Downloaded 18 times




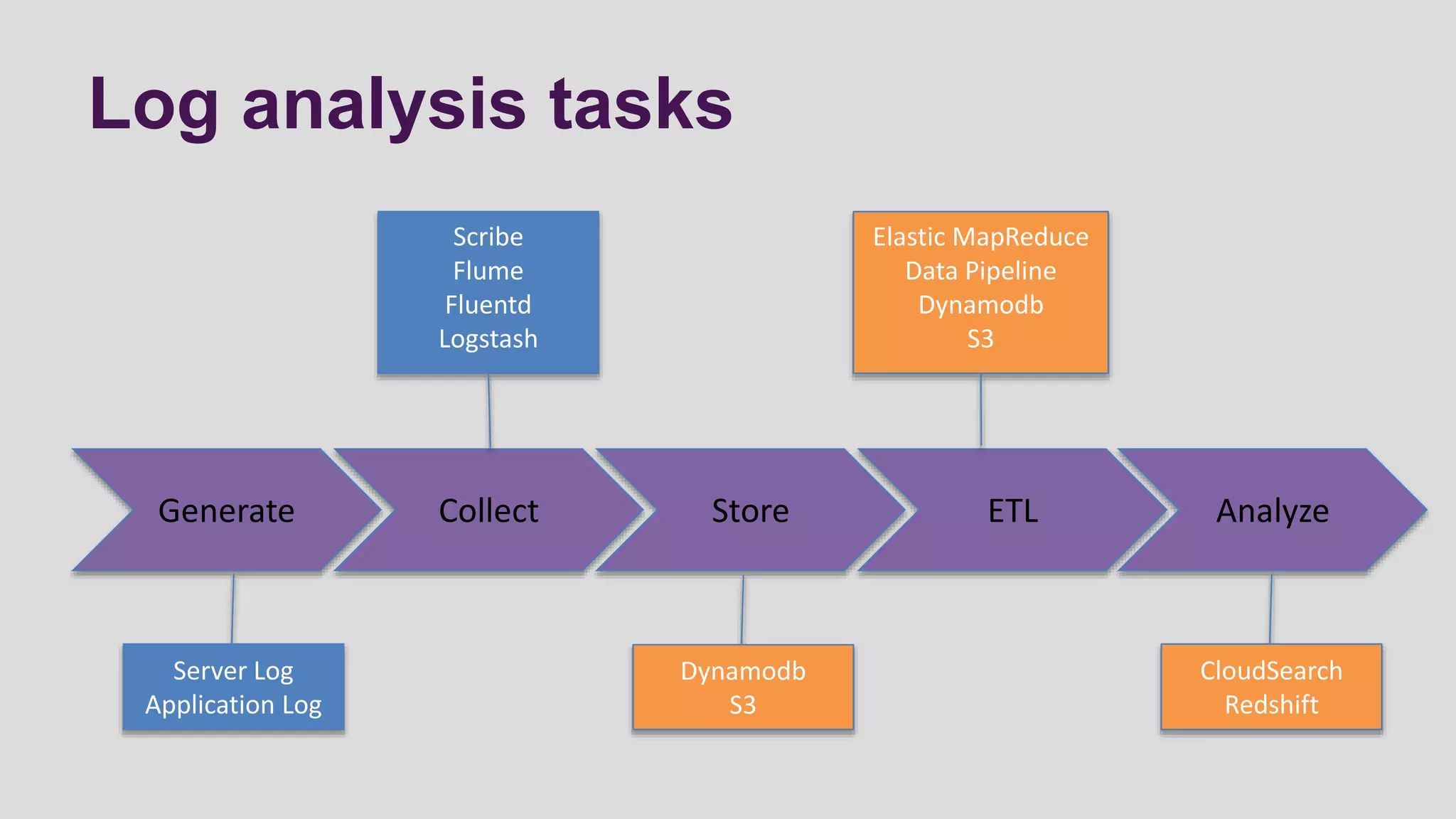



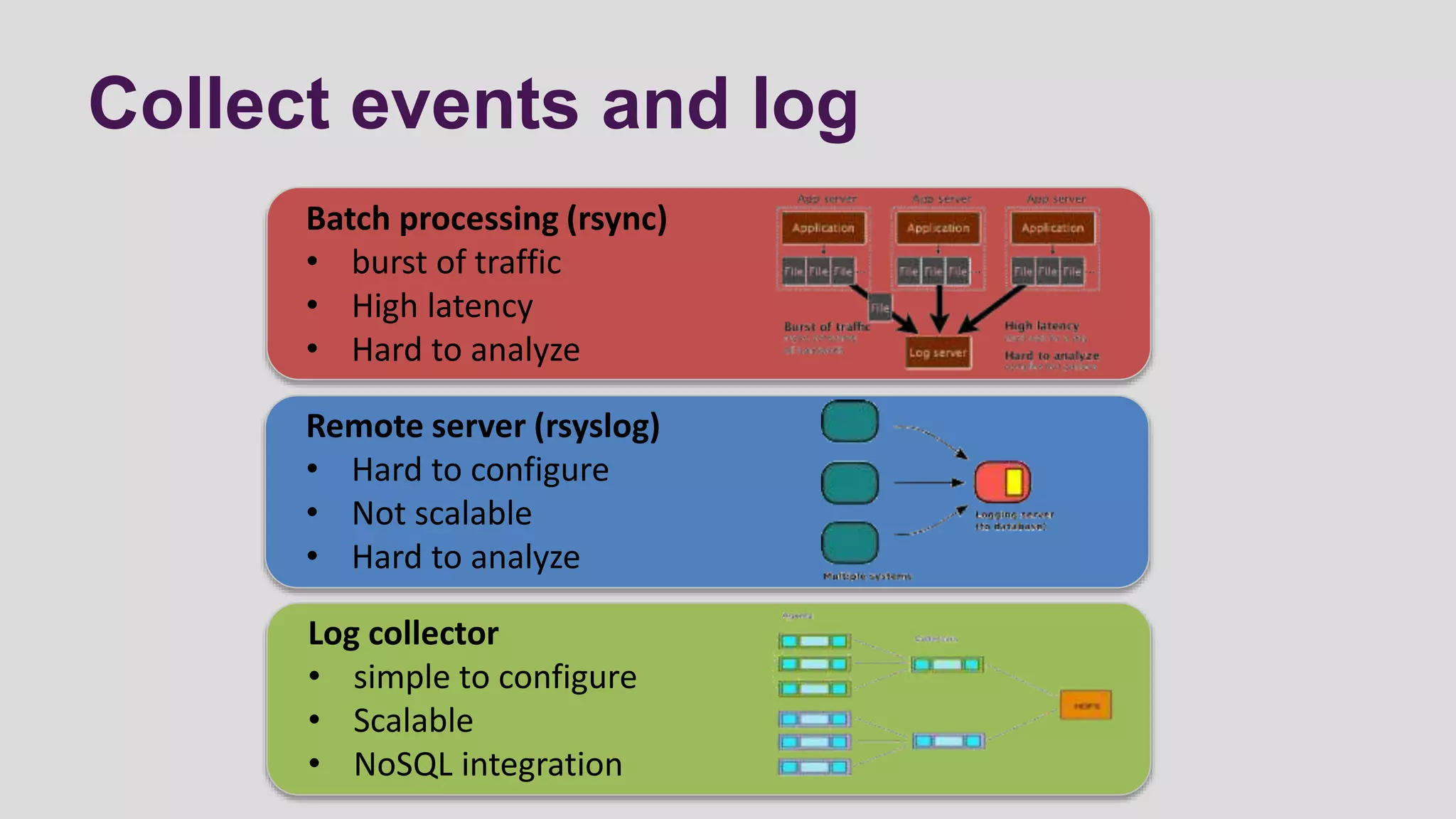


