Download to read offline




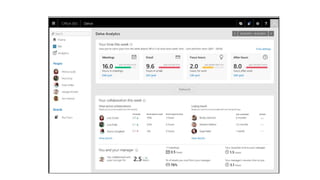
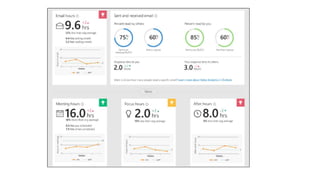

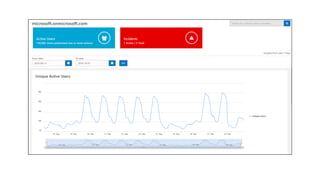


















The document outlines strategies to tackle big data challenges in Office 365 using DataStax Enterprise, highlighting key use cases, architecture, and best practices. It emphasizes the significance of user analytics, proactive service health measures, and efficient data management in the O365 ecosystem. Key technologies discussed include Cassandra, Kafka, and Azure deployment practices, with a focus on performance tuning and automation.

































































