Download as PDF, PPTX











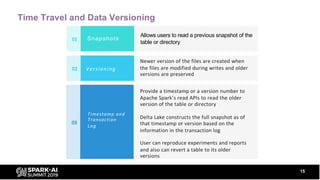


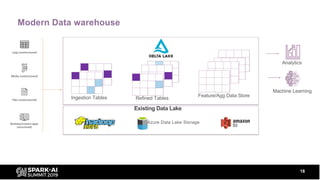




The document discusses Delta Lake, an open-source project from Databricks that enhances data lakes with features like ACID transactions, schema enforcement, and time travel capabilities. It highlights benefits such as improved metadata handling, support for both batch and streaming data, and efficient data processing. The agenda includes insights from data professionals and addresses common challenges faced with traditional data lakes.


















![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)




































































