Downloaded 625 times






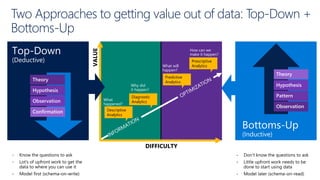
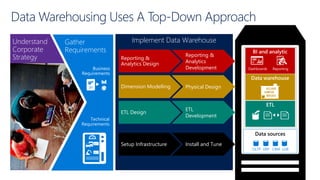
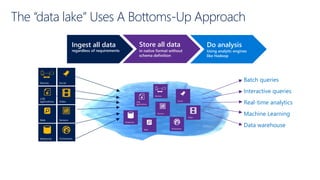
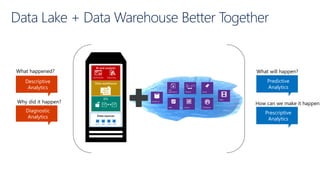


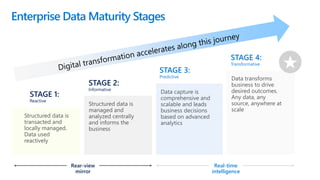

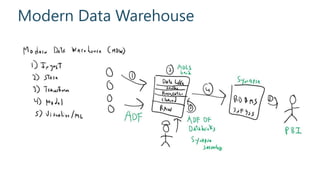

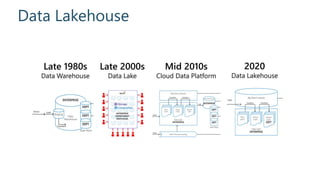
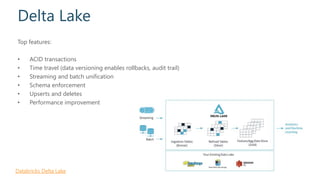


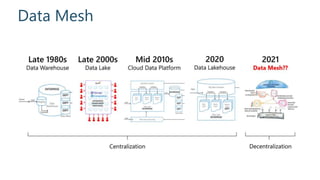
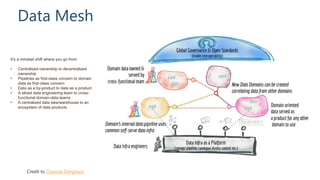


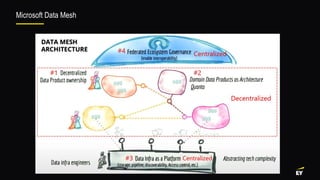
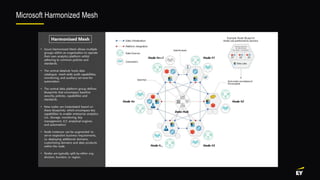



This document discusses various modern data architectures, including data lakes, data warehouses, data lakehouses, and data meshes, highlighting their functions and benefits. It emphasizes the importance of these architectures in managing and analyzing data, as well as the shift from centralized to decentralized data ownership in organizations. The author, James Serra, also addresses common challenges and solutions associated with implementing these data platforms.










![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)












































































