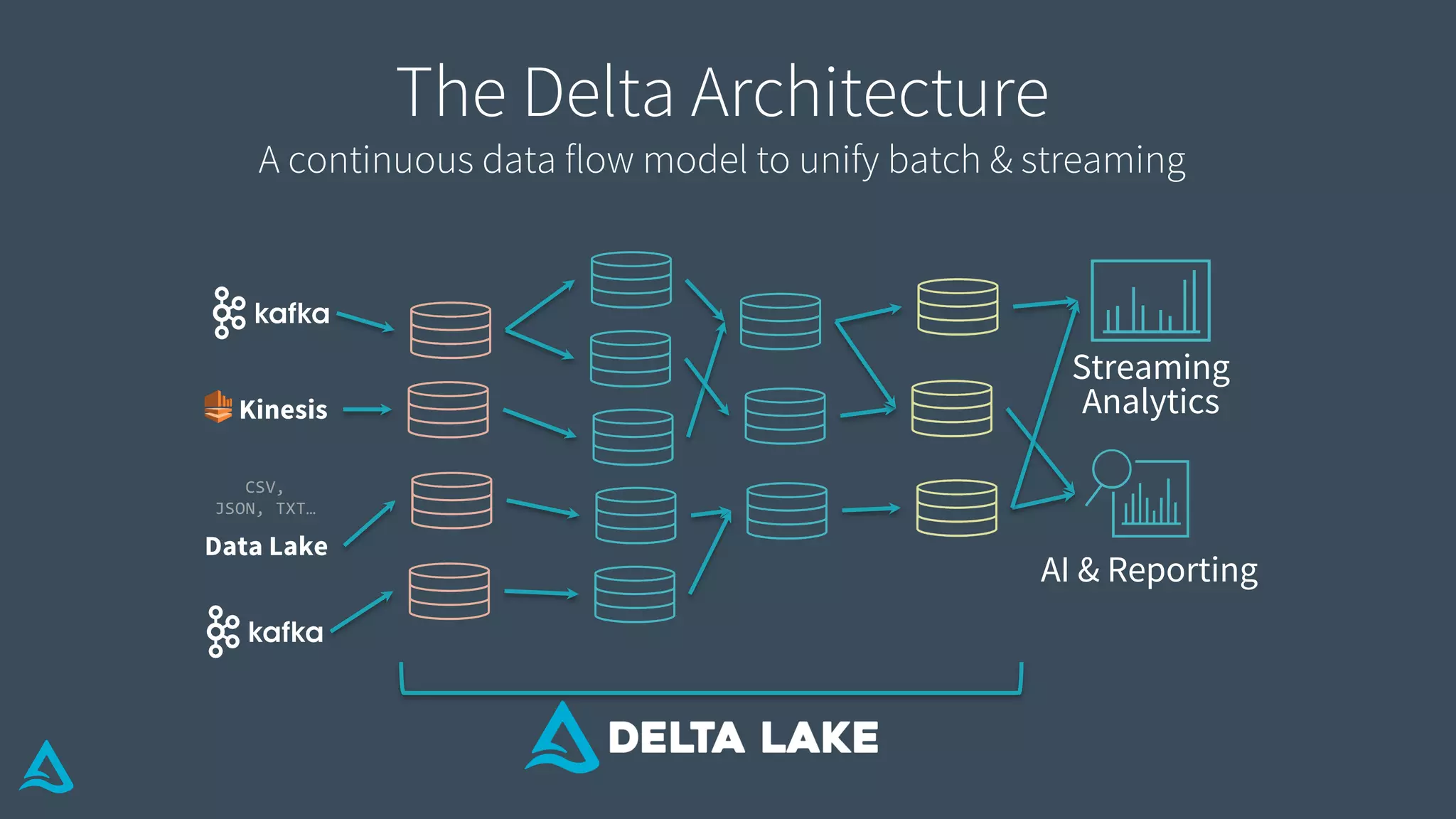
Introduction to Delta Architecture, emphasizing unified batch and streaming model, infinite retention, and scalable compute.