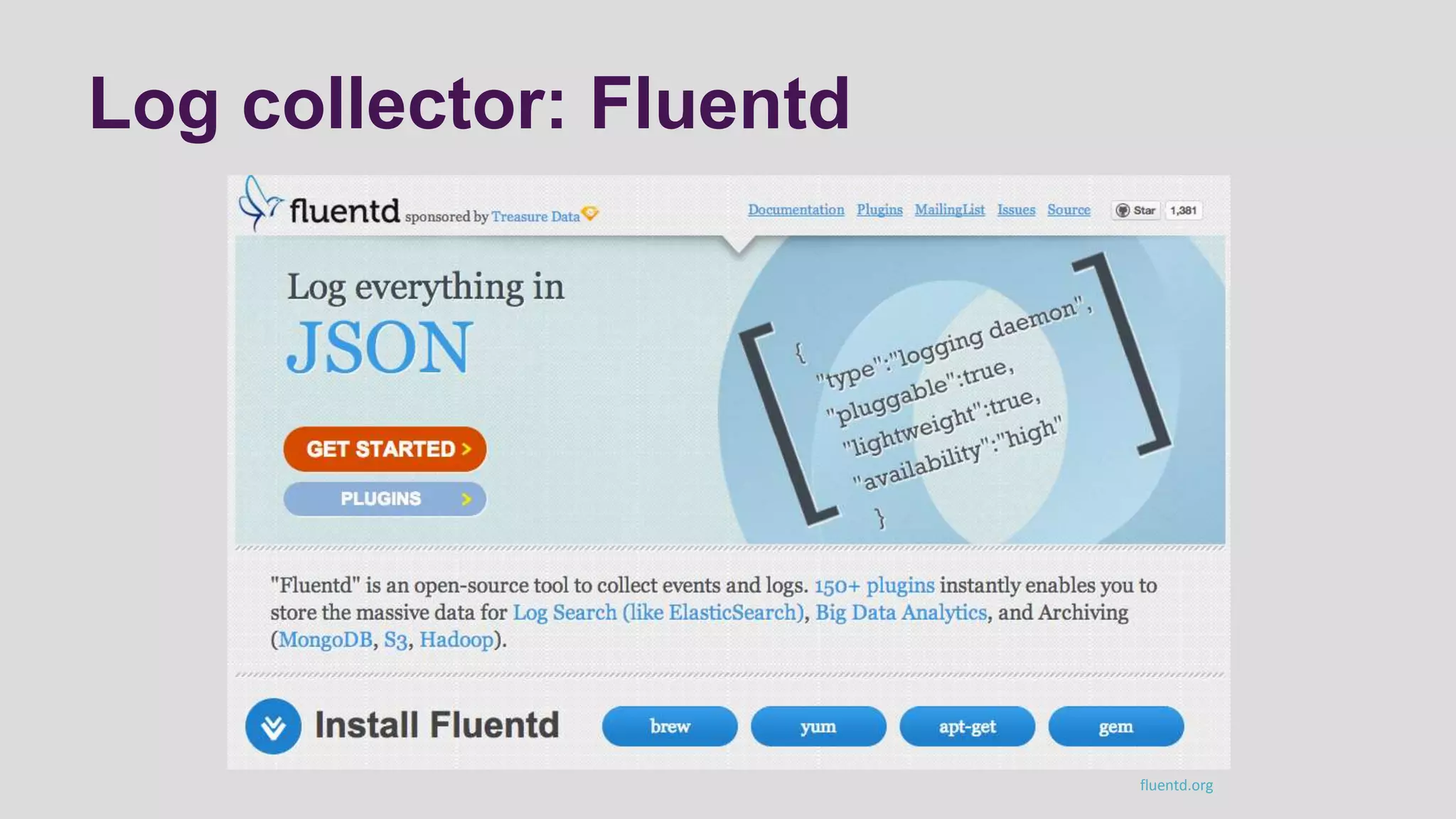
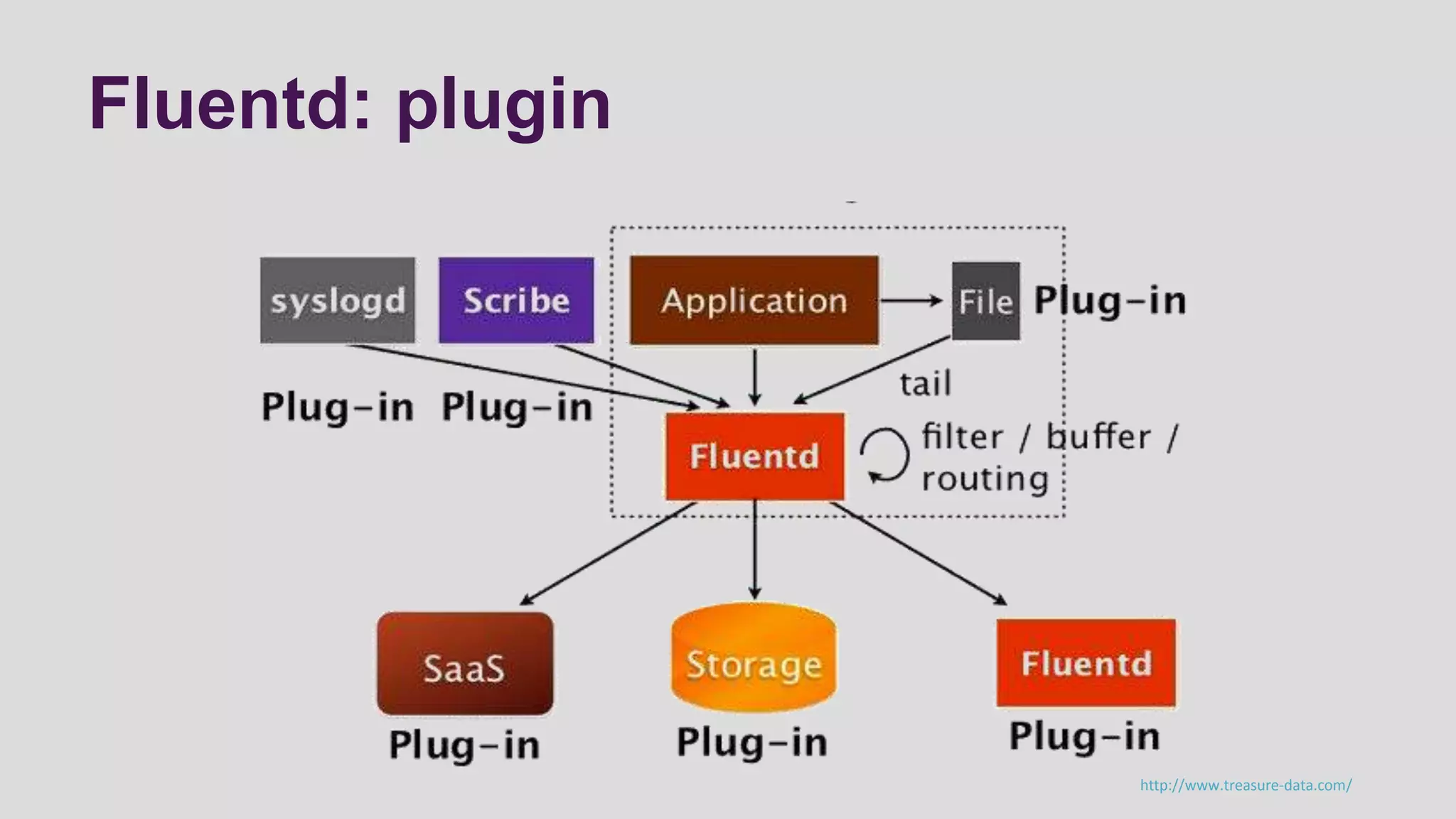

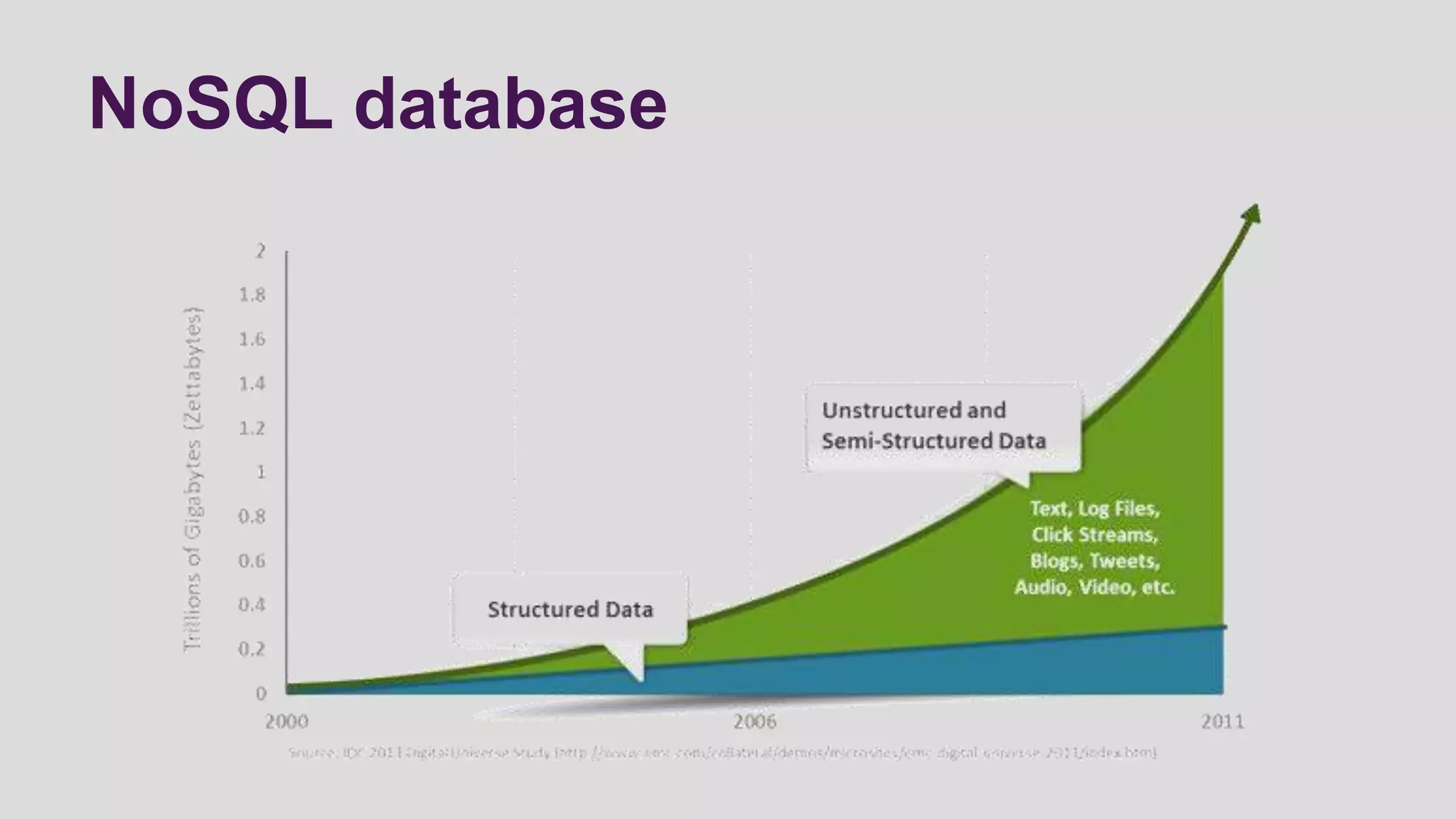

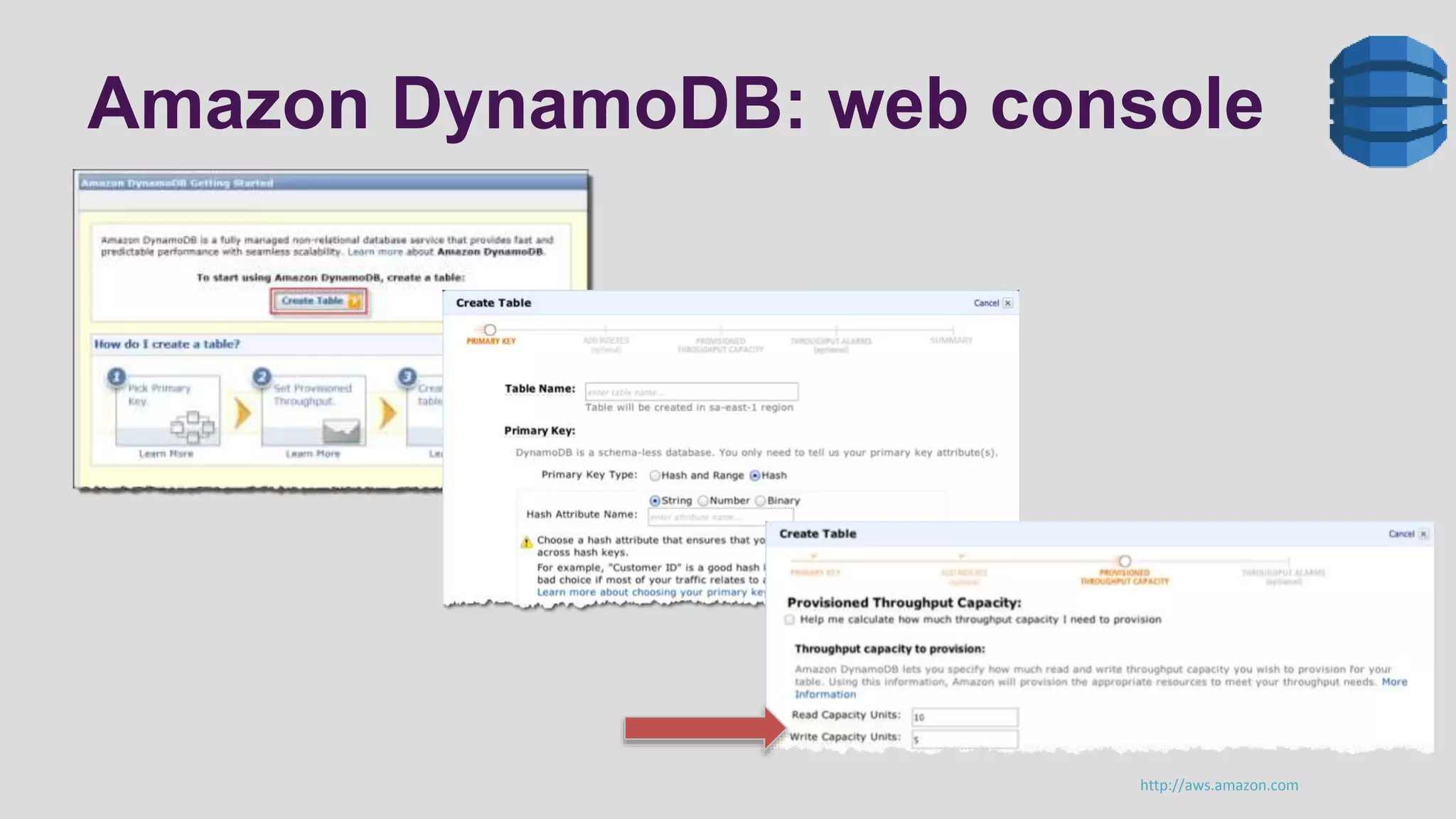




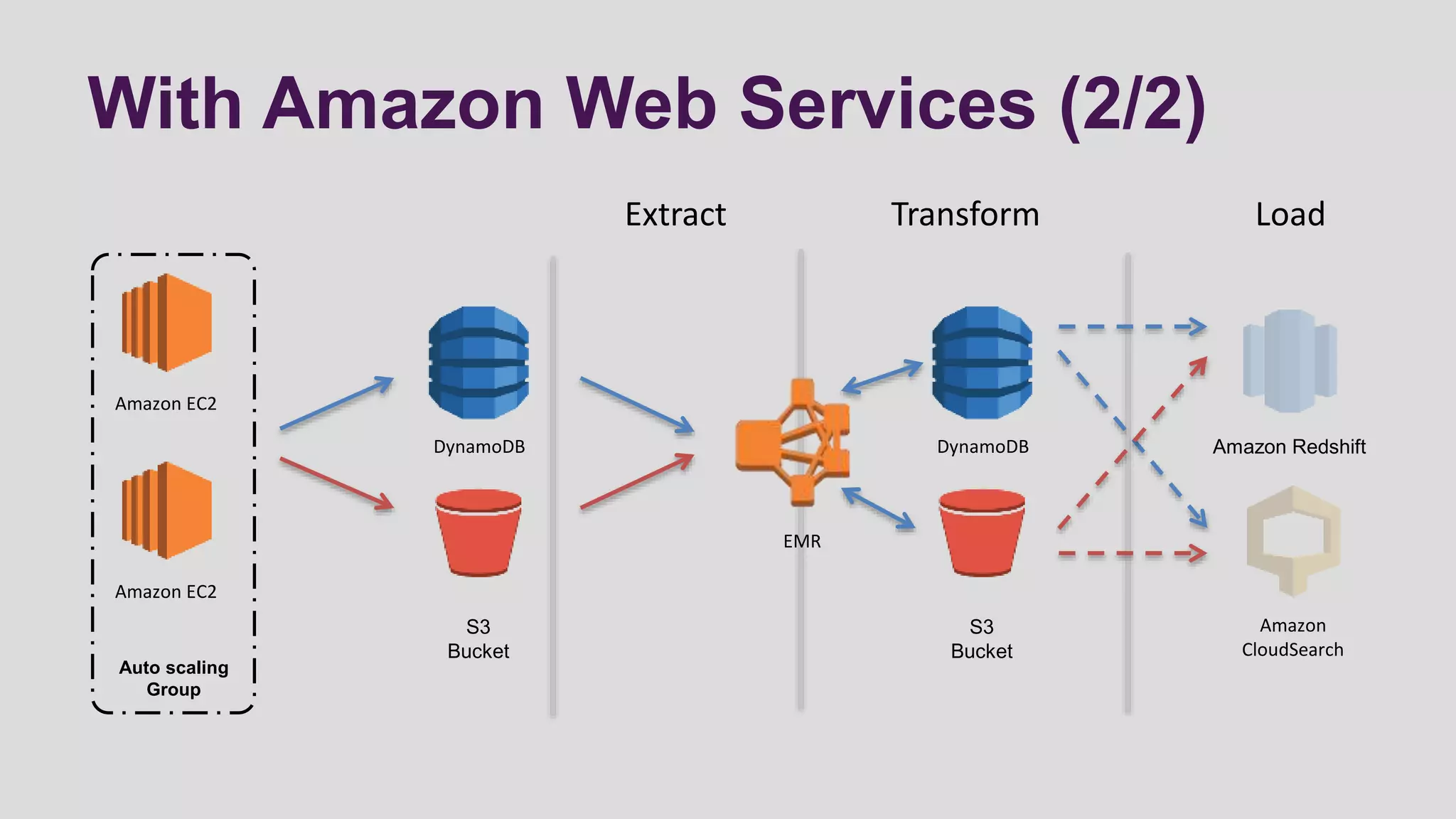



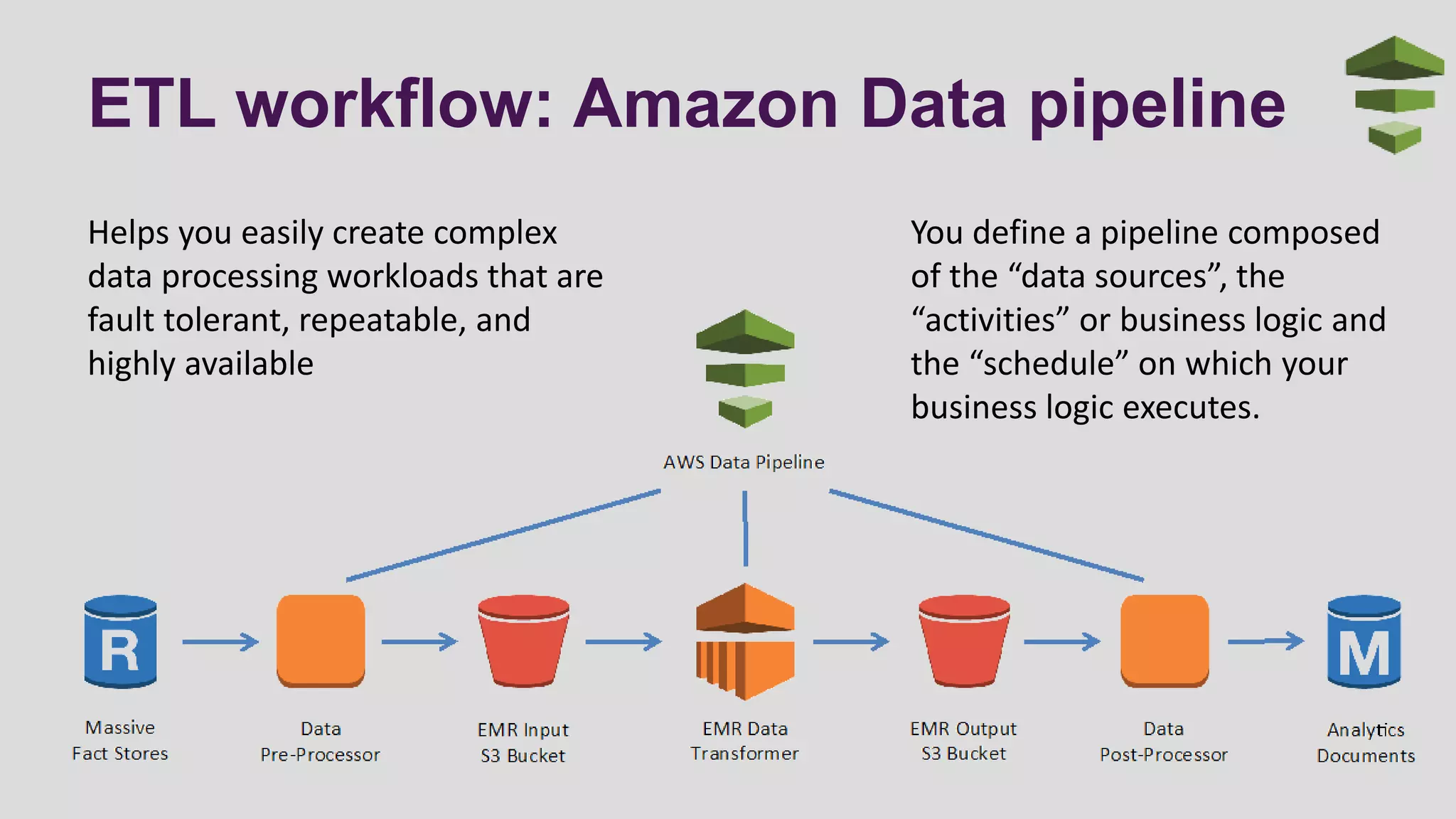