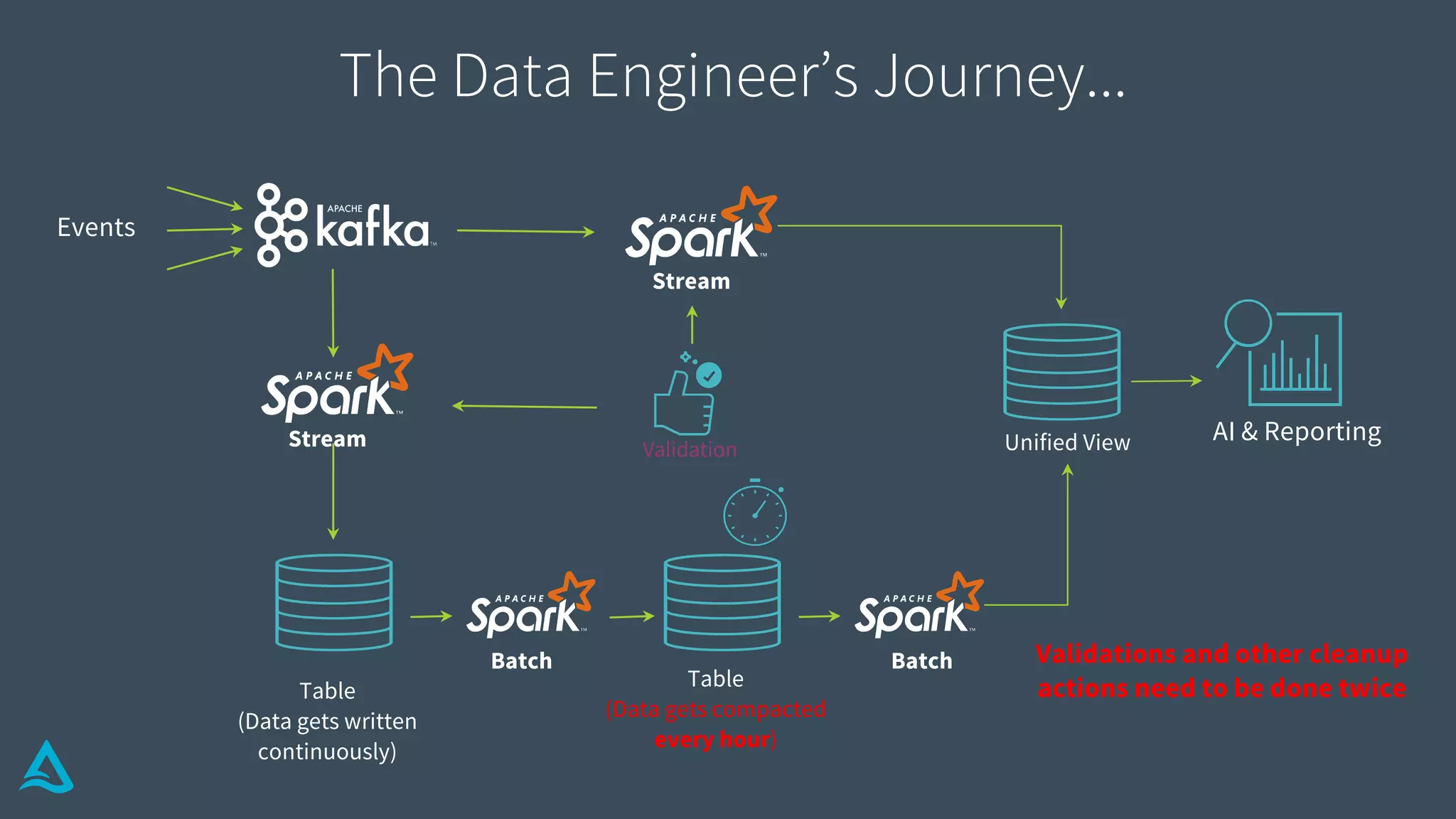
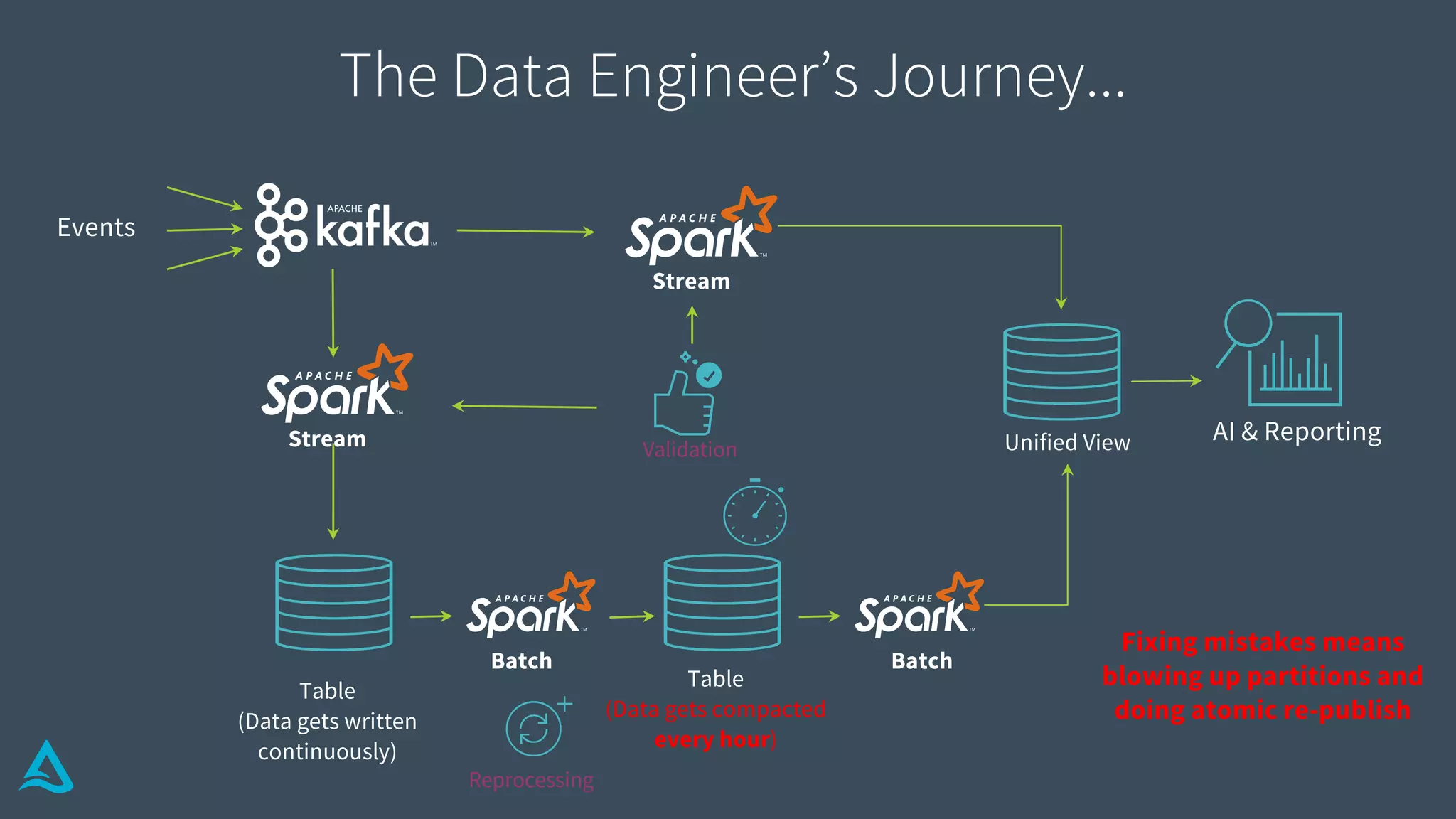
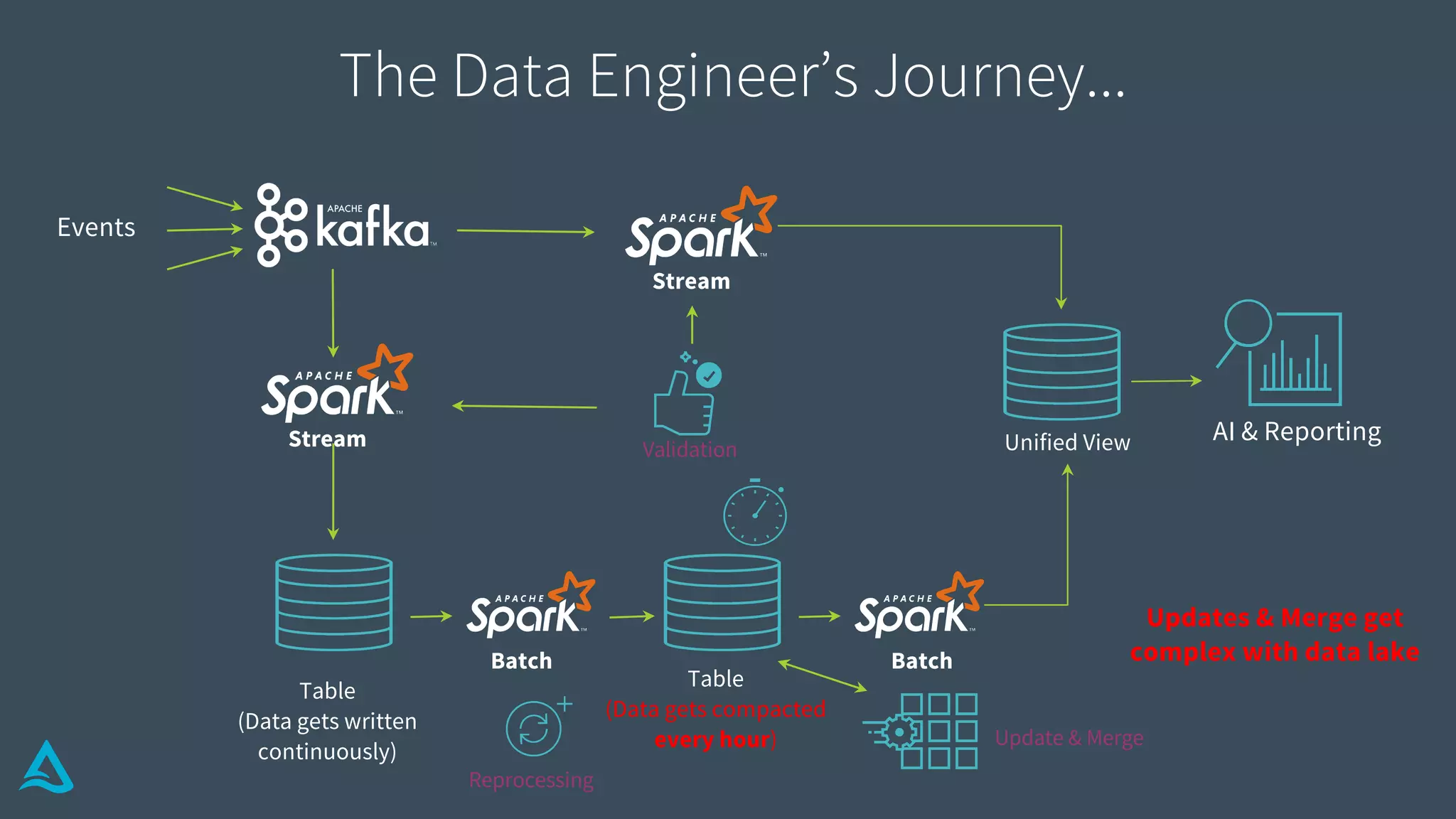
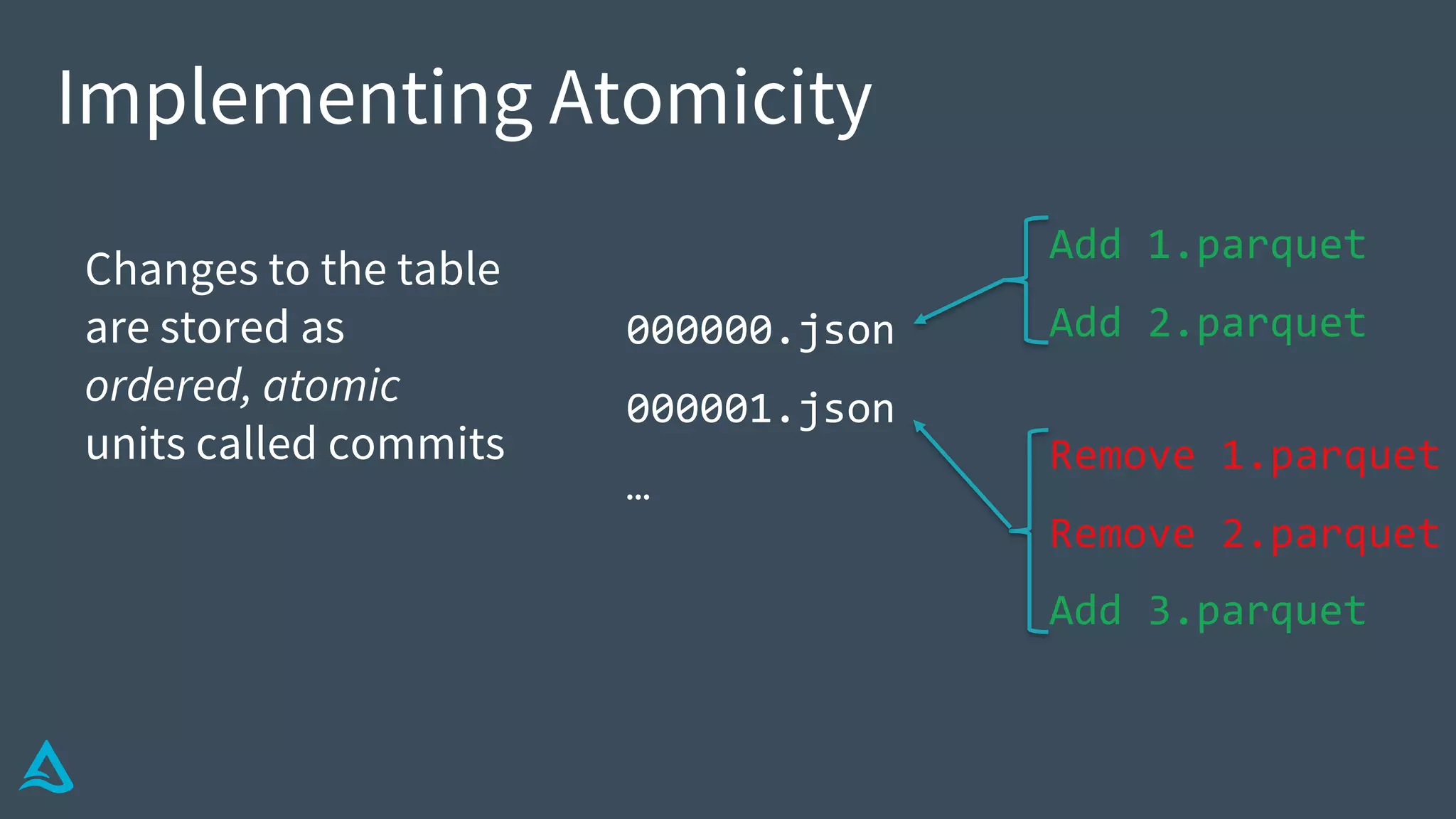
Explains how Delta Lake functions, including its structure, transaction log, metadata handling, and atomicity.
Details methods for handling conflicts optimistically in Delta, optimizing metadata, and ensuring data integrity.
Summarizes Delta Architecture's continuous data flow model for unifying batch and streaming analytics.
Wraps up the presentation with information on accessing a demo and community resources.















![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)





















































![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Dobrica Cosic - Savings by the Second: How Dynamic Pricing an...](https://cdn.slidesharecdn.com/ss_thumbnails/znp09f3smtqz3w2sq6wn-1-dobrica-cosic-savings-by-the-second-how-dynamic-pricing-and-smart-data-are-bu-251208151905-26e6f41e-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Zdravkovic - The road less traveled in District Heating...](https://cdn.slidesharecdn.com/ss_thumbnails/nfaboniqwsz4ucyctnmy-2-milan-zdravkovic-dsc2025-the-road-less-traveled-in-district-heating-operation-251208151905-f56388a5-thumbnail.jpg?width=640&height=640&fit=bounds)