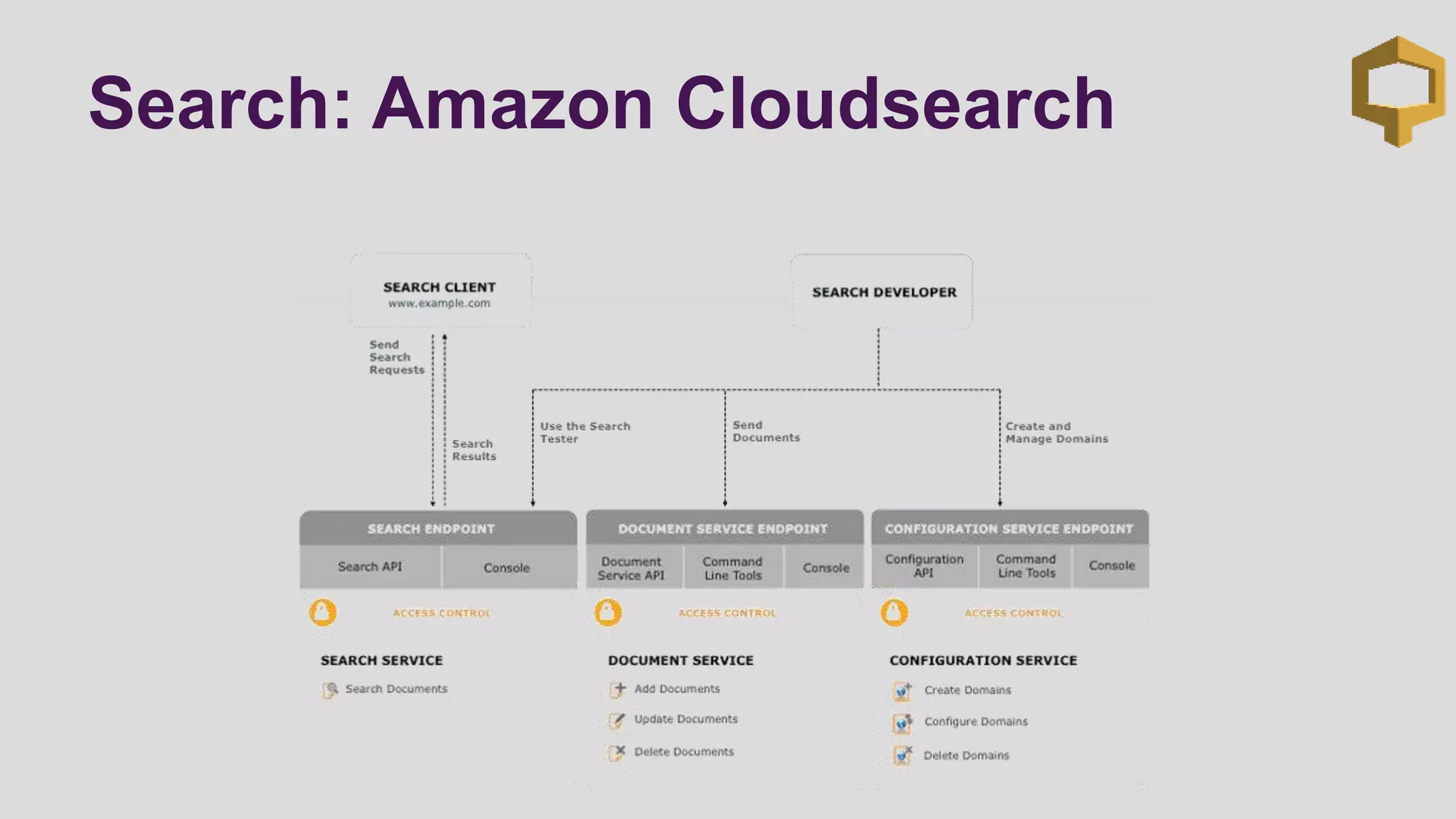





This document discusses logging scenarios using DynamoDB and Elastic MapReduce. It covers collecting log data in real-time using tools like Fluentd and storing it in DynamoDB. It then describes using EMR to perform ETL processes on the data, extracting from DynamoDB, transforming the data across EC2 instances, and loading to S3 or DynamoDB. Finally, it discusses analyzing the data using Redshift for queries or CloudSearch for search capabilities.






















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















